Vincent Warmerdam shared this Youtube video which I thoroughly enjoyed watched. It’s about Saul Pwanson, a software engineer whose hobby project got a little out of hand.
In 2016, Saul Pwanson designed a plain-text file format for crossword puzzle data, and then spent a couple of months building a micro-data-pipeline, scraping tens of thousands of crosswords from various sources.
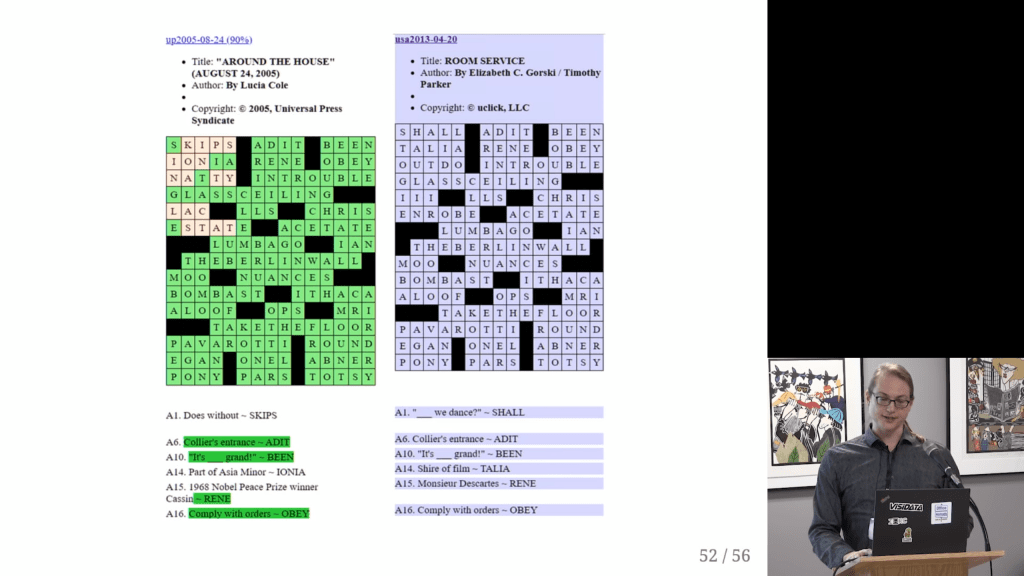
After putting all these crosswords in a simple uniform format, Saul used some simple command line commands to check for common patterns and irregularities.
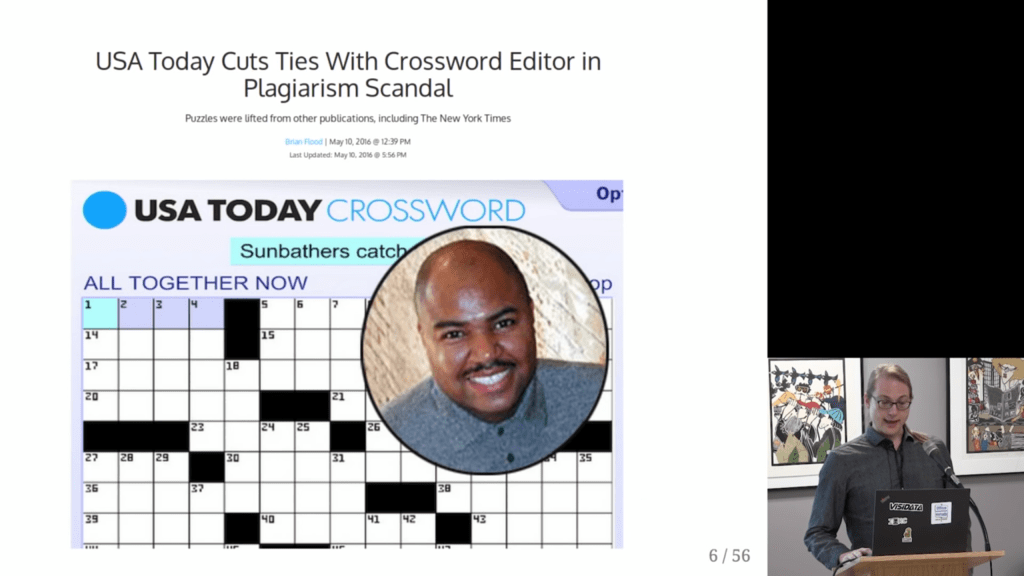
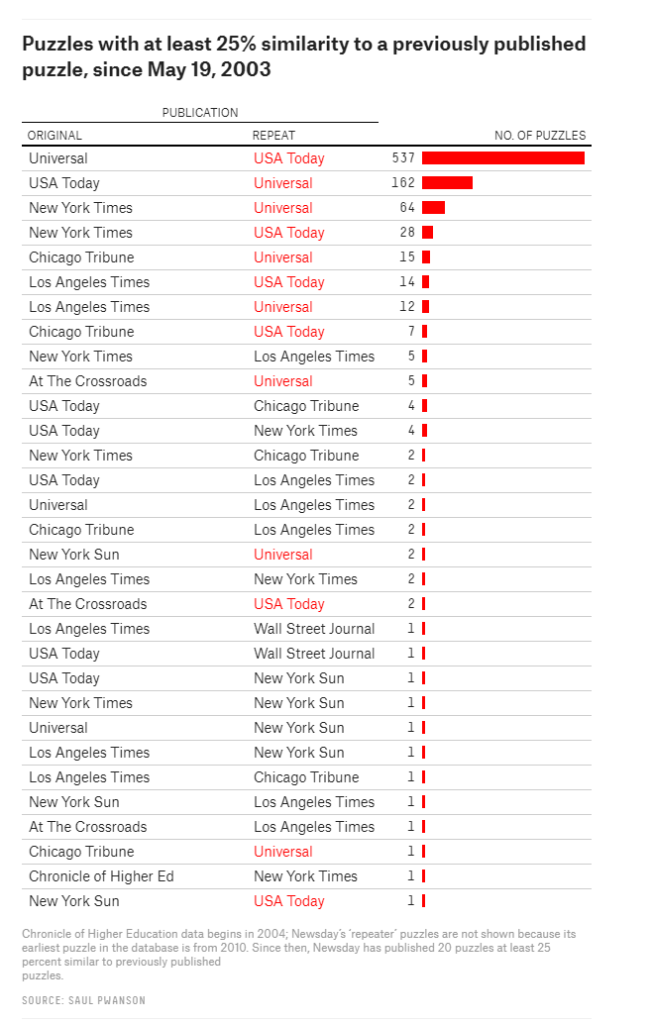
Surprisingly enough, after visualizing the results, Saul discovered egregious plagiarism by a major crossword editor that had gone on for years.
I thoroughly enjoyed watching this talk on Youtube.
Saul covers the file format, data pipeline, and the design choices that aided rapid exploration; the evidence for the scandal, from the initial anomalies to the final damning visualization; and what it’s like for a data project to get 15 minutes of fame.
I tried to localize the dataset online, but it seems Saul’s website has since gone offline. If you do happen to find it, please do share it in the comments!
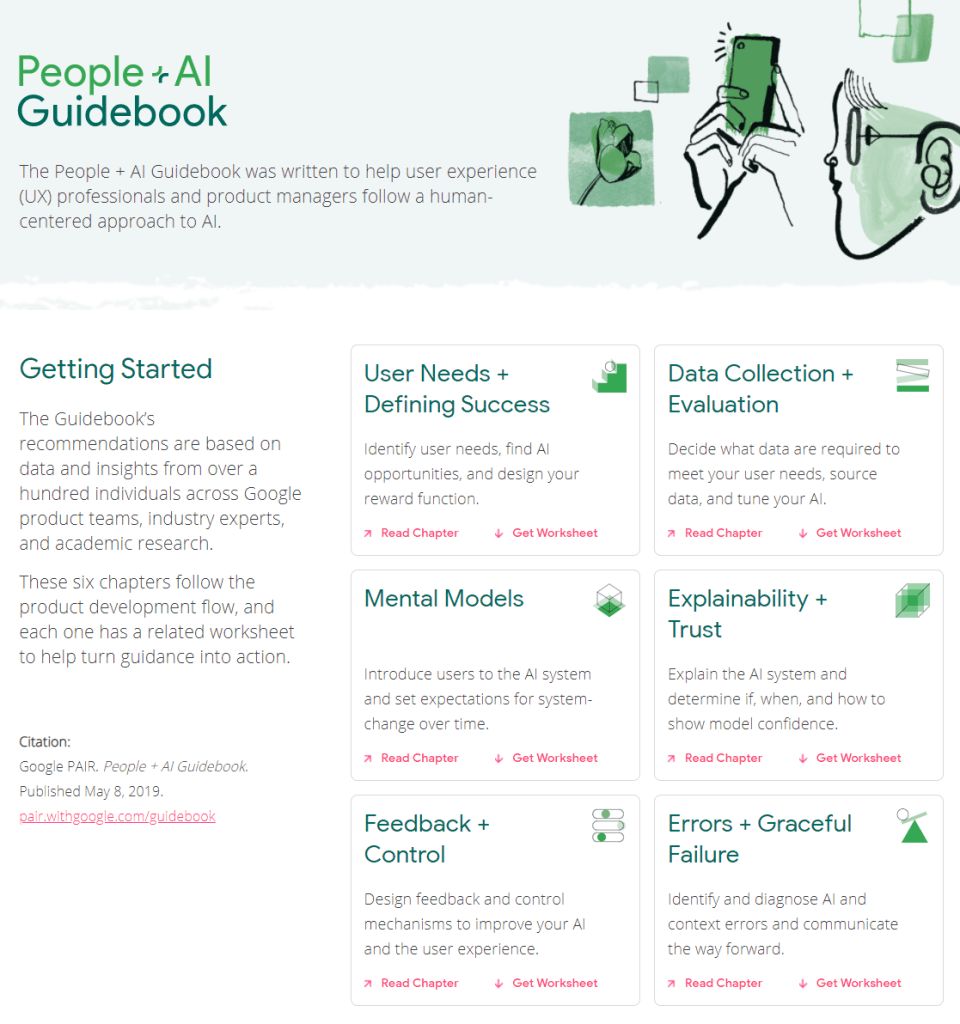
The People + AI Guidebook was written to help user experience (UX) professionals and product managers follow a human-centered approach to AI.
The Guidebook’s recommendations are based on data and insights from over a hundred individuals across Google product teams, industry experts, and academic research.
These six chapters follow the product development flow, and each one has a related worksheet to help turn guidance into action.
The People & AI guidebook is one of the products of the major PAIR project team (People & AI Research).
Here are the direct links to the six guidebook chapters:
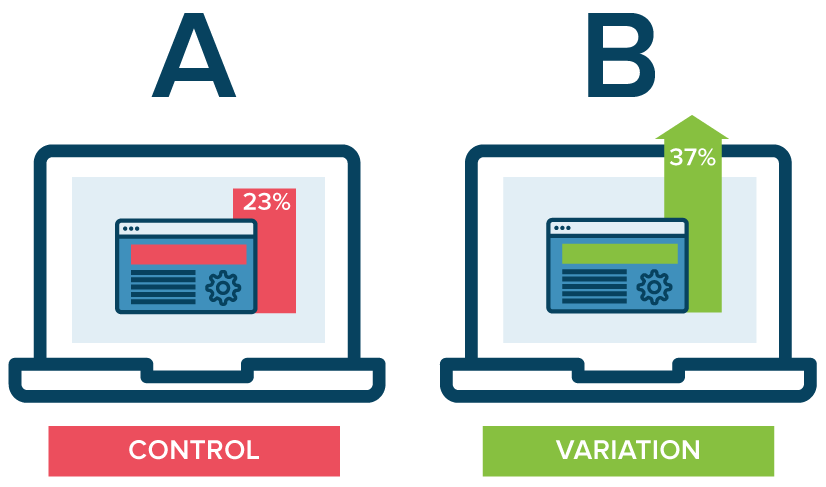
A/B testing is a method of comparing two versions of some thing against each other to determine which is better. A/B tests are often mentioned in e-commerce contexts, where the things we are comparing are web pages.
Business leaders and data scientists alike face a difficult trade-off when running A/B tests: How big should the A/B test be? Or in other words, After collecting how many data points, or running for how many days, should we make a decision whether A or B is the best way to go?
This is a tradeoff because the sample size of an A/B test determines its statistical power. This statistical power, in simple terms, determines the probability of a A/B test showing an effect if there is actually really an effect. In general, the more data you collect, the higher the odds of you finding the real effect and making the right decision.
By default, researchers often aim for 80% power, with a 5% significance cutoff. But is this general guideline really optimal for the tradeoff between costs and benefits in your specific business context? Chris thinks not.
Chris said wrote a great three-piece blog in which he explains how you can mathematically determine the optimal duration of A/B-testing in your own company setting:
Part I: General Overview. Starts with a mostly non-technical overview and ends with a section called “Three lessons for practitioners”.
Part II: Expected lift. A more technical section that quantifies the benefits of experimentation as a function of sample size.
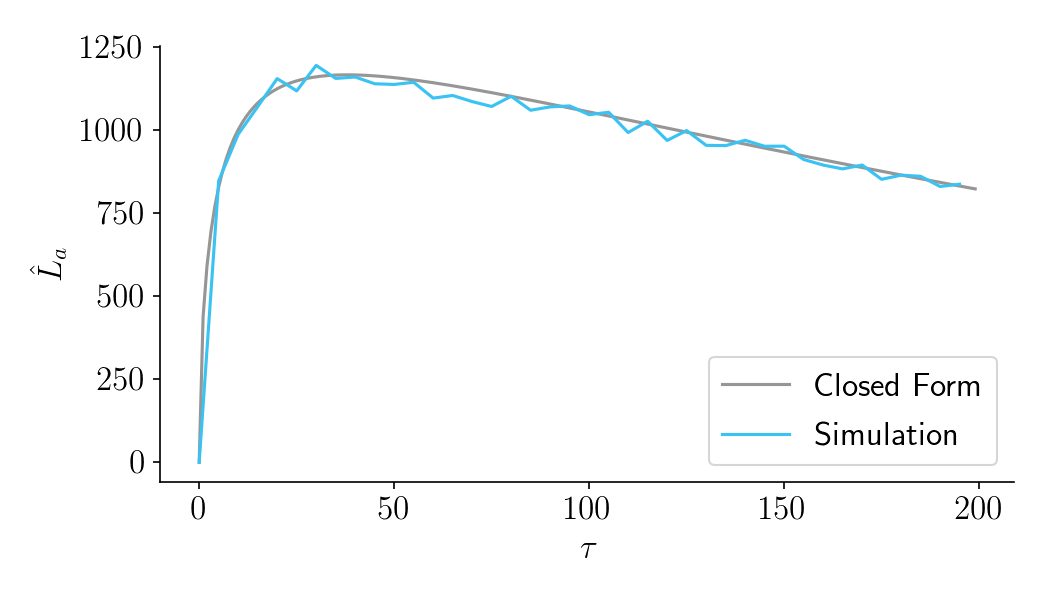
Part III: Aggregate time-discounted lift. A more technical section that quantifies the costs of experimentation as a function of sample size. It then combines costs and benefits into a closed-form expression that can be optimized. Ends with an FAQ.
In this original blog, with equally original title, Delip Rao poses twelve (+1) harsh truths about the real world practice of machine learning. I found it quite enlightning to read a non-hyped article about ML for once. Particularly because Delip’s experiences seem to overlap quite nicely with the principles of software design and Agile working.
Delip’s 12 truths I’ve copied in headers below. If they spark your interest, read more here:
It has to work
No matter how hard you push and no matter what the priority, you can’t increase the speed of light
With sufficient thrust, pigs fly just fine. However, this is not necessarily a good idea
Some things in life can never be fully appreciated nor understood unless experienced firsthand
It is always possible to agglutinate multiple separate problems into a single complex interdependent solution. In most cases, this is a bad idea
It is easier to ignore or move a problem around than it is to solve it
You always have to tradeoff something
Everything is more complicated than you think
You will always under-provision resources
One size never fits all. Your model will make embarrassing errors all the time despite your best intentions
Every old idea will be proposed again with a different name and a different presentation, regardless of whether it works
Perfection has been reached not when there is nothing left to add, but when there is nothing left to take away
Delip added in a +1, with his zero-indexed truth: You are Not a Scientist.
Yes, that’s all of you building stuff with machine learning with a “scientist” in the title, including all of you with PhDs, has-been-academics, and academics with one foot in the industry. Machine learning (and other AI application areas, like NLP, Vision, Speech, …) is an engineering research discipline (as opposed to science research).
Delip [bio] is the VP of Research at AI Foundation where he leads speech, language, and vision research efforts for generating and detecting artificial content. You can find his personal webblog here.
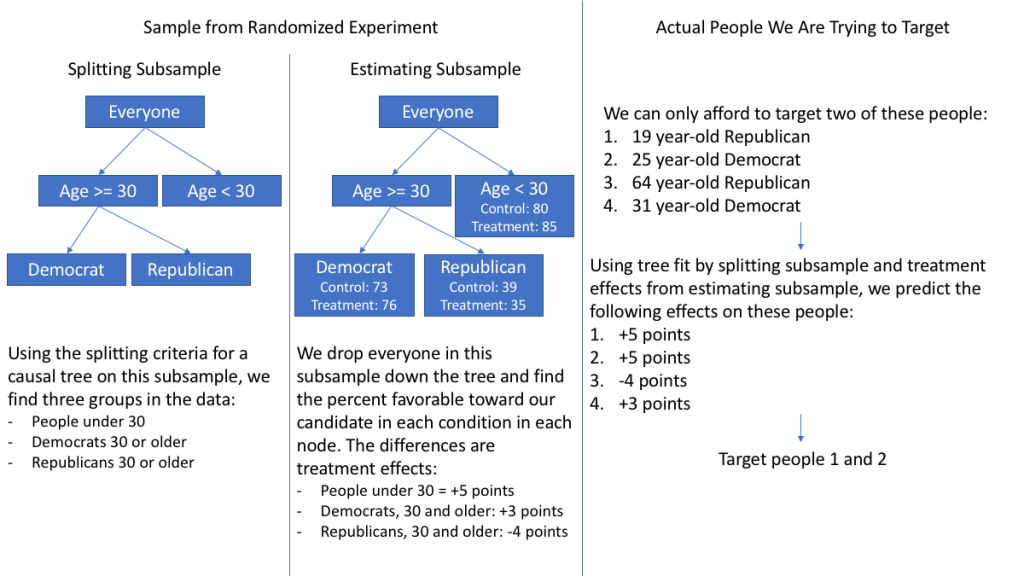
I stumbled accros this incredibly interesting read by Mark White, who discusses the (academic) theory behind, inner workings, and example (R) applications of causal random forests:
These so-called “honest” forests seem a great technique to identify opportunities for personalized actions: think of marketing, HR, medicine, healthcare, and other personalized recommendations. Note that an experimental setup for data collection is still necessary to gather the right data for these techniques.
There’s another great talk on the RStudio website. In this talk, Mark Sellors discusses some of the misinformation around the idea of what “putting something into production” actually means, and provides some tips on overcoming obstacles.









{kind=link}