In Glad You Asked, Vox dives deep into timely questions around the impact of systemic racism on our communities and in our daily lives.
In this video, they look into the role of tech in societal discrimination. People assume that tech and data are neutral, and we have turned to tech as a way to replace biased human decision-making. But as data-driven systems become a bigger and bigger part of our lives, we see more and more cases where they fail. And, more importantly, that they don’t fail on everyone equally.
Why do we think tech is neutral? How do algorithms become biased? And how can we fix these algorithms before they cause harm? Find out in this mini-doc:
Good teachers are rare, so when you find one, cherish him or her.
Anders Brownworth is an exemplar teacher. I found this tutorial by his hand on what constitutes a blockchain, and it is by far the best explanation of the concept(s) I have seen this far.
Anders breaks down the material for total newbies, explaining one concept at a time. You are taken from a hash, to a block, to a blockchain, to distribution, tokens, and a coinbase.
Great work Anders, and too good of a resource not to share!
Now, hold on to your hat, as you can access this blockchain application yourself and play around with the concepts like Anders does in the video.
Computerphile is a Youtube sister channel of Numberphile. Where Numberphile’s videos are about the magic behind match and numbers, Computerphile’s videos are all about computers and computer stuff. I recommend both channels in general, and have watched many of their videos already.
Yet, over the past weeks I specifically enjoyed what seems to be several series of videos on Cyber Security related topics.
What makes a good password?
One series is all about passwords.
What are strong passwords, which are bad? How can hackers crack yours? And how do websites secure user passwords?
The videos below are in somewhat of the right order and they make for an interesting insight in the world of password management. They give you advice on how to pick you password, and even a nice tool to check whether your password has ever been leaked.
Probably, you will want to change your password afterwards!
Hacking and attacking
If you are up to no good, please do not watch this second series, which revolves all around hacks and computer attacks.
How do people get access to a websites database? How can we prevent it? How can we recognize security dangers?
You might know of SQL injections, but do you know what a slow loris attack is? Or how ransomware works? Or what exploitX is?
These videos nicely continue the line of a previous post on Try Hack Me’s Cyber Security Challenges, where you can learn how computers work and where there vulnerabilities lie.
Vincent Warmerdam shared this Youtube video which I thoroughly enjoyed watched. It’s about Saul Pwanson, a software engineer whose hobby project got a little out of hand.
In 2016, Saul Pwanson designed a plain-text file format for crossword puzzle data, and then spent a couple of months building a micro-data-pipeline, scraping tens of thousands of crosswords from various sources.
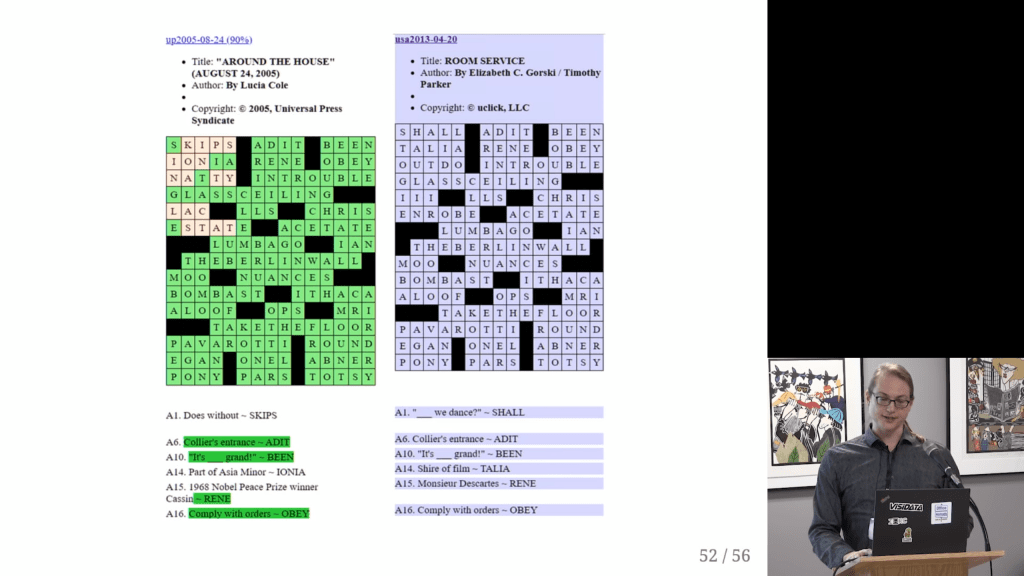
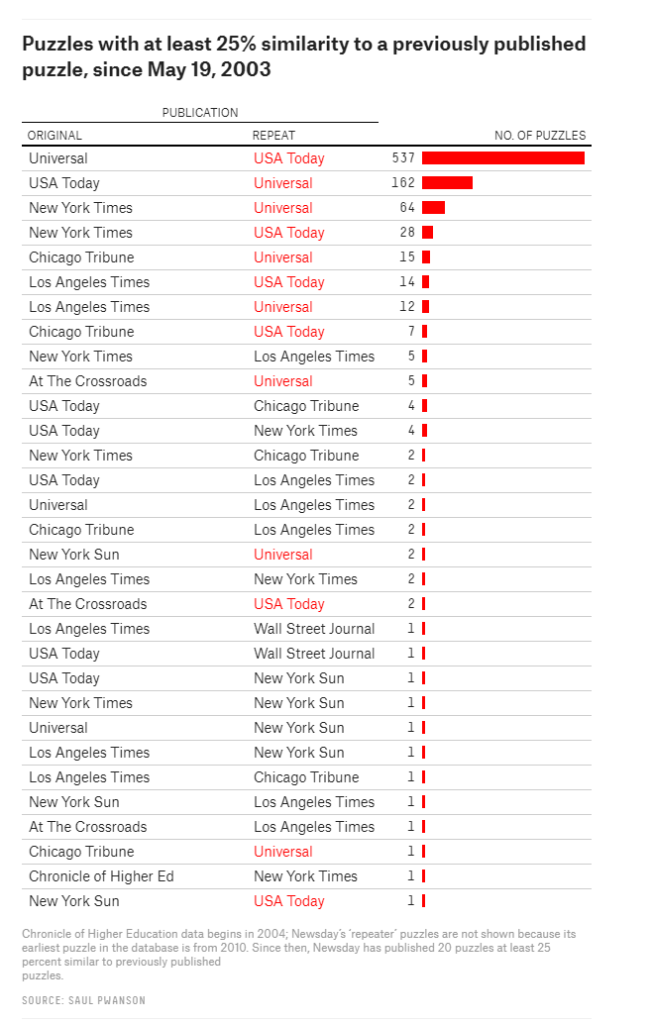
After putting all these crosswords in a simple uniform format, Saul used some simple command line commands to check for common patterns and irregularities.
Surprisingly enough, after visualizing the results, Saul discovered egregious plagiarism by a major crossword editor that had gone on for years.
I thoroughly enjoyed watching this talk on Youtube.
Saul covers the file format, data pipeline, and the design choices that aided rapid exploration; the evidence for the scandal, from the initial anomalies to the final damning visualization; and what it’s like for a data project to get 15 minutes of fame.
I tried to localize the dataset online, but it seems Saul’s website has since gone offline. If you do happen to find it, please do share it in the comments!
This video I’ve been meaning to watch for a while now. It another great visual explanation of a statistics topic by the 3Blue1Brown Youtube channel (which I’ve covered before, multiple times).
This time, it’s all about Bayes theorem, and I just love how Grant Sanderson explains the concept so visually. He argues that rather then memorizing the theorem, we’d rather learn how to draw out the context. Have a look at the video, or read my summary below:
Grant Sanderson explains the concept very visually following an example outlined in Daniel Kahneman’s and Amos Tversky’s book Thinking Fast, Thinking Slow:
Steve is very shy and withdrawn, invariably helpful but with very little interest in people or in the world of reality. A meek and tidy soul, he has a need for order and structure, and a passion for detail.”
Is Steve more likely to be a librarian or a farmer?
Kahneman and Tversky argue that people take into account Steve’s disposition and therefore lean towards librarians.
However, few people take into account that librarians are quite scarce in our society, which is rich with farmers. For every librarian, there are 20+ farmers. Hence, despite the disposition, Steve is probably more like to be a farmer.