Hierarchical models I have covered before on this blog. These models are super relevant in practice. For instance, in HR, employee data is always nested within teams which are in turn nested within organizational units. Also in my current field of insurances, claims are always nested within policies, which can in turn be nested within product categories. Data is hierachical, and we need to take that into account when we model it.
Hierarchical models do just that. Interested in how they do this? Have a look at this amazing browser application made in React.js!

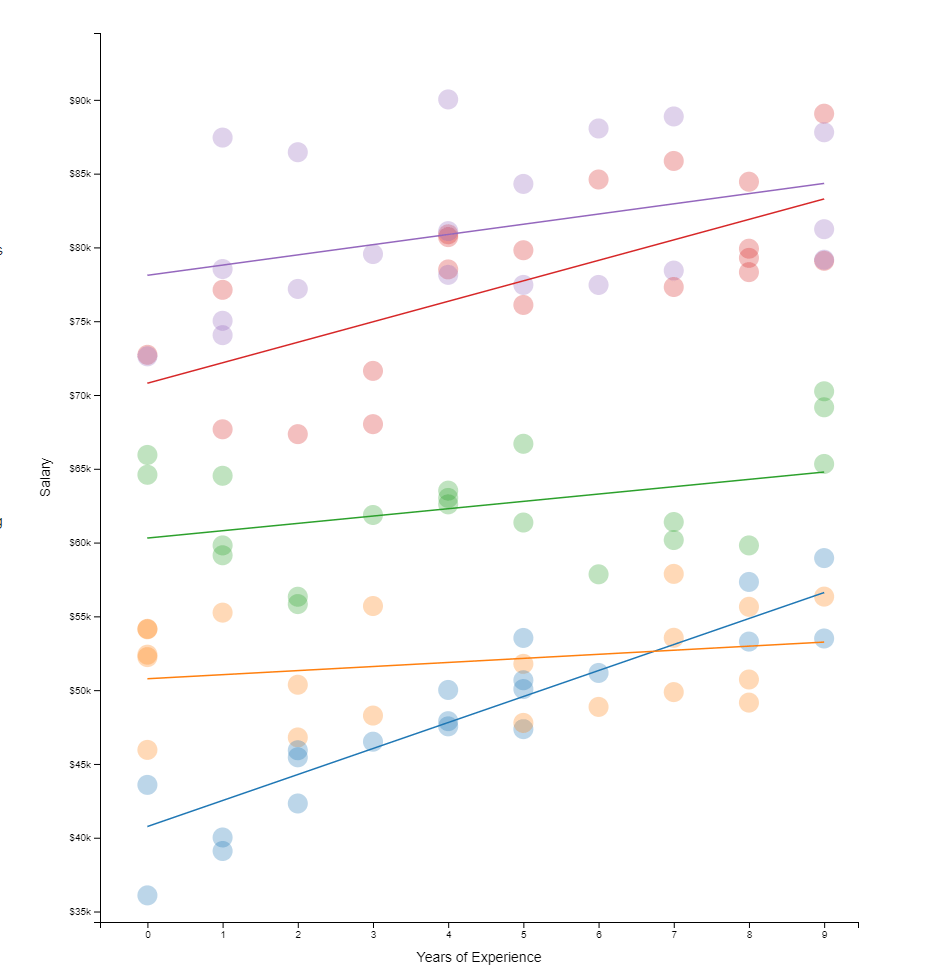
This project was built by Michael Freeman, a faculty member at the University of Washington Information School.
All code for this project is on GitHub, including the script to create the data and run regressions (done in
About this projectR). Feel free to issue a pull request for improvements, and if you like it, share it on Twitter. Layout inspired by Tony Chu.


