Another pearl of a resource on Twitter is this thread by Madison on 10 of fundamentalal concepts of Javascript — and programming in general for that matter.
For your convience, I copied the links below. Just click them to browse to the resource and learn more about the concept
If you're learning JavaScript, you've likely heard people tell you how important it is to learn the fundamentals.
But what are they? And where do you learn them?
Here's a list of JavaScript fundamentals and my favorite free resources for learning them. 👇
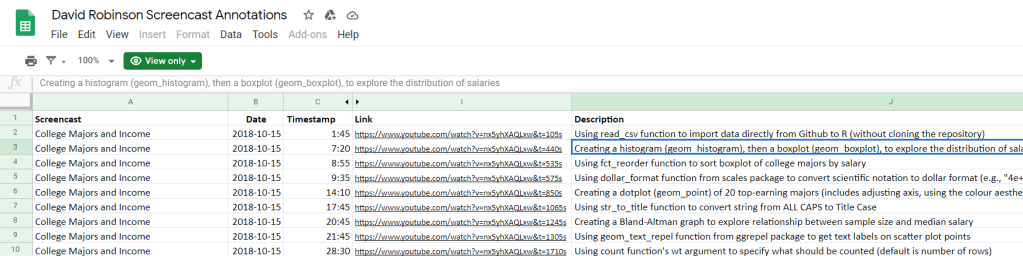
David Robinson (aka drob) is one of the best known R programmers.
Since a couple of years David has been sharing his knowledge through streaming screencasts of him programming. It’s basically part of R’s #tidytuesday movement.
Alex Cookson decided to do us all a favor and annotate all these screencasts into a nice overview.
Here you can search for video material of David using a specific function or method. There are already over a thousand linked fragments!
Very useful if you want to learn how to visualize data using ggplot2 or plotly, how to work with factors in forcats, or how to tidy data using tidyr and dplyr.
For instance, you could search for specific R functions and packages you want to learn about:
Thanks David for sharing your knowledge, and thanks Alex for maintaining this overview!
The assumption that a Machine Learning (ML) project is done when a trained model is put into production is quite faulty. Neverthless, according to Alexandre Gonfalonieri — artificial intelligence (AI) strategist at Philips — this assumption is among the most common mistakes of companies taking their AI products to market.
Actually, in the real world, we see pretty much the opposite of this assumption. People like Alexandre therefore strongly recommend companies keep their best data scientists and engineers on a ML project, especially after it reaches production!
Why?
If you’ve ever productionized a model and really started using it, you know that, over time, your model will start performing worse.
In order to maintain the original accuracy of a ML model which is interacting with real world customers or processes, you will need to continuously monitor and/or tweak it!
In the best case, algorithms are retrained with each new data delivery. This offers a maintenance burden that is not fully automatable. According to Alexandre, tending to machine learning models demands the close scrutiny, critical thinking, and manual effort that only highly trained data scientists can provide.
This means that there’s a higher marginal cost to operating ML products compared to traditional software. Whereas the whole reason we are implementing these products is often to decrease (the) costs (of human labor)!
What causes this?
Your models’ accuracy will often be at its best when it just leaves the training grounds.
Building a model on relevant and available data and coming up with accurate predictions is a great start. However, for how long do you expect those data — that age by the day — continue to provide accurate predictions?
Chances are that each day, the model’s latent performance will go down.
This phenomenon is called concept drift, and is heavily studied in academia but less often considered in business settings. Concept drift means that the statistical properties of the target variable, which the model is trying to predict, change over time in unforeseen ways.
In simpler terms, your model is no longer modelling the outcome that it used to model. This causes problems because the predictions become less accurate as time passes.
Particularly, models of human behavior seem to suffer from this pitfall.
The key is that, unlike a simple calculator, your ML model interacts with the real world. And the data it generates and that reaches it is going to change over time. A key part of any ML project should be predicting how your data is going to change over time.
You need to create a monitoring strategy before reaching production!
According to Alexandre, as soon as you feel confident with your project after the proof-of-concept stage, you should start planning a strategy for keeping your models up to date.
How often will you check in?
On the whole model, or just some features?
What features?
In general, sensible model surveillance combined with a well thought out schedule of model checks is crucial to keeping a production model accurate. Prioritizing checks on the key variables and setting up warnings for when a change has taken place will ensure that you are never caught by a surprise by a change to the environment that robs your model of its efficacy.
Your strategy will strongly differ based on your model and your business context.
Moreover, there are many different types of concept drift that can affect your models, so it should be a key element to think of the right strategy for you specific case!
Once you observe degraded model performance, you will need to redesign your model (pipeline).
One solution is referred to as manual learning. Here, we provide the newly gathered datato our model and re-train and re-deploy it just like the first time we build the model. If you think this sounds time-consuming, you are right. Moreover, the tricky part is not refreshing and retraining a model, but rather thinking of new features that might deal with the concept drift.
A second solution could be to weight your data. Some algorithms allow for this very easily. For others you will need to custom build it in yourself. One recommended weighting schema is to use the inversely proportional age of the data. This way, more attention will be paid to the most recent data (higher weight) and less attention to the oldest of data (smaller weight) in your training set. In this sense, if there is drift, your model will pick it up and correct accordingly.
According to Alexandre and many others, the third and best solution is to build your productionized system in such a way that you continuously evaluate and retrain your models. The benefit of such a continuous learning system is that it can be automated to a large extent, thus reducing (the human labor) maintance costs.
Although Alexandre doesn’t expand on how to do these, he does formulate the three steps below:
In my personal experience, if you have your model retrained (automatically) every now and then, using a smart weighting schema, and keep monitoring the changes in the parameters and for several “unit-test” cases, you will come a long way.
If you’re feeling more adventureous, you could improve on matters by having your model perform some exploration (at random or rule-wise) of potential new relationships in your data (see for instance multi-armed bandits). This will definitely take you a long way!