

OpenCV is open-source library with tools and functionalities that support computer vision. It allows your computer to use complex mathematics to detect lines, shapes, colors, text and what not.
OpenCV was originally developed by Intel in 2000 and sometime later someone had the bright idea to build a Python module on top of it.
Using a simple…
pip install opencv-python…you can now use OpenCV in Python to build advanced computer vision programs.
And this is exactly what many professional and hobby programmers are doing. Specifically, to get their computer to play (and win) mobile app games.

ZigZag
In ZigZag, you are a ball speeding down a narrow pathway and your only mission is to avoid falling off.
Using OpenCV, you can get your computer to detect objects, shapes, and lines.
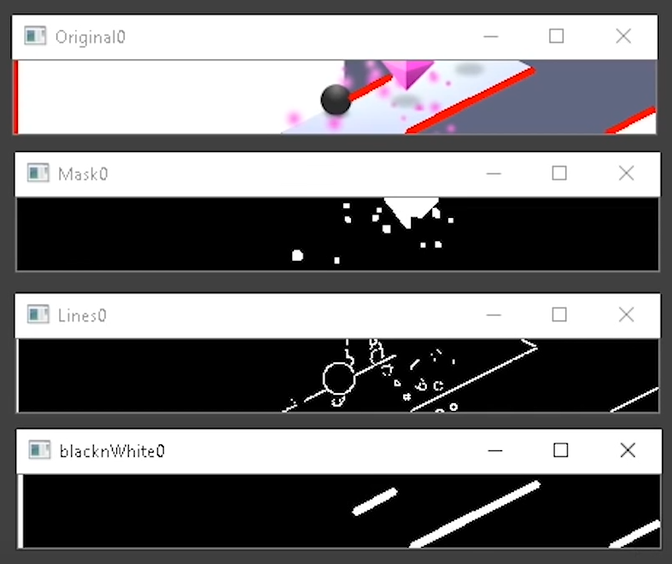
This guy set up an emulator on his computer, so the computer can pretend to be a mobile device. Then he build a program using Python’s OpenCV module to get a top score
You can find the associated code here, but note that will need to set up an emulator yourself before being able to run this code.

Kick Ya Chop
In Kick Ya Chop, you need to stomp away parts of a tree as fast as you can, without hitting any of the branches.
This guy uses OpenCV to perform image pattern matching to allow his computer to identify and avoid the trees braches. Find the code here.
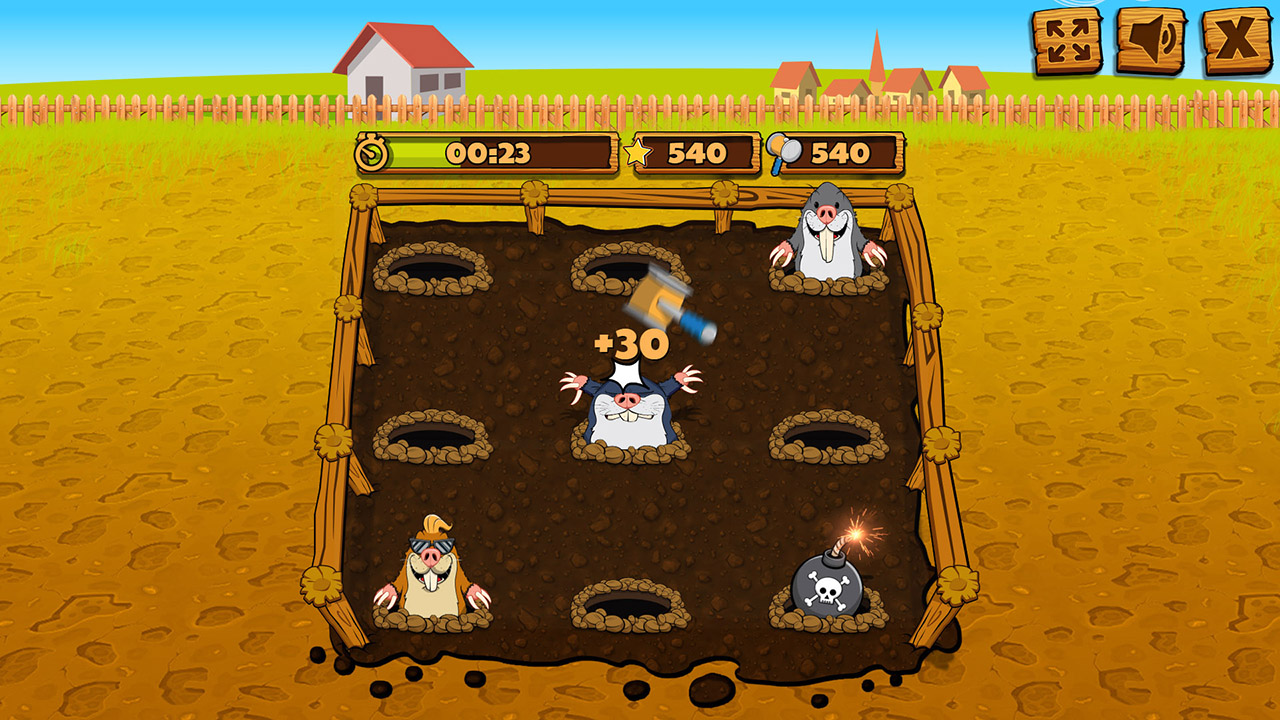
Whack ‘Em All
We all know how to play Whack a Mole, and now this computer knows how to too. Code here.

Pong
This last game also doesn’t need an introduction, and you can find the code here.
Is this machine learning or AI?
If you’d ask me, the videos above provide nice examples of advanced automation. But there’s no real machine learning or AI involved.
Yes, sure, the OpenCV package uses pre-trained neural networks under the hood, and you can definitely call those machine learning. But the programmers who now use the opencv library just leverage the knowledge stored in those network to create very basal decision rules.
IF pixel pattern of mole
THEN whack!
ELSE no whack.To me, it’s only machine learning when there’s really some learning going on. A feedback loop with performance improvement. And you may call it AI, IMO, when the feedback loop is more or less autonomous.
Fortunately, programmers have also been taking a machine learning/AI approach to beating games. Specifically using reinforcement learning. Think of famous applications like AlphaGo and AlphaStar. But there are also hobby programmers who use similar techniques. For example, to get their computer to obtain highscores on Trackmania.
In a later post, I’ll dive into those in more detail.

















{kind=link}