Tait Brown was annoyed at the Victoria Police who had spent $86 million Australian dollars on developing the BlueNet system which basically consists of an license-plate OCR which crosschecks against a car theft database.
Tait was so disgruntled as he thought he could easily replicate this system without spending millions and millions of tax dollars. And so he did. In only 57 lines of JavaScript, though, to be honest, there are many more lines of code hidden away in abstraction and APIs…
Anyway, he built a system that can identify license plates, read them, and should be able to cross check them with a criminal database.
However, then I imagined that not everybody may be familiar with k-means, hence, I wrote the whole blog below.
Next thing I know, u/dashee87 on r/datascience points me to these two other blogs that had already done the same… but way better! These guys perfectly explain k-means, alongside many other clustering algorithms. Including interactive examples and what not!!
Seriously, do not waste your time on reading my blog below, but follow these links. If you want to play, go for Naftali’s apps. If you want to learn, go for David’s animated blog.
Naftali Harris built this fantastic interactive app where you can run the k-means algorithm step by step on many different datasets. You can even pick the clusters’ starting locations yourself! Next to this he provides a to-the-point explanation of the inner workings. On top of all this, he built the same app for the DBSCAN algorithm(wiki), so you can compare the algorithms’ performance… Insane!
David Sheehan (yes, that’s dashee) is more of a Python guy and walks you through the inner workings of six algorithmic clustering approaches in his blog here. Included are k-means, expectation maximization, hierarchical, mean shift, and affinity propagation clustering, and DBSCAN. David has made detailed step-wise GIF animations of all these algorithms. And he explains the technicalities in a simple and understandable way. On top of this, David shared his Jupyter notebook to generate the animations, along with a repository of the GIFs themselves. Very well done! Seriously one of the best blogs I’ve read in a while.
Let me walk you through what k-means is, why it is called k-means, and how the algorithm interally works, step by step.
Let me dissect that sentence for you, starting at the back.
Algorithm
Simply put, an algorithm (wiki) is a set of task instructions to be followed. Often algorithms are perform by computers, and used in calculations or problem-solving. Basically, an algorithm is thus not much more than a sequence of task instructions to be followed by a computer — like a cooking recipe.
In machine learning (wiki), algorithmic tasks are often divided in supervised or unsupervisedlearning (let’s skip over reinforcement learning for now).
The learning part reflects that algorithms try to learn a solution — learn how to solve a problem.
The supervision part reflects whether the algorithm receives answers or solutions to learn from. For supervised learning, examples are required. In the case of unsupervised learning, algorithms do not learn by example but have figure out a proper solution themselves.
Clustering
Clustering (wiki) is essentially a fancy word for grouping. Clustering algorithms seek to group things together, and try to do so in an optimal way.
Group things. As long as we can represent things in terms of data, clustering algorithms can group them. We can group cars by their weight and horsepower, people by their length and IQ, or frogs by their slimyness and greenness. These things we would like to group, we often call observations (depicted by the letter N or n).
Optimal way. Clustering is very much an unsupervised task. Clustering algorithms do not receive examples to learn from (that’s actually classification (wiki)). Algorithms are not told what “good” clustering or grouping looks like.
Yet, how do clustering algorithms determine the optimal way to group our observations then?
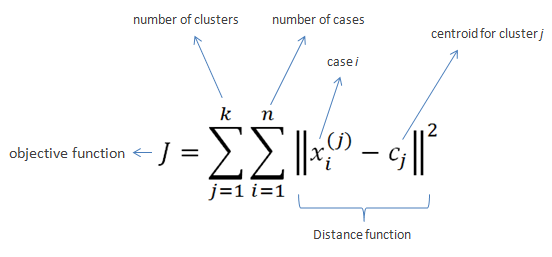
Well, clustering algorithms like k-means do so by optimizing a certain value. This value is reflected in an algorithm’s so-called objective function.
k-means’ objective function is displayed below. In simple language, k-means seeks to minimize (= optimize) the total distance of observations (= cases) to their group’s (= cluster) center (= centroid).
Fortunately, you can immediately forget this function. For now, all you need to know is that algorithms often repeat specific steps of their instructions in order for their objective function to produce a satisfactory value.
Hurray, we can now move to the k-means algorithm itself!
Why is it called k-means in the first place?
Let’s start at the front this time.
k. The k in k-means reflects the number of groups the algorithm is going to form. The algorithm depends on its user to specify what number of k should be. If the user picks k = 2 for instance, the k-means algorithm will identify 2 group by their 2 means.
As I said before, clustering algorithms like k-means are unsupervised. They do not know what good clustering looks like. In the case where the used specified k = 2, the algorithm will seek to optimize its objective function given that there are 2 groups. It will try to put our observations in 2 groups that minimizes the total distance of the observations to their group’s center. I will how that works visually later in this blog.
means. The means in k-means reflects that the algorithm considers the mean value of a cluster as its cluster center. Here, mean is a fancy word for average. Again, I will visualize how this works later.
You might have guessed it already: there are indeed variations of the k-means algorithm that do not use the cluster means, but, for instance, the cluster medians (wiki) or mediods (wiki). These algorithms are only slight modifications of the k-means algorithm, and simply called the k-medians (wiki) and k-medoids algorithms (wiki).
How does k-means work?
Finally, we get to the inner workings of k-means!
The k-means algorithm consists of five simple steps:
Obtain a predefined k.
Pick k random points as cluster centers.
Assign observations to their closest cluster center based on the Euclidean distance.
Update the center of each cluster based on the included observations.
Terminate if no observations changed cluster, otherwise go back to step 3.
Easy right?
OK, I can see how this may not be directly clear.
Let’s run through the steps one by one using an example dataset.
Example dataset: mtcars
Say we have the dataset below, containing information on 32 cars.
We can consider each car a separate observation. For each of these observations, we have its weight and its horsepower.
These characteristics — weight and horsepower — of our observations are the variables in our dataset. Our cars vary based on these variables.
Name
Weight
Horsepower
Mazda RX4
1188
110
Mazda RX4 Wag
1304
110
Datsun 710
1052
93
Hornet 4 Drive
1458
110
Hornet Sportabout
1560
175
Valiant
1569
105
Duster 360
1619
245
Merc 240D
1447
62
Merc 230
1429
95
Merc 280
1560
123
Merc 280C
1560
123
Merc 450SE
1846
180
Merc 450SL
1692
180
Merc 450SLC
1715
180
Cadillac Fleetwood
2381
205
Lincoln Continental
2460
215
Chrysler Imperial
2424
230
Fiat 128
998
66
Honda Civic
733
52
Toyota Corolla
832
65
Toyota Corona
1118
97
Dodge Challenger
1597
150
AMC Javelin
1558
150
Camaro Z28
1742
245
Pontiac Firebird
1744
175
Fiat X1-9
878
66
Porsche 914-2
971
91
Lotus Europa
686
113
Ford Pantera L
1438
264
Ferrari Dino
1256
175
Maserati Bora
1619
335
Volvo 142E
1261
109
Visually, we can represent this same dataset as follows:
Step 1: Define k
For whatever reason, we might want to group these 32 cars.
We know the cars’ weight and horsepower, so we can use these variables to group the cars. The underlying assumption being that cars that are more similar in terms of weight and/or horsepower would belong together in the same group.
Normally, we would have smart or valid reasons to expect a specific number of groups among our observations. For now, let’s simply say that we want to put these cars into, say, 2 groups.
Well, that’s step 1 already completed: we defined k = 2.
Step 2: Initialize cluster centers
In step 2, we need to initialize the algorithm.
Everyone needs to start somewhere, and the default k-means algorithm starts out super naively: it just picks random locations as our starting cluster centers.
For instance, the algorithm might initialize cluster 1 randomly at a weight of 1000 kilograms and a horsepower of 100.
We can use coordinate notation [x; y] or [weight; horsepower] to write this location in short. Hence, the initial random center of cluster 1 picked by the k-means algorithm is located at [1000; 100].
Randomly, k-means could initialize cluster 2 at a weight of 1500kg and a horsepower of 200. It’s intitial center is thus at [1500; 200].
Visually, we can display this initial situation like the below, with our 32 cars as grey dots in the background:
Now, step 2 is done, and our k-means algorithm has been fully initialized. We are now ready to enter the core loop of the algorithm. The next three steps — 3, 4, and 5 — will be repeated until the algorithm tells itself it is done.
Step 3: Assignment to closest cluster
Now, in step 3, the algorithm will assign every single car in our dataset to the cluster whose center is closest.
To do this, the algorithm looks at every car, one by one, and calculate its distance to every of our cluster centers.
So how would this distance calculating thing work?
The algorithm starts with the first car in our dataset, a Mazda RX4.
This Mazda RX4 weighs 1188kg and has 110 horsepower. Hence, it is located at [1188; 110].
As this is the first time our k-means algorithm reaches step 3, the cluster centers are still at the random locations the algorithm has picked in step 2.
The k-means algorithm now calculates the Euclidean distance (wiki) of this Mazda RX4 data point [1188; 110] to each of the cluster centers.
The Euclidean distance is calculated using the formula below. The first line shows you that the Euclidean distance is the square root of the squared distance between two observations. The second line — with the big Greek capital letter Sigma (Σ) — is a shorter way to demonstrate that the distance is calculated and summed up for each of the variables considered.
Again, please don’t mind the formula, the Euclidean distance is basically the length of a straight line between two data points.
So… back to our Mazda RX4. This Mazda is one of the two observations we need to input in the formula. The second observation would be a cluster center. We input both of the location of our Mazda [1188; 110] and that of a cluster center –, say cluster 1’s [1000; 100] — in the formula, and out comes the Euclidean distance between these two observations.
The Euclidean distance of our Mazda RX4 to the center of cluster 1 would thus be √((1118 – 1000)2 + (110 – 100)2), which equals 192.2082 — or a rounded 192.
We need to repeat this, but now with the location of our second cluster center. The Euclidean distance from our Mazda RX4 to the center of cluster 2 would be √((1118 – 1500)2 + (110 – 150)2), which equals 314.5537 — or a rounded 314.
Again, I visualized this situation below.
You can clearly see that our Mazda RX4 is closer to cluster center 1 (192) than to cluster center 2 (314). Hence, as the distance to cluster 1’s center is smaller, the k-means algorithm will now assign our Mazda RX4 to cluster 1.
Subsequently, the algorithm continues with the second car in our dataset.
Let this second car be the Mercedes 280C for now, weighing in at 1560 kg with a horsepower of 153.
Again, the k-means algorithm would calcalute the Euclidean distance from this Mercedes [1560; 153] to each of our cluster centers.
It would find that this Mercedes is located much closer to cluster 2’s center (560) than cluster 1’s (65).
Hence, the k-means algorithm will assign the Mercedes 280C to cluster 2, before continuing with the next car…
and the next car after that…
and the next car…
… until all cars are assigned to one of the clusters.
This would mean that step 3 is completed. Visually, the situation at the end of step 3 will look like this:
Step 4: Update the cluster centers
Now, in step 4, the k-means algorithm will update the cluster centers.
As a result of step 3, there are now actual observations assigned to the clusters. Hence, the k-means algorithm can let go of its naive initial random guesses and calculate the actual cluster centers.
Because we are dealing with the k-means algorithm, these centers will be based on the mean values of the observations in each group.
So for each cluster, the algorithm takes the observations assigned to it, and calculates the cluster’s mean value for every variable. In our case, the algorithm thus calculates 4 means: the average weight and the average horsepower, for each of our two clusters.
For cluster 1, the average weight of its cars is a rounded 939 kg. Its average horsepower is approximately 84. Hence the cluster center is updated to location [939; 84]. Cluster 2’s mean values come in at [1663; 171].
With the cluster centers updated, the k-means algorithm has finished step 4. Visually, the situation now looks as follows, with the old cluster centers in grey.
Step 5: Terminate or go back to step 3.
So that was actually all there is to the k-means algorithm. From now on, the algorithm either terminates or goes back to step 3.
So how does the k-means algorithm know when it is done?
Earlier in this blog post I already asked “how do clustering algorithms determine the optimal way to group our observations?”
Well, we already know that the k-means algorithm wants to optimize its objective function. It seeks to minimize the total distance of observations to their respective cluster centers. It does so by assigning observations to the cluster whose center is nearest according to the Euclidean distance.
Now, with the above in mind, the k-means algorithm determines that it has reached an optimal clustering solution if, in step 3, no single observation switches to a different cluster.
If that is the case, then every observation is assigned to the group whose center values best represent its underlying characteristics (weight and horsepower), and the k-means algorithm is thus satisfied with the solution given this number of groups (= k). These groups centers now best describe the characteristics of the individual observations at hand, given this k, as evidenced that each observations belongs to the cluster whose center values are closest to their own values.
Now, the k-means algorithm will have to check whether it is done somewhere in its instructions. It seems most logical to directly do this in step 3: quickly check whether every observations remained in its original cluster.
This is not so difficult if you have only 32 cars. However, what if we were clustering 100.000 cars? We would not want to check for 100.000 cars whether they remained in their respective cluster, right? That’s a heavy task, even for a computer.
Potentially there is an easier way to check this? Maybe we could look at our cluster centers? We update them in step 4. And if no observations have changed clusters, then the locations of our cluster centers will for sure also not have changed.
Even in our simple example it is less work to see check whether 2 cluster centers have remained the same, than comparing whether 32 cars have not changed clusters.
So basically, that’s what we will do in this step five. We check whether our cluster centers have moved.
In this case, they did. As can be seen in the visual at the end of step 4.
This is also to be expected, as it is very unlikely that the algorithm could have randomly picked the initial cluster centers in their optimal locations, right?
We conclude step 5 and, because the cluster center locations have changed in step 4, the algorithm is sent back to step 3.
Let’s see how the k-means algorithm continues in our example.
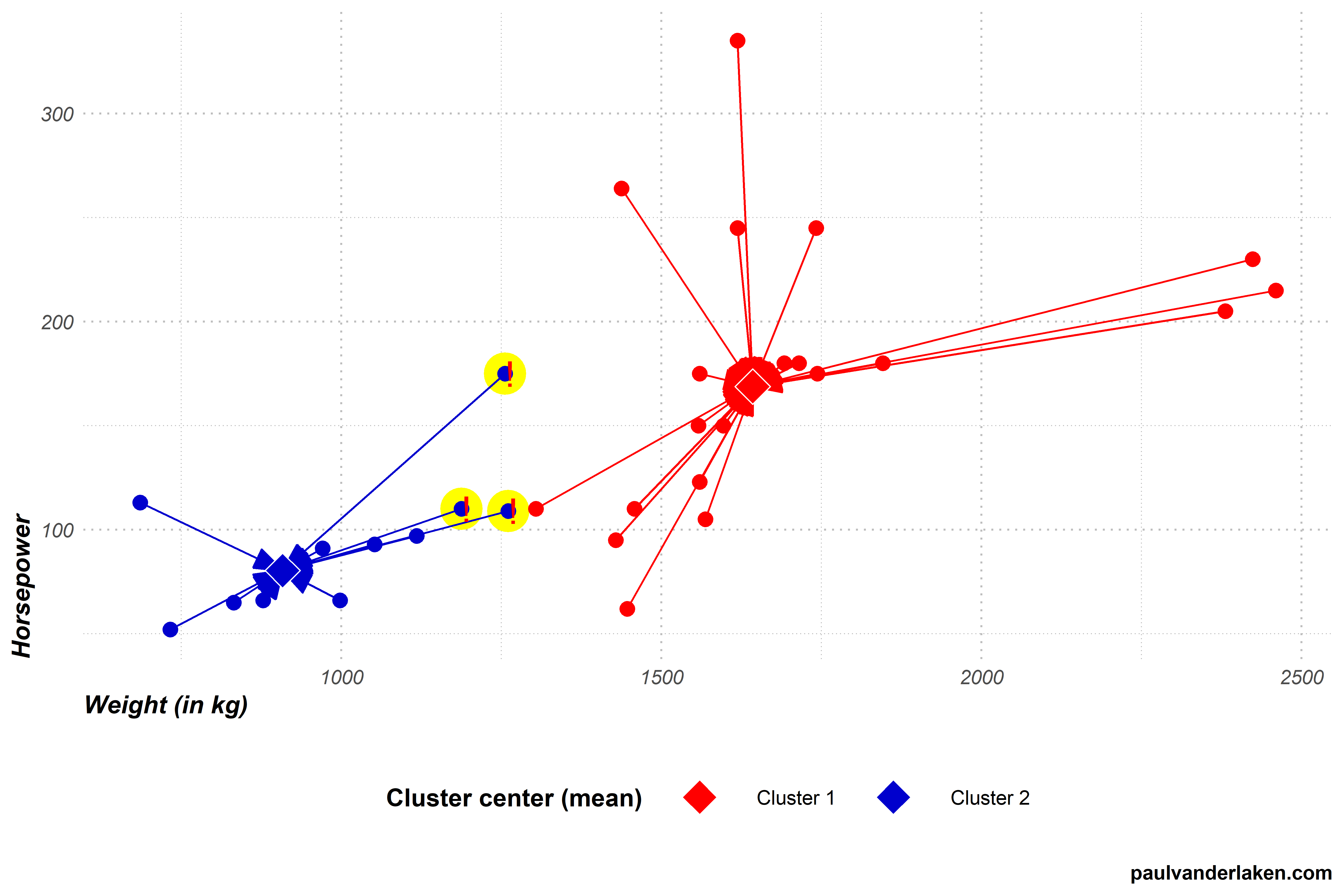
Step 3 (2nd time): Assignment to closest cluster
In step 3, the algorithm reassigns every car in our dataset to the cluster whose center is nearest.
To do this, the algorithm has to look at every car, one by one, and calculate its distance to every of our cluster centers.
Our cluster centers have been updated in the previous step 4. Hence, the distances between our observations and cluster centers may have changed respective to the first time the algorithm performed step 3.
Indeed two cars that were previously closer to the blue cluster 2 center are now actually closer to the red cluster 1 center.
In this step 3, again all observations are assigned to their closest clusters, and two observations thus change cluster.
Visually, the situation now looks like the below. I’ve marked the two cars that switched in yellow and with an exclamation mark.
The k-means algorithm now again reaches step 4.
Step 4 (2nd time): Update the cluster centers
In step 4, the algorithm updates the cluster centers. Because we are dealing with the k-means algorithm, these centers will be based on the mean values of the observations in each group.
For cluster 1, both the average weight and the average horsepower have increased due to the two new cars. The cluster center thus moves from approximately [939; 84] to [998; 94].
Cluster 2 lost two cars from its cluster, but both were on the lower end of its ranges. Hence its average weight and horsepower have also increased, moving the center from approximately [1663; 171] to [1701; 174].
With the cluster centers updated, step 4 is once again completed. Visually, the situation now looks as follows, with the old centers in grey.
Step 5 (2nd time): Terminate or go back to step 3.
In step 5, the k-means algorithm again checks whether it is done. It concludes that it is not, because the cluster centers have both moved once more. This indicates that at least some observations have changed cluster, and that a better solution may be possible. Hence, the algorithm needs to return to step 3 for a third time.
Are you still with me? We are nearly there, I hope…
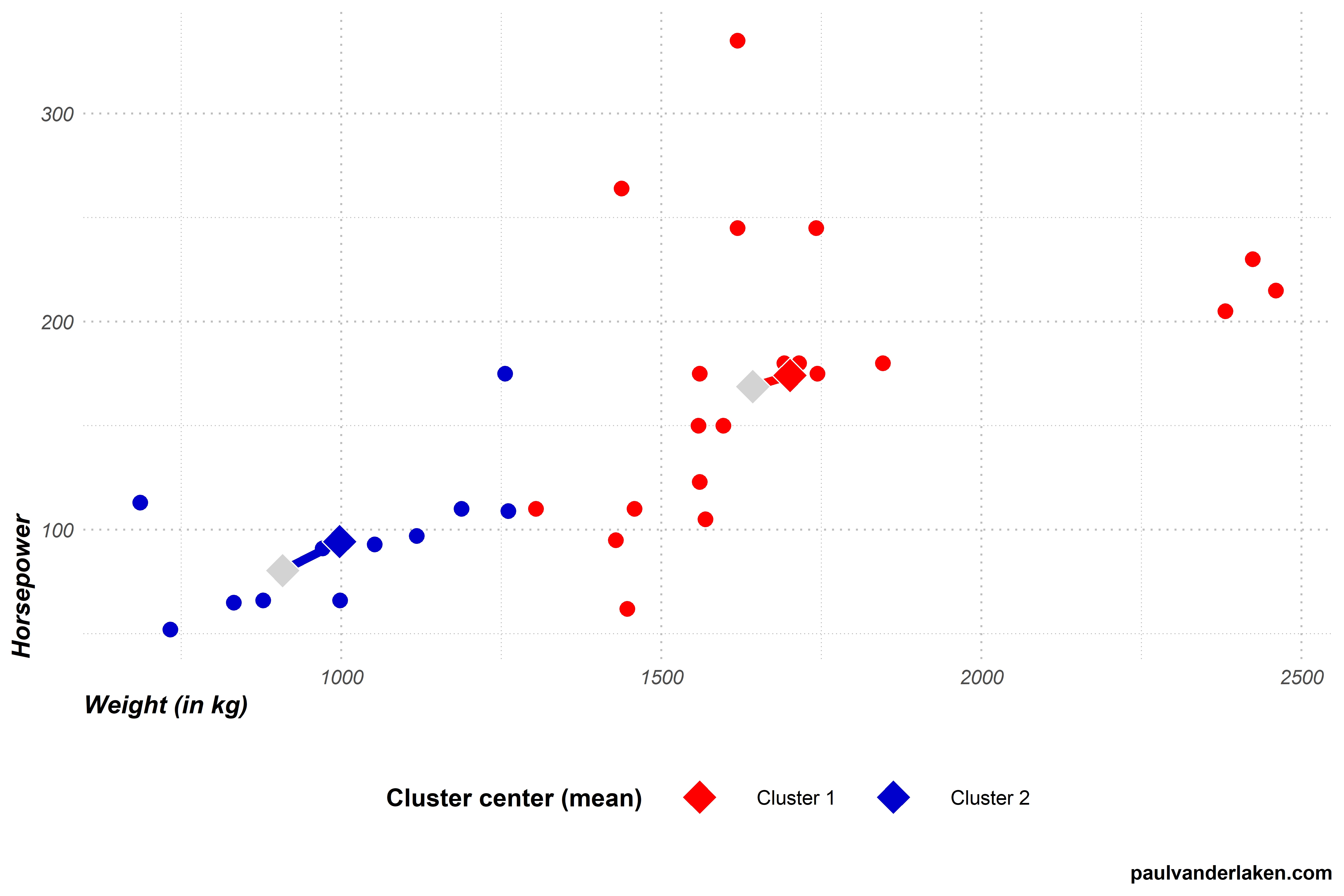
Step 3 (3nd time): Assignment to closest cluster
In step 3, the algorithm assigns every car in our dataset to the cluster whose center is nearest. To do this, the algorithm looks at every car, one by one, and calculates its distance to each of our cluster centers. As our cluster centers have been updated in the previous step 4, so too will their distances to the cars.
After calculating the distances, step 3 is once again completed by assigning the observations to their closest clusters. Another car moved from the blue cluster 2 to the red cluster 1, highlighted in yellow with an exclamation mark.
Step 4 (3rd time): Update the cluster centers
In step 4, the algorithm updates the cluster centers. For each cluster, it looks at the values of the observations assigned to it, and calculates the mean for every variable.
For cluster 1, both the average weight and the average horsepower have again increased slightly due to the newly assigned car. The cluster center moves from approximately [998; 94] to [1023; 96].
Cluster 2 lost a car from its cluster, but it was on the lower end of its range. Hence, its average weight and horsepower have also increased, moving the cluster center from approximately [1701; 174] to [1721; 177].
With the renewed cluster centers, step 4 is once again completed. Visually, the situation looks as follows, with the old centers in grey.
Step 5 (3rd): Terminate or go back to step 3.
In step 5, the k-means algorithm will again conclude that it is not yet done. The cluster centers have both moved once more, due to one car changing from cluster 2 to cluster 1 in step 3 (3rd time). Hence, the algorithm returns to step 3 for a fourth, but fortunately final, time.
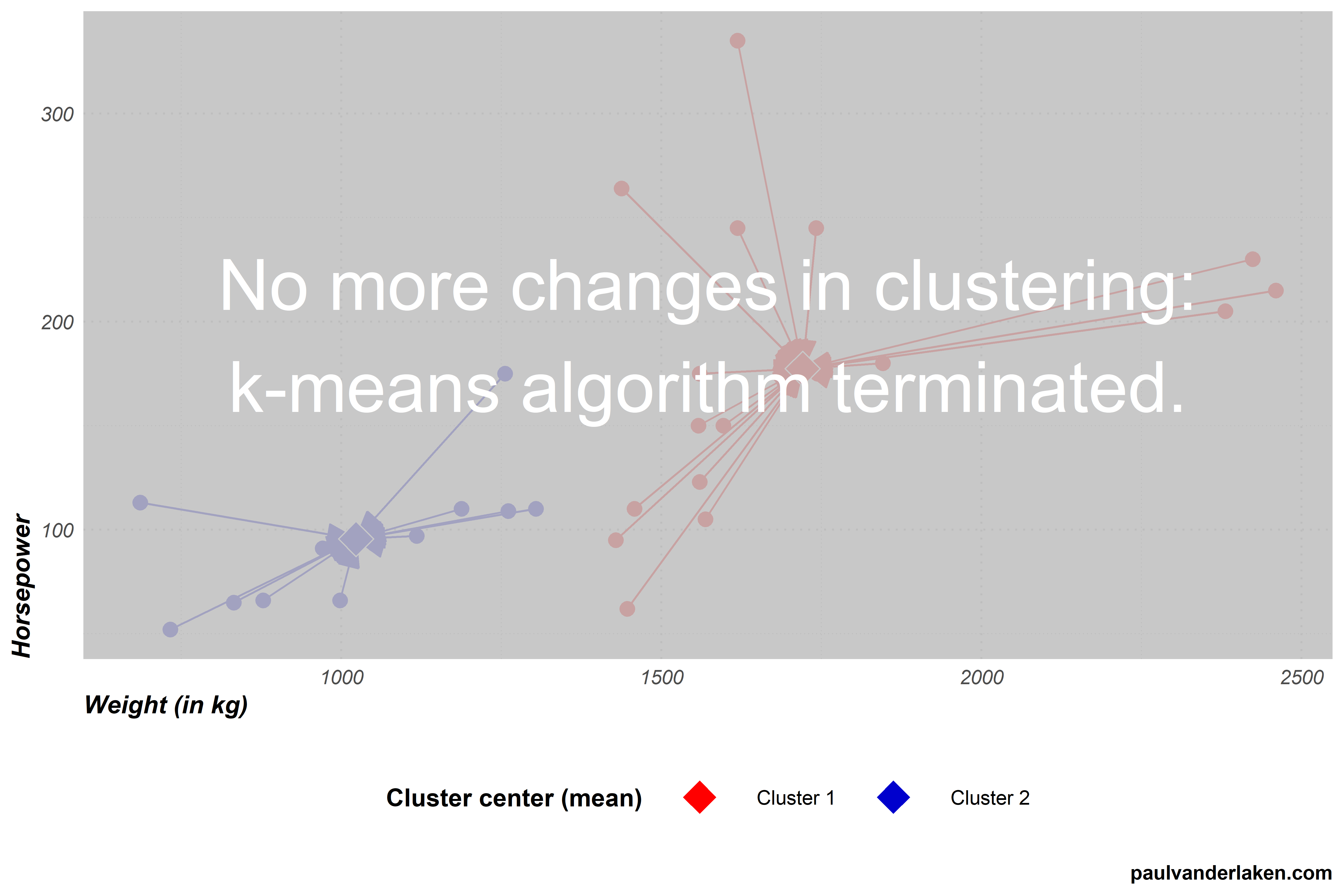
Step 3 (4th time): Assignment to closest cluster
In step 3, the k-means algorithm assigns every car in our dataset to the cluster whose center is nearest. Our cluster centers have only changed slightly in the previous step 4, and thus the distances are nearly similar to last time. Hence, this is the first time the algorithm completes step 3 without having to reassign observations to clusters. We thus know the algorithm will terminate the next time it checks for cluster changes.
Step 4 (4th time): Update the cluster centers
In step 4, the k-means algorithm tries to update the cluster centers. However, no observations moved clusters in step 3 so there is nothing to update.
Step 5 (4th): Terminate or go back to step 3.
As no changes occured to our cluster centers, the algorithm now concludes that it has reached the optimal clustering and terminates.
The clustering solution
With the clustering now completed, we can try to make some sense of the clusters the k-means algorithm produced.
For instance, we can examine how the observations included in each cluster vary on our variables. The density plot below is an example how we could go about exploring what the clusters represent.
We can clearly see what the clusters are made up of.
Cluster 1 holds most of the cars with low horsepower, and nearly all of those with low weights.
Cluster 2, in contrast, includes cars with horsepower ranging from low through high, and all cars are relatively heavy.
We could thus name our clusters respecitvively low horsepower and low weight cars, for cluster 1, and medium to high weight cars, for cluster 2.
Obviously, these clustering solutions will become more interesting as we add more clusters, and more variables to seperate our clusters and observations on.
A word of caution regarding k-means
Normalized input data
In our car clustering example, particularly the weight of cars seemed to be an important discriminating characteristic.
This is largely due to the fact that we didn’t normalize our data before running the k-means algorithm. I explicitly didn’t normalize (wiki) for simplicity sake and didactic purposes.
However, using k-means with raw data is actually a really easily-made but impactful mistake! Not normalizing data will cause k-means to put relative much importance on variables with a larger variance. Such as our variable weight. Cars’ weights ranged from a low 686 kg, to a high 2460 kg, thus spreading almost 1800 units. In contrast, horsepower ranged only from 52 hp to 335 hp, thus spreading less than 300 units.
If not normalized, this larger variation among weight values will cause the calculated Euclidean distance to be much more strongly affected by the weights of cars. Hence, these car weights will thus more strongly determine the final clustering solution simply because of their unit of measurement. In order to align the units of measurement for all variables, you should thus normalize your data before running k-means.
No categorical data
The need to normalize input data before running the k-means algorithm also touches on a second important characteristic of k-means: it does not handle categorical data.
Categorical data is discrete, and doesn’t have a natural origin. For instance, car color is a categorical variable. Cars can be blue, yellow, pink, or black. You can really calculate Euclidean distances for such data, at least not in a meaningful way. How far is blue from yellow, further or closer than it is from black?
Fortunately, there are variations of k-means that can handle categorical data, for instance, the k-modes algorithm.
No garuantees
The k-means algorithm does not guarantee to find the optimal solution. k-means is a fairly simple sequence of tasks and its clustering quality depends a lot on two factors.
First, the k specified by the user. In our example, we arbitrarily picked k = 2. This makes the algorithm seek specifically for solutions with two clusters, whereas maybe 3- or 4-cluster solutions would have made more sense.
Sometimes, users will have good theories to expect a certain number of clusters. At other times, they do not and are left to guess and experiment.
While there are methods to assess to some extent the statistically optimal number of clusters, often the decision for k will be somewhat subjective, though strongly affect the clustering solution..
Second, and more imporant maybe, is the influence of the random starting points for the initial cluster centers picked by the algorithm itself.
The clustering solutions that the algorithm produces are very sensitive to these initial conditions.
Due to its random starting points, it is also very likely that every time you run the k-means algorithm you will get different results, even on the same dataset.
To illustrate this, I ran the k-means visualization algorithm I wrote run a dozen of times.
Below is solution number 3 to which the k-means algorithm converged for our cars dataset. You can see that this is different from our earlier solution where the car at [1450; 270] belonged to the blue cluster 2, whereas here it is assigned to the red cluster 1.
Most k-means algorithms I ran on this dataset of cars resulted in approximately the same solution, like the one above and the one we saw before.
However, the k-means algorithm also produced some very different solutions. Like the one below, number 9. In this case cluster 2 was randomly initiated very muhc on the high end of the weight spectrum. As a result, the cluster 2 center remained all the way on the right side of the graph throughout the iterations of the algorithm.
Or this take this long-lasting iteration, where the k-means algorithm randomly located both cluster centers all the way in the bottom left corner, but fortunately recovered to the same solution we saw before.
One the one hand, the k-means algorithm sequences above illustrate the danger and downside of the k-means algorithm employing its random starting points. On the other hand, the mostly similar solutions produced even by the vanilla algorithm illustrate how the fantasticly simple algorithm is quite sturdy. Moreover, many smart improvements have fortunately been developed to avoid the random stupidity produced by the default algorithm — most notably the k-means++ algorithm (wiki). With these improvements, k-means continues to be one of the simplest though most popular and effective clustering algorithms out there!
Thanks for reading this blog!
While I intended to only share the link to the interactive visualization, I got carried away and ended up simulating the whole thing myself. Hopefully it wasn’t time wasted, and you learned a thing or two
Do reach out if you want to know more or are interested in the code to generate these simulations and visuals. Also, feel free to comment on, forward, or share any of the contents!
The cars dataset you can access in R by calling mtcars directly in your R console. Do explore it, as it contains many more variables on these 32 cars.
Some additional k-means resources
Here are some pages you can browse if you’re looking to learn more.
ggplot2 uses a more concise setup toward creating charts as opposed to the more declarative style of Python’s matplotlib and base R. And it also includes a few example datasets for practicing ggplot2 functionality; for example, the mpg dataset is a dataset of the performance of popular models of cars in 1998 and 2008.
Let’s say you want to create a scatter plot. Following a great example from the ggplot2 documentation, let’s plot the highway mileage of the car vs. the volume displacement of the engine. In ggplot2, first you instantiate the chart with the ggplot() function, specifying the source dataset and the core aesthetics you want to plot, such as x, y, color, and fill. In this case, we set the core aesthetics to x = displacement and y = mileage, and add a geom_point() layer to make a scatter plot:
p <- ggplot(mpg, aes(x = displ, y = hwy))+
geom_point()
As we can see, there is a negative correlation between the two metrics. I’m sure you’ve seen plots like these around the internet before. But with only a couple of lines of codes, you can make them look more contemporary.
ggplot2 lets you add a well-designed theme with just one line of code. Relatively new to ggplot2 is theme_minimal(), which generates a muted style similar to FiveThirtyEight’s modern data visualizations:
p <- p +
theme_minimal()
But we can still add color. Setting a color aesthetic on a character/categorical variable will set the colors of the corresponding points, making it easy to differentiate at a glance.
p <- ggplot(mpg, aes(x = displ, y = hwy, color=class))+
geom_point()+
theme_minimal()
Adding the color aesthetic certainly makes things much prettier. ggplot2 automatically adds a legend for the colors as well. However, for this particular visualization, it is difficult to see trends in the points for each class. A easy way around this is to add a least squares regression trendline for each class usinggeom_smooth() (which normally adds a smoothed line, but since there isn’t a lot of data for each group, we force it to a linear model and do not plot confidence intervals)
p <- p +
geom_smooth(method ="lm", se =F)
Pretty neat, and now comparative trends are much more apparent! For example, pickups and SUVs have similar efficiency, which makes intuitive sense.
The chart axes should be labeled (always label your charts!). All the typical labels, like title, x-axis, and y-axis can be done with the labs() function. But relatively new to ggplot2 are the subtitle and caption fields, both of do what you expect:
p <- p +
labs(title="Efficiency of Popular Models of Cars",
subtitle="By Class of Car",
x="Engine Displacement (liters)",
y="Highway Miles per Gallon",
caption="by Max Woolf — minimaxir.com")
That’s a pretty good start. Now let’s take it to the next level.
HOW TO SAVE A GGPLOT2 CHART FOR WEB
Something surprisingly undiscussed in the field of data visualization is how to save a chart as a high quality image file. For example, with Excel charts, Microsoft officially recommends to copy the chart, paste it as an image back into Excel, then save the pasted image, without having any control over image quality and size in the browser (the real best way to save an Excel/Numbers chart as an image for a webpage is to copy/paste the chart object into a PowerPoint/Keynote slide, and export the slideas an image. This also makes it extremely easy to annotate/brand said chart beforehand in PowerPoint/Keynote).
R IDEs such as RStudio have a chart-saving UI with the typical size/filetype options. But if you save an image from this UI, the shapes and texts of the resulting image will be heavily aliased (R renders images at 72 dpi by default, which is much lower than that of modern HiDPI/Retina displays).
The data visualizations used earlier in this post were generated in-line as a part of an R Notebook, but it is surprisingly difficult to extract the generated chart as a separate file. But ggplot2 also has ggsave(), which saves the image to disk using antialiasing and makes the fonts/shapes in the chart look much better, and assumes a default dpi of 300. Saving charts using ggsave(), and adjusting the sizes of the text and geoms to compensate for the higher dpi, makes the charts look very presentable. A width of 4 and a height of 3 results in a 1200x900px image, which if posted on a blog with a content width of ~600px (like mine), will render at full resolution on HiDPI/Retina displays, or downsample appropriately otherwise. Due to modern PNG compression, the file size/bandwidth cost for using larger images is minimal.
p <- ggplot(mpg, aes(x = displ, y = hwy, color=class))+
geom_smooth(method ="lm", se=F, size=0.5)+
geom_point(size=0.5)+
theme_minimal(base_size=9)+
labs(title="Efficiency of Popular Models of Cars",
subtitle="By Class of Car",
x="Engine Displacement (liters)",
y="Highway Miles per Gallon",
caption="by Max Woolf — minimaxir.com")
ggsave("tutorial-0.png", p, width=4, height=3)
Compare to the previous non-ggsave chart, which is more blurry around text/shapes:
For posterity, here’s the same chart saved at 1200x900px using the RStudio image-saving UI:
Note that the antialiasing optimizations assume that you are not uploading the final chart to a service like Medium or WordPress.com, which will compress the images and reduce the quality anyways. But if you are uploading it to Reddit or self-hosting your own blog, it’s definitely worth it.
FANCY FONTS
Changing the chart font is another way to add a personal flair. Theme functions like theme_minimal()accept a base_family parameter. With that, you can specify any font family as the default instead of the base sans-serif. (On Windows, you may need to install the extrafont package first). Fonts from Google Fonts are free and work easily with ggplot2 once installed. For example, we can use Roboto, Google’s modern font which has also been getting a lot of usage on Stack Overflow’s great ggplot2 data visualizations.
p <- p +
theme_minimal(base_size=9, base_family="Roboto")
A general text design guideline is to use fonts of different weights/widths for different hierarchies of content. In this case, we can use a bolder condensed font for the title, and deemphasize the subtitle and caption using lighter colors, all done using the theme()function.
p <- p +
theme(plot.subtitle = element_text(color="#666666"),
plot.title = element_text(family="Roboto Condensed Bold"),
plot.caption = element_text(color="#AAAAAA", size=6))
It’s worth nothing that data visualizations posted on websites should be easily legible for mobile-device users as well, hence the intentional use of larger fonts relative to charts typically produced in the desktop-oriented Excel.
Additionally, all theming options can be set as a session default at the beginning of a script using theme_set(), saving even more time instead of having to recreate the theme for each chart.
THE “GGPLOT2 COLORS”
The “ggplot2 colors” for categorical variables are infamous for being the primary indicator of a chart being made with ggplot2. But there is a science to it; ggplot2 by default selects colors using the scale_color_hue()function, which selects colors in the HSL space by changing the hue [H] between 0 and 360, keeping saturation [S] and lightness [L] constant. As a result, ggplot2 selects the most distinct colors possible while keeping lightness constant. For example, if you have 2 different categories, ggplot2 chooses the colors with h = 0 and h = 180; if 3 colors, h = 0, h = 120, h = 240, etc.
It’s smart, but does make a given chart lose distinctness when many other ggplot2 charts use the same selection methodology. A quick way to take advantage of this hue dispersion while still making the colors unique is to change the lightness; by default, l = 65, but setting it slightly lower will make the charts look more professional/Bloomberg-esque.
p_color <- p +
scale_color_hue(l =40)
RCOLORBREWER
Another coloring option for ggplot2 charts are the ColorBrewer palettes implemented with the RColorBrewer package, which are supported natively in ggplot2 with functions such as scale_color_brewer(). The sequential palettes like “Blues” and “Greens” do what the name implies:
p_color <- p +
scale_color_brewer(palette="Blues")
A famous diverging palette for visualizations on /r/dataisbeautiful is the “Spectral” palette, which is a lighter rainbow (recommended for dark backgrounds)
However, while the charts look pretty, it’s difficult to tell the categories apart. The qualitative palettes fix this problem, and have more distinct possibilities than the scale_color_hue() approach mentioned earlier.
Here are 3 examples of qualitative palettes, “Set1”, “Set2”, and “Set3,” whichever fit your preference.
VIRIDIS AND ACCESSIBILITY
Let’s mix up the visualization a bit. A rarely-used-but-very-useful ggplot2 geom is geom2d_bin(), which counts the number of points in a given 2d spatial area:
p <- ggplot(mpg, aes(x = displ, y = hwy))+
geom_bin2d(bins=10)+[...theming options...]
We see that the largest number of points are centered around (2,30). However, the default ggplot2 color palette for continuous variables is boring. Yes, we can use the RColorBrewer sequential palettes above, but as noted, they aren’t perceptually distinct, and could cause issues for readers who are colorblind.
The viridis R package provides a set of 4 high-contrast palettes which are very colorblind friendly, and works easily with ggplot2 by extending a scale_fill_viridis()/scale_color_viridis() function.
The default “viridis” palette has been increasingly popular on the web lately:
p_color <- p +
scale_fill_viridis(option="viridis")
“magma” and “inferno” are similar, and give the data visualization a fiery edge:
Lastly, “plasma” is a mix between the 3 palettes above:
If you’ve been following my blog, I like to use R and ggplot2 for data visualization. A lot.
FiveThirtyEight actually uses ggplot2 for their data journalism workflow in an interesting way; they render the base chart using ggplot2, but export it as as a SVG/PDF vector file which can scale to any size, and then the design team annotates/customizes the data visualization in Adobe Illustrator before exporting it as a static PNG for the article (in general, I recommend using an external image editor to add text annotations to a data visualization because doing it manually in ggplot2 is inefficient).
For general use cases, ggplot2 has very strong defaults for beautiful data visualizations. And certainly there is a lot more you can do to make a visualization beautiful than what’s listed in this post, such as using facets and tweaking parameters of geoms for further distinction, but those are more specific to a given data visualization. In general, it takes little additional effort to make something unique with ggplot2, and the effort is well worth it. And prettier charts are more persuasive, which is a good return-on-investment.
Max Woolf (@minimaxir) is a former Apple Software QA Engineer living in San Francisco and a Carnegie Mellon University graduate. In his spare time, Max uses Python to gather data from public APIs and ggplot2 to plot plenty of pretty charts from that data. You can learn more about Max here, view his data analysis portfolio here, or view his coding portfolio here.