In Glad You Asked, Vox dives deep into timely questions around the impact of systemic racism on our communities and in our daily lives.
In this video, they look into the role of tech in societal discrimination. People assume that tech and data are neutral, and we have turned to tech as a way to replace biased human decision-making. But as data-driven systems become a bigger and bigger part of our lives, we see more and more cases where they fail. And, more importantly, that they don’t fail on everyone equally.
Why do we think tech is neutral? How do algorithms become biased? And how can we fix these algorithms before they cause harm? Find out in this mini-doc:
Vincent Warmerdam shared this Youtube video which I thoroughly enjoyed watched. It’s about Saul Pwanson, a software engineer whose hobby project got a little out of hand.
In 2016, Saul Pwanson designed a plain-text file format for crossword puzzle data, and then spent a couple of months building a micro-data-pipeline, scraping tens of thousands of crosswords from various sources.
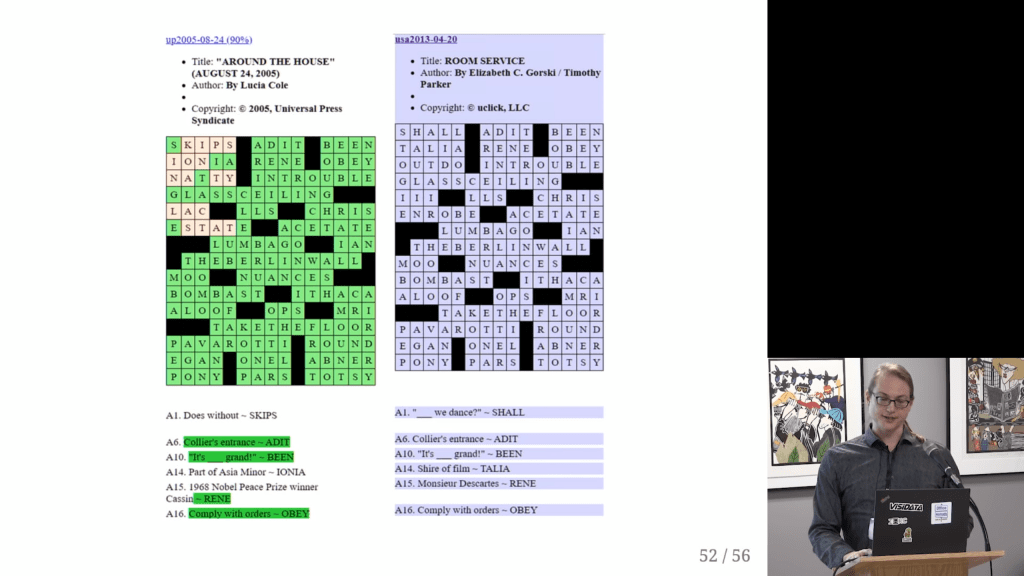
After putting all these crosswords in a simple uniform format, Saul used some simple command line commands to check for common patterns and irregularities.
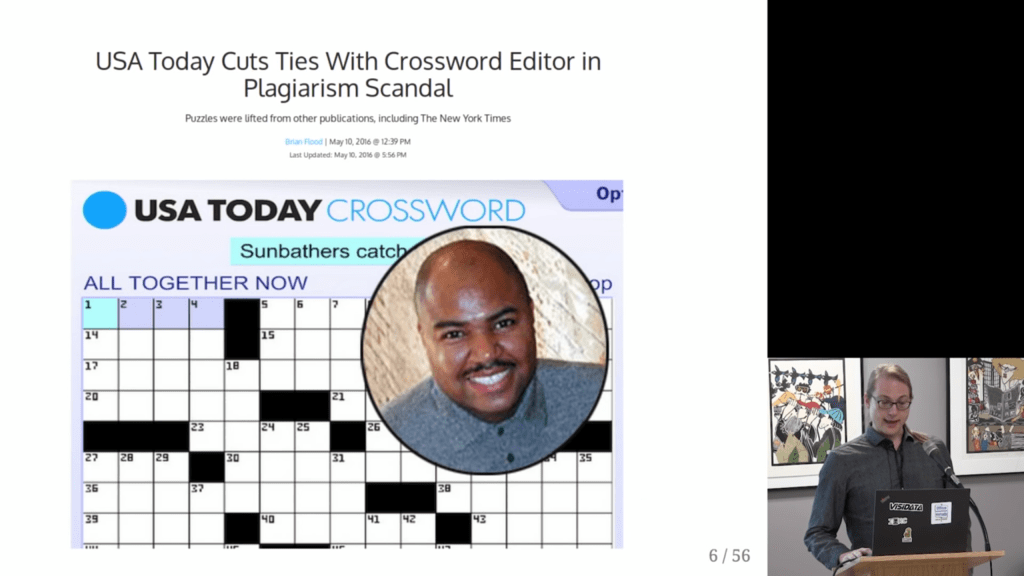
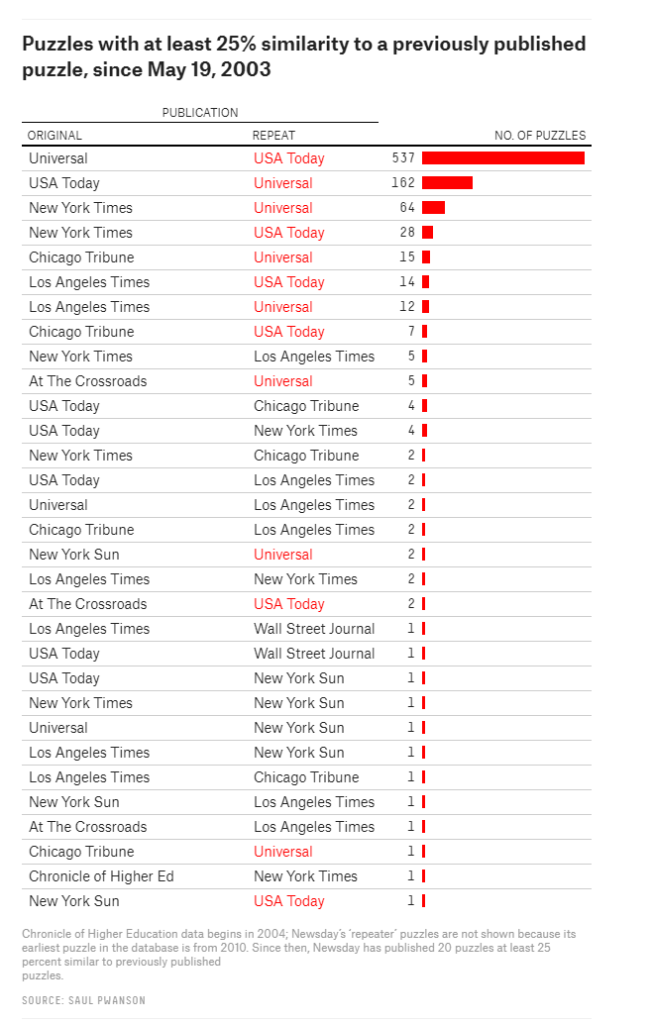
Surprisingly enough, after visualizing the results, Saul discovered egregious plagiarism by a major crossword editor that had gone on for years.
I thoroughly enjoyed watching this talk on Youtube.
Saul covers the file format, data pipeline, and the design choices that aided rapid exploration; the evidence for the scandal, from the initial anomalies to the final damning visualization; and what it’s like for a data project to get 15 minutes of fame.
I tried to localize the dataset online, but it seems Saul’s website has since gone offline. If you do happen to find it, please do share it in the comments!
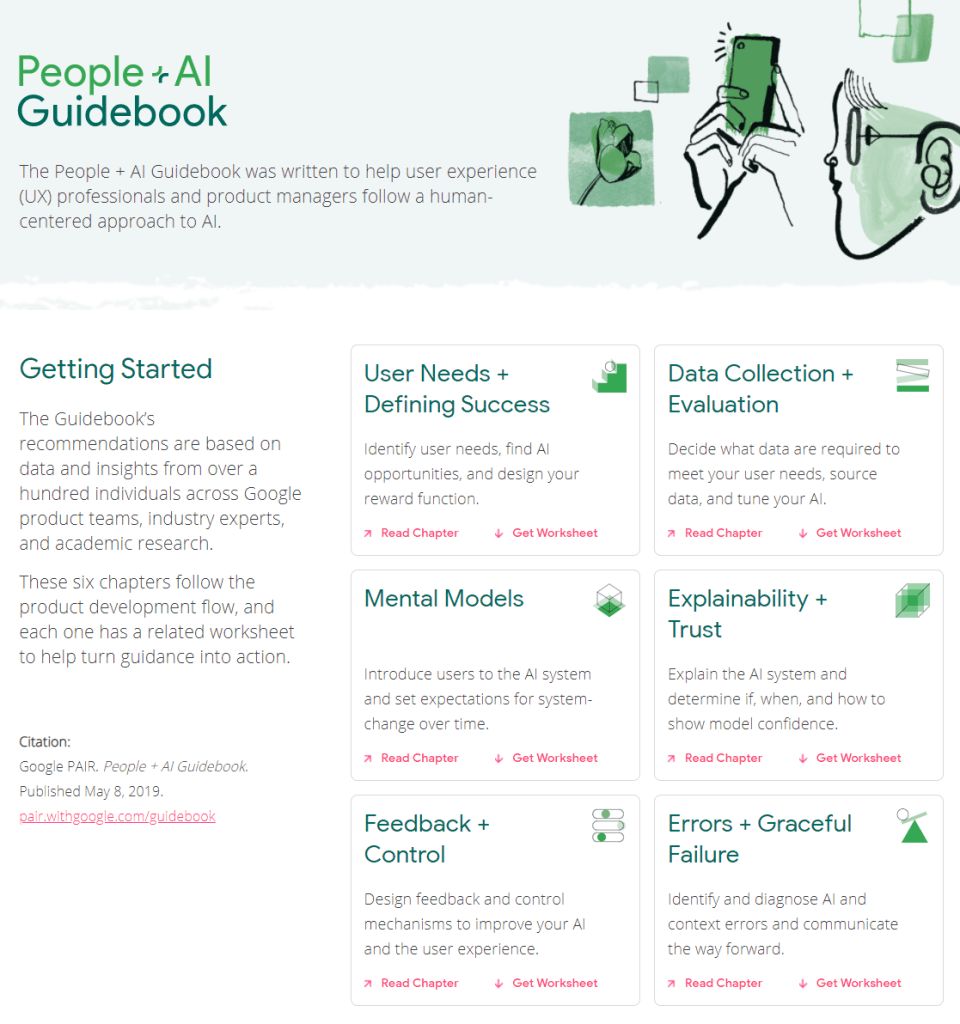
The People + AI Guidebook was written to help user experience (UX) professionals and product managers follow a human-centered approach to AI.
The Guidebook’s recommendations are based on data and insights from over a hundred individuals across Google product teams, industry experts, and academic research.
These six chapters follow the product development flow, and each one has a related worksheet to help turn guidance into action.
The People & AI guidebook is one of the products of the major PAIR project team (People & AI Research).
Here are the direct links to the six guidebook chapters:
These days, I am often programming in multiple different languages for my projects. I will do some data generation and machine learning in Python. The data exploration and some quick visualizations I prefer to do in R. And if I’m feeling adventureous, I might add some Processing or JavaScript visualizations.
Obviously, I want to track and store the versions of my programs and the changes between them. I probably don’t have to tell you that git is the tool to do so.
Normally, you’d have a .gitignore file in your project folder, and all files that are not listed (or have patterns listed) in the .gitignore file are backed up online.
However, when you are working in multiple languages simulatenously, it can become a hassle to assure that only the relevant files for each language are committed to Github.
Each language will have their own “by-files”. R projects come with .Rdata, .Rproj, .Rhistory and so on, whereas Python projects generate pycaches and what not. These you don’t want to commit preferably.
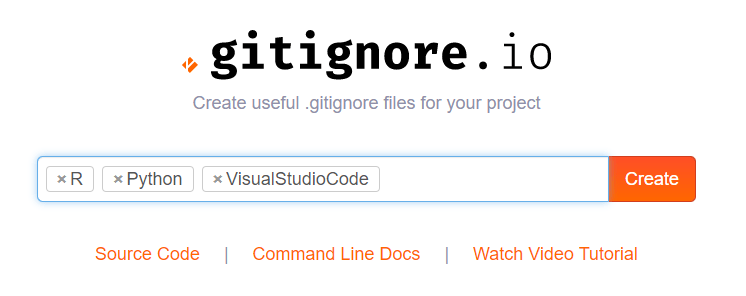
Here you simply enter the operating systems, IDEs, or Programming languages you are working with, and it will generate the appropriate .gitignore contents for you.
Let’s try it out
For my current project, I am working with Python and R in Visual Studio Code. So I enter:
And Voila, I get the perfect .gitignore including all specifics for these programs and languages:
# Created by https://www.gitignore.io/api/r,python,visualstudiocode
# Edit at https://www.gitignore.io/?templates=r,python,visualstudiocode
### Python ###
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
pip-wheel-metadata/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# pyenv
.python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# Mr Developer
.mr.developer.cfg
.project
.pydevproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
### R ###
# History files
.Rhistory
.Rapp.history
# Session Data files
.RData
.RDataTmp
# User-specific files
.Ruserdata
# Example code in package build process
*-Ex.R
# Output files from R CMD build
/*.tar.gz
# Output files from R CMD check
/*.Rcheck/
# RStudio files
.Rproj.user/
# produced vignettes
vignettes/*.html
vignettes/*.pdf
# OAuth2 token, see https://github.com/hadley/httr/releases/tag/v0.3
.httr-oauth
# knitr and R markdown default cache directories
*_cache/
/cache/
# Temporary files created by R markdown
*.utf8.md
*.knit.md
### R.Bookdown Stack ###
# R package: bookdown caching files
/*_files/
### VisualStudioCode ###
.vscode/*
!.vscode/settings.json
!.vscode/tasks.json
!.vscode/launch.json
!.vscode/extensions.json
### VisualStudioCode Patch ###
# Ignore all local history of files
.history
# End of https://www.gitignore.io/api/r,python,visualstudiocode
If you are looking for a project to build a bot or AI application, look no further.
Enter the stage, PyBoy, a Nintendo Game Boy (DMG-01 [1989]) written in Python 2.7. The implementation runs in almost pure Python, but with dependencies for drawing graphics and getting user interactions through SDL2 and NumPy.
PyBoy is great for your AI robot projects as it is loadable as an object in Python. This means, it can be initialized from another script, and be controlled and probed by the script. You can even use multiple emulators at the same time, just instantiate the class multiple times.
The imagery suggests you can play anything from classic Super Mario to Pokemon. I suggest you start with the github, background report and PyBoy documentation right away.
In this original blog, with equally original title, Delip Rao poses twelve (+1) harsh truths about the real world practice of machine learning. I found it quite enlightning to read a non-hyped article about ML for once. Particularly because Delip’s experiences seem to overlap quite nicely with the principles of software design and Agile working.
Delip’s 12 truths I’ve copied in headers below. If they spark your interest, read more here:
It has to work
No matter how hard you push and no matter what the priority, you can’t increase the speed of light
With sufficient thrust, pigs fly just fine. However, this is not necessarily a good idea
Some things in life can never be fully appreciated nor understood unless experienced firsthand
It is always possible to agglutinate multiple separate problems into a single complex interdependent solution. In most cases, this is a bad idea
It is easier to ignore or move a problem around than it is to solve it
You always have to tradeoff something
Everything is more complicated than you think
You will always under-provision resources
One size never fits all. Your model will make embarrassing errors all the time despite your best intentions
Every old idea will be proposed again with a different name and a different presentation, regardless of whether it works
Perfection has been reached not when there is nothing left to add, but when there is nothing left to take away
Delip added in a +1, with his zero-indexed truth: You are Not a Scientist.
Yes, that’s all of you building stuff with machine learning with a “scientist” in the title, including all of you with PhDs, has-been-academics, and academics with one foot in the industry. Machine learning (and other AI application areas, like NLP, Vision, Speech, …) is an engineering research discipline (as opposed to science research).
Delip [bio] is the VP of Research at AI Foundation where he leads speech, language, and vision research efforts for generating and detecting artificial content. You can find his personal webblog here.