Sentiment analysis is a topic I cover regularly, for instance, with regard to Harry Plotter, Stranger Things, or Facebook. Usually I stick to the three sentiment dictionaries (i.e., lexicons) included in the tidytext R package (Bing, NRC, and AFINN) but there are many more one could use. Heck, I’ve even tried building one myself using a synonym/antonym network (unsuccessful, though a nice challenge). Two lexicons that did become famous are SentiWordNet, accessible via the lexicon R package, and the Loughran lexicon, designed specifically for the analysis of shareholder reports.
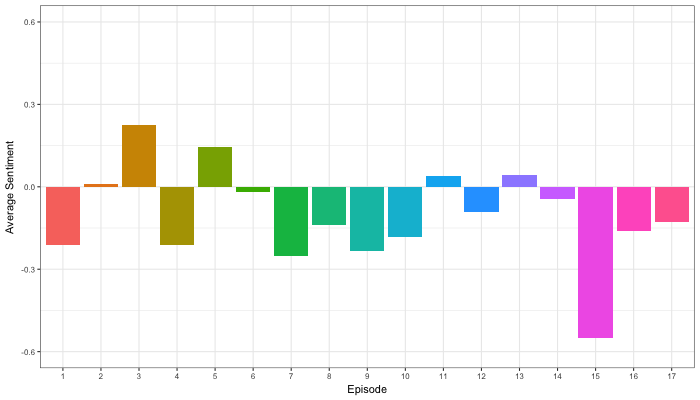
Josh Yazman did the world a favor and compared the quality of the five lexicons mentioned above. He observed their validity in relation to the millions of restaurant reviews in the Yelp dataset. This dataset includes both textual reviews and 1 to 5 star ratings. Here’s a summary of Josh’s findings, including two visualizations (read Josh’s full blog + details here):
- NRC overestimates the positive sentiment.
- AFINN also provides overly positive estimates, but to a lesser extent.
- Loughran seems unreliable altogether (on Yelp data).
- Bing estimates are accurate as long as texts are long enough (e.g., 200+ words).
- SentiWordNet‘s estimates are mostly valid and precise, also on shorter texts, but may include minor outliers.




TL;DR: Sentiment lexicons vary in terms of their quality/performance. If your texts are short (few hundred words) you might be best off using Bing (tidytext). In other cases, opt for SentiWordNet (lexicon), which considers a broader vocabulary. If possible, try to evaluate inaccuracies, outliers, and/or prediction errors via data visualizations.