Sometimes I just stumble across these random resources that I immediately want to share with fellow geeks. If you like computers and programming, you should definitely have a look at…
TryHackMe started in 2018 by two cyber security enthusiasts, Ashu Savani and Ben Spring, who met at a summer internship. When getting started with in the field, they found learning security to be a fragmented, inaccessable and difficult experience; often being given a vulnerable machine’s IP with no additional resources is not the most efficient way to learn, especially when you don’t have any prior knowledge. When Ben returned back to University he created a way to deploy machines and sent it to Ashu, who suggested uploading all the notes they’d made over the summer onto a centralised platform for others to learn, for free.
To allow users to share their knowledge, TryHackMe allows other users (at no charge) to create a virtual room, which contains a combination of theoretical and practical learning components.. In early 2019, Jon Peters started creating rooms and suggested the platform build up a community, a task he took on and succeeded in.
The platform has never raised any capital and is entirely bootstrapped.
I don’t have any affiliation or whatever with the platform, but I just think it’s a super cool resource if you want to learn more about hands-on computer stuff.
Here’s a nice demo on an advanced programmer taking on one of the first challenges. I definitely still have a long way to go, but it’s fun to watch someone sneak into a (dummy) server and look for clues! Like a proper detective, but then an extra nerdy one!
There are many “hacktivities” you can try on the platform.
And if you’re serious about learning this stuff, there are learning paths set out for you!
If you like their content, do consider taking a paid subscription and share this great initiative!
By adjusting the three elements in this simple framework, you can build any type of machine learning program.
In the tutorial, Eric shows you how to implement this same framework in Python (using jax) and implement linear regression, logistic regression, and artificial neural networks all in the same way (using gradient descent).
I can’t even begin to explain it as well as Eric does himself, so I highly recommend you watch and code along with the Youtube tutorial (~1 hour):
Have you ever wondered what goes on behind the scenes of a deep learning framework? Or what is going on behind that pre-trained model that you took from Kaggle? Then this tutorial is for you! In this tutorial, we will demystify the internals of deep learning frameworks – in the process equipping us with foundational knowledge that lets us understand what is going on when we train and fit a deep learning model. By learning the foundations without a deep learning framework as a pedagogical crutch, you will walk away with foundational knowledge that will give you the confidence to implement any model you want in any framework you choose.
In this tutorial, you will be introduced to the command line. We have selected a set of commands we think will be useful in general to a wide range of audience. […] after completing this tutorial, readers should be able to use the shell for version control, managing cloud services (like deploying your own shiny server etc.), execute commands in R & RMarkdown and execute R scripts in the shell.
If you want a deeper understanding of using command line for data science, the original authors suggest you read Data Science at the Command Line. Moreover, Software Carpentry has a lesson on shell. More references are listed at the end of the original tutorial. Use the clickable table of contents to quickly browse to the topic of your interest:
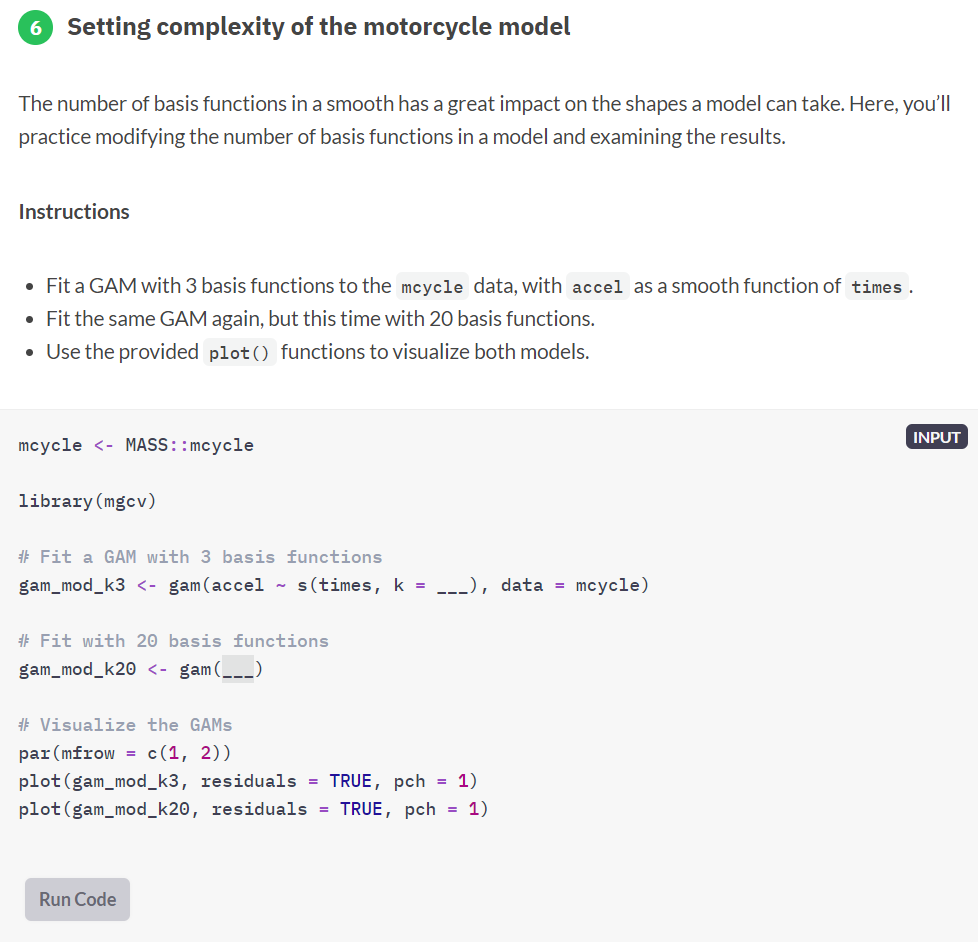
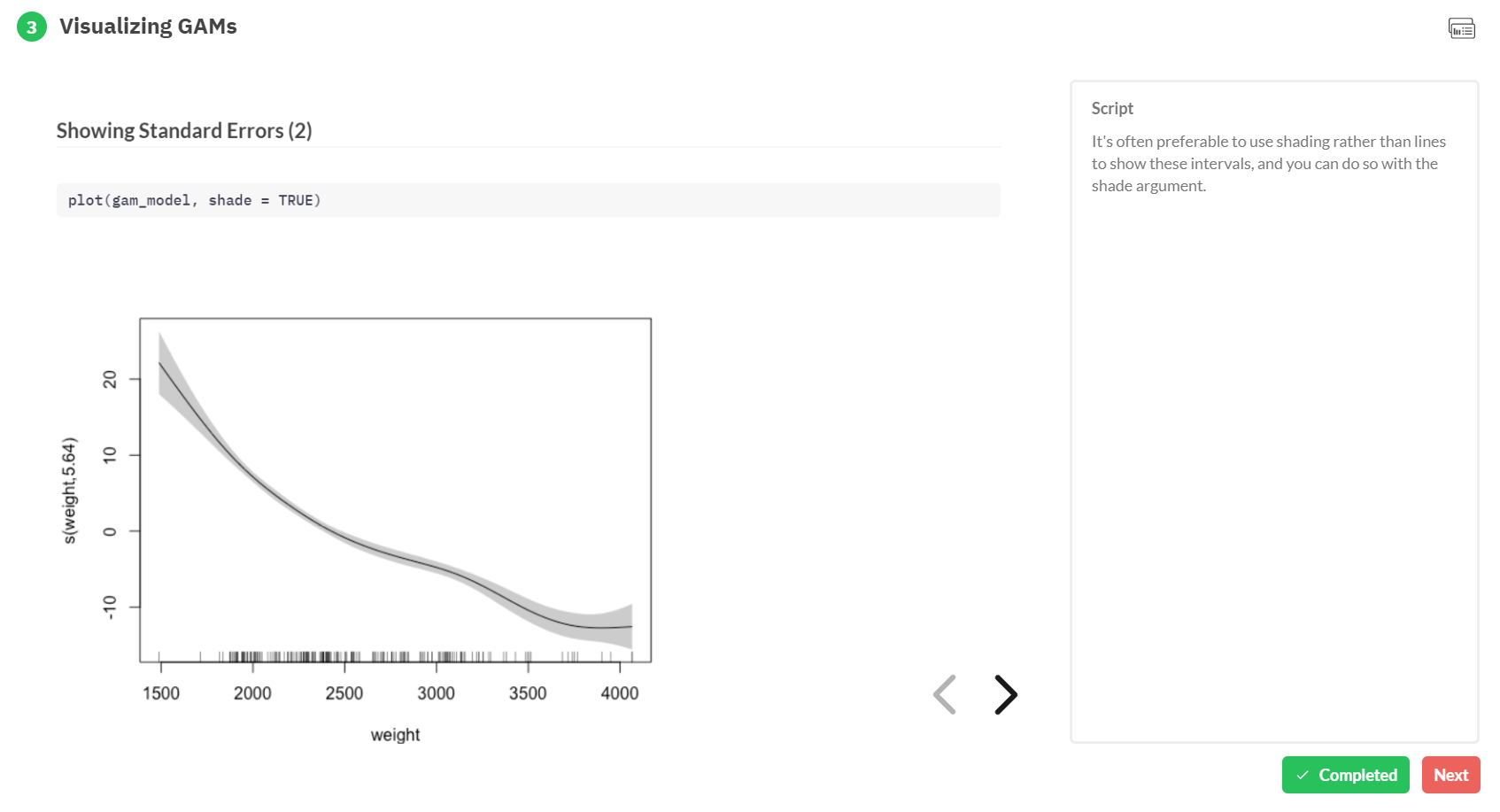
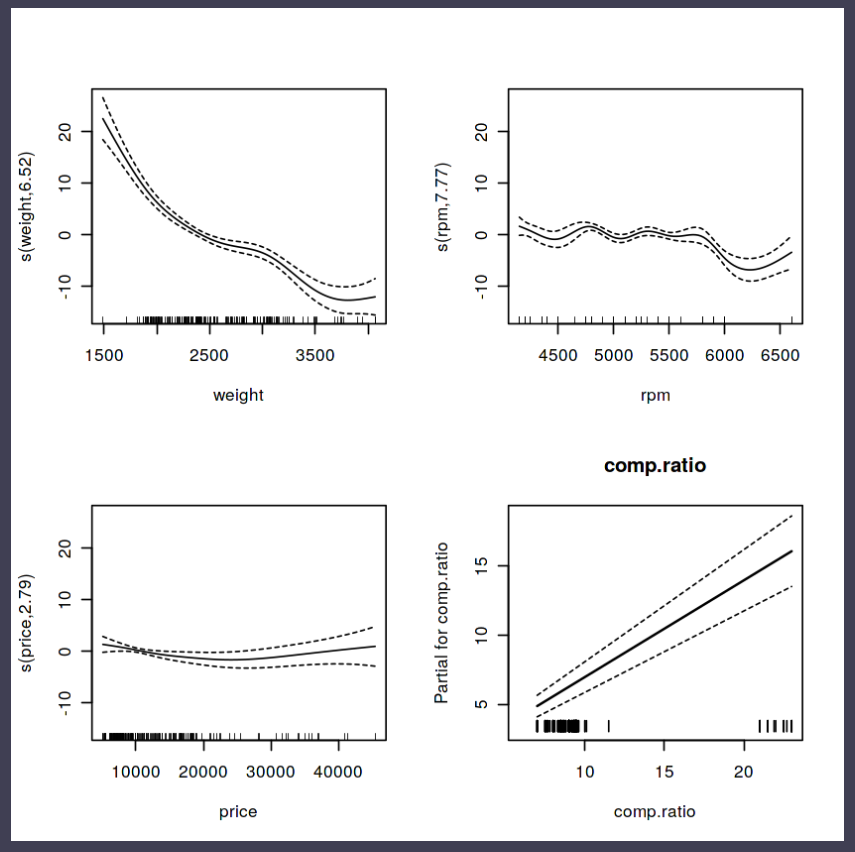
Generalized Additive Models — or GAMs in short — have been somewhat of a mystery to me. I’ve known about them, but didn’t know exactly what they did, or when they’re useful. That came to an end when I found out about this tutorial by Noam Ross.
In this beautiful, online, interactive course, Noam allows you to program several GAMs yourself (in R) and to progressively learn about the different functions and features. I am currently halfway through, but already very much enjoy it.
If you’re already familiar with linear models and want to learn something new, I strongly recommend this course!
2018 seemed to be the year of challengesgoing viral on the web. Most of them were plain stupid and/or dangerous. However, one viral challenge I did like: #100DaysOfCode
1. Code minimum an hour every day for the next 100 days.
2. Tweet your progress every day with the #100DaysOfCode hashtag.
3. Each day, reach out to at least two people on Twitter who are also doing the challenge
Many (aspiring) programming professionals competed in this challenge, sharing their learning journeys in domains from web development, machine learning, or data visualization.
With this blog, I wanted to share two of those learning journeys that stood out for me.
Machine learning
First, there’s Avik Jain’s 100 days of Machine Learning code repository on Github. Avik’s repository contains all learning activities he followed during the 53 days of programming he completed. Some of Avik’s entries really stood out, and I particularly liked his educational infographics:
Just look at the wonderful design and visual aids on this decision tree for dummies infographic, pseudocode and all:
Day 23: Decision trees for dummies. This just looks fabulous right?!
Although Avik didn’t seem to have completed the full 100 days, many others did.
Data visualization
I have blogged about Hannah Yan Han‘s 100 days of code project before, but she definately deserves another mention here. Her 100 days revolved around data science, data visualization, and storytelling using both R and Python. You can find her #100DaysOfCode Medium page here, and her associated Github repository here.
For example, one day Hannah explored where instant noodles come from, how they are served, and whether people like them or not.
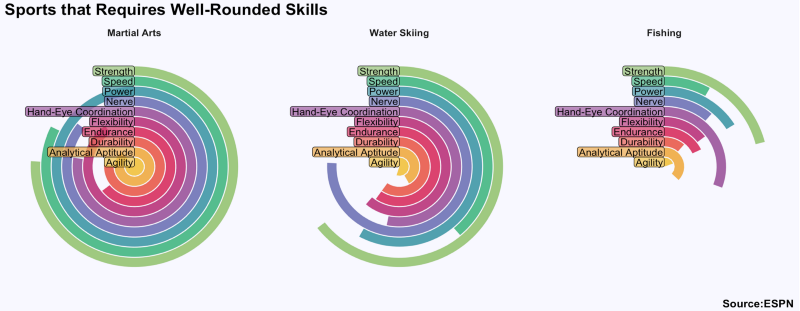
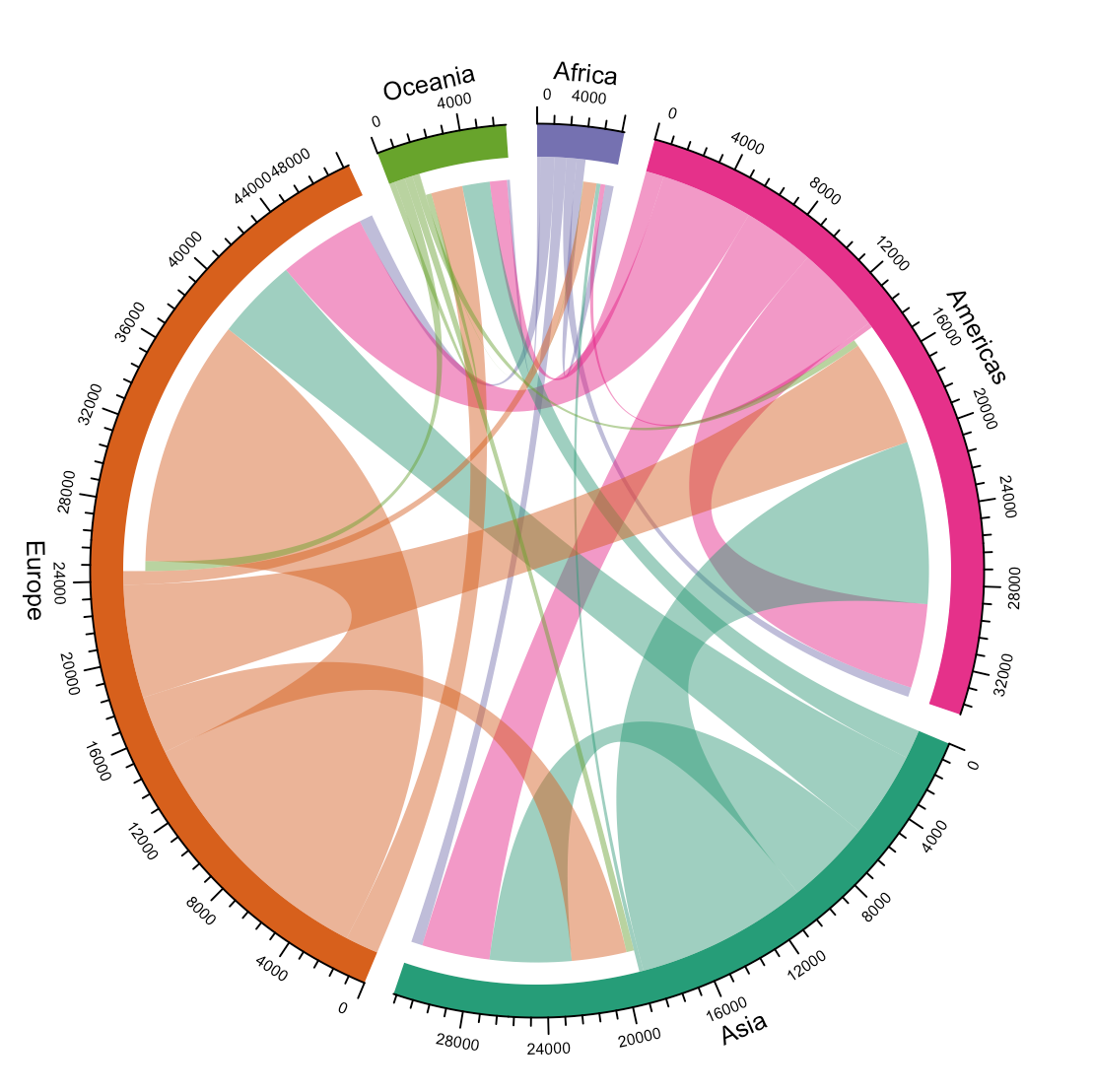
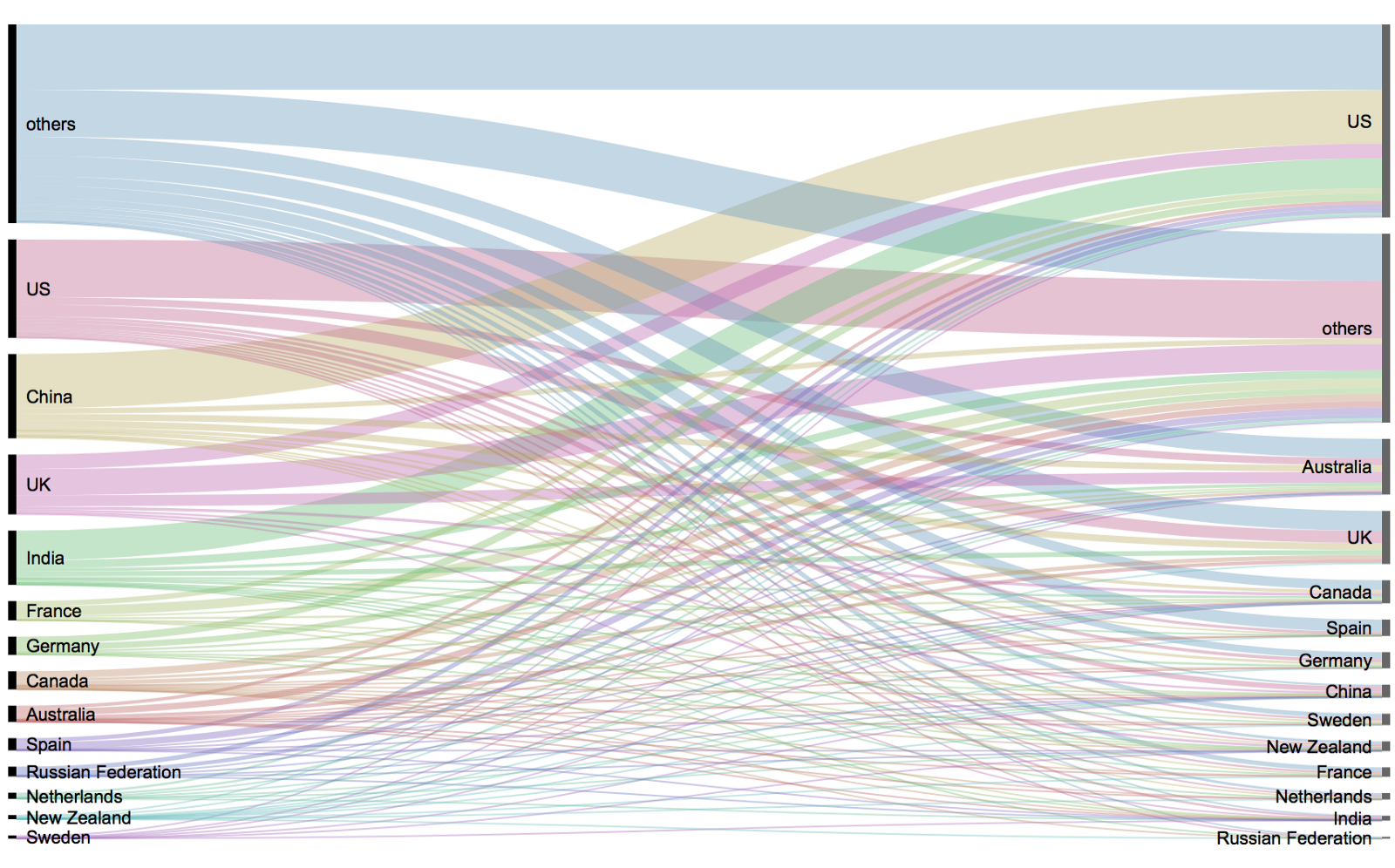
What I found so great about Hannah’s project is that she picked a novel dataset every couple of days. Moreover, she used a extremely large variety of different visualization formats. All visuals were equally beautiful, but Hannah made sure to pick the right one for the purpose she was trying to serve. If you are interested in data visualization, you seriously should check out Hannah’s 100DaysOfCode Medium page.

























{kind=link}