Could you guess that you are looking at Amsterdam?
Maybe you spotted the canals?
Bert Spaan colorcoded every building in the Netherlands according to their yaer of construction and visualized the resulting map of nearly 10 million buildings in a JavaScript leaflet webpage.
It resulted in this wonderful map, which my screenshots don’t do any honor. So have a look yourself!
The R programming language has seen the integration of many languages; C, C++, Python, to name a few, can be seamlessly embedded into R so one can conveniently call code written in other languages from the R console. Little known to many, R works just as well with JavaScript—this book delves into the various ways both languages can work together.
John Coene is an well-known R and JavaScript developer. He recently wrote a book on JavaScript for R users, of which he published an online version free to access here.
The book is definitely worth your while if you want to better learn how to develop front-end applications (in JavaScript) on top of your statistical R programs. Think of better understanding, and building, yourself Shiny modules or advanced data visualizations integrated right into webpages.
A nice step on your development path towards becoming a full stack developer by combining R and JavaScript!
Yet most R developers are not familiar with one of web browsers’ core technology: JavaScript. This book aims to remedy that by revealing how much JavaScript can greatly enhance various stages of data science pipelines from the analysis to the communication of results.
Another pearl of a resource on Twitter is this thread by Madison on 10 of fundamentalal concepts of Javascript — and programming in general for that matter.
For your convience, I copied the links below. Just click them to browse to the resource and learn more about the concept
If you're learning JavaScript, you've likely heard people tell you how important it is to learn the fundamentals.
But what are they? And where do you learn them?
Here's a list of JavaScript fundamentals and my favorite free resources for learning them. 👇
Cascading Stylesheets — or CSS — is the first technology you should start learning after HTML. While HTML is used to define the structure and semantics of your content, CSS is used to style it and lay it out. For example, you can use CSS to alter the font, color, size, and spacing of your content, split it into multiple columns, or add animations and other decorative features.
I was personally encoutered CSS in multiple stages of my Data Science career:
When I started using (R) markdown (see here, or here), I could present my data science projects as HTML pages, styled through CSS.
When I got more acustomed to building web applications (e.g., Shiny) on top of my data science models, I had to use CSS to build more beautiful dashboard layouts.
When I was scraping data from Ebay, Amazon, WordPress, and Goodreads, my prior experiences with CSS & HTML helped greatly to identify and interpret the elements when you look under the hood of a webpage (try pressing CTRL + SHIFT + C).
I know others agree with me when I say that the small investment in learning the basics behind HTML & CSS pay off big time:
ok listen……. i finally took a few hours to learn some CSS basics and big time recommend to any and all #rstats people who have always felt absolutely clueless looking up CSS stuff on stack overflow
I read that Mozilla offers some great tutorials for those interested in learning more about “the web”, so here are some quicklinks to their free tutorials:
These days, I am often programming in multiple different languages for my projects. I will do some data generation and machine learning in Python. The data exploration and some quick visualizations I prefer to do in R. And if I’m feeling adventureous, I might add some Processing or JavaScript visualizations.
Obviously, I want to track and store the versions of my programs and the changes between them. I probably don’t have to tell you that git is the tool to do so.
Normally, you’d have a .gitignore file in your project folder, and all files that are not listed (or have patterns listed) in the .gitignore file are backed up online.
However, when you are working in multiple languages simulatenously, it can become a hassle to assure that only the relevant files for each language are committed to Github.
Each language will have their own “by-files”. R projects come with .Rdata, .Rproj, .Rhistory and so on, whereas Python projects generate pycaches and what not. These you don’t want to commit preferably.
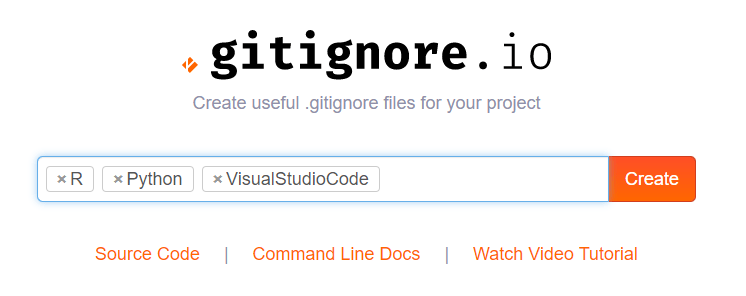
Here you simply enter the operating systems, IDEs, or Programming languages you are working with, and it will generate the appropriate .gitignore contents for you.
Let’s try it out
For my current project, I am working with Python and R in Visual Studio Code. So I enter:
And Voila, I get the perfect .gitignore including all specifics for these programs and languages:
# Created by https://www.gitignore.io/api/r,python,visualstudiocode
# Edit at https://www.gitignore.io/?templates=r,python,visualstudiocode
### Python ###
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
pip-wheel-metadata/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# pyenv
.python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# Mr Developer
.mr.developer.cfg
.project
.pydevproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
### R ###
# History files
.Rhistory
.Rapp.history
# Session Data files
.RData
.RDataTmp
# User-specific files
.Ruserdata
# Example code in package build process
*-Ex.R
# Output files from R CMD build
/*.tar.gz
# Output files from R CMD check
/*.Rcheck/
# RStudio files
.Rproj.user/
# produced vignettes
vignettes/*.html
vignettes/*.pdf
# OAuth2 token, see https://github.com/hadley/httr/releases/tag/v0.3
.httr-oauth
# knitr and R markdown default cache directories
*_cache/
/cache/
# Temporary files created by R markdown
*.utf8.md
*.knit.md
### R.Bookdown Stack ###
# R package: bookdown caching files
/*_files/
### VisualStudioCode ###
.vscode/*
!.vscode/settings.json
!.vscode/tasks.json
!.vscode/launch.json
!.vscode/extensions.json
### VisualStudioCode Patch ###
# Ignore all local history of files
.history
# End of https://www.gitignore.io/api/r,python,visualstudiocode