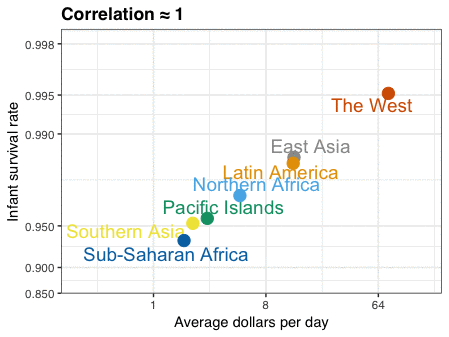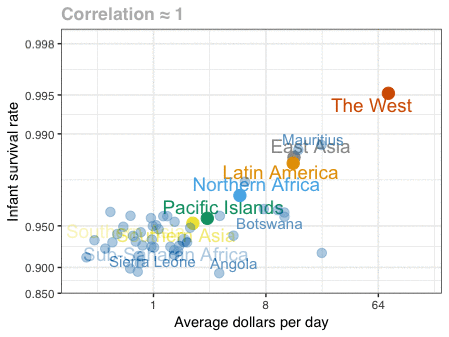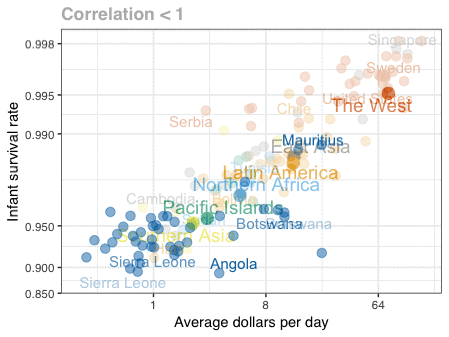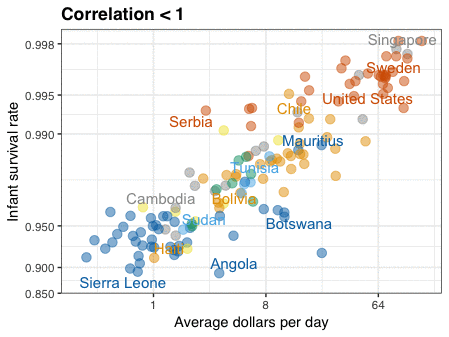
Patrick Winston was a professor of Artificial Intelligence at MIT. Having taught with great enthusiasm for over 50 years, he passed away past June.
As a speaker [Patrick] always had his audience in the palm of his hand. He put a tremendous amount of work into his lectures, and yet managed to make them feel loose and spontaneous. He wasn’t flashy, but he was compelling and direct.
Peter Szolovits via http://news.mit.edu/2019/patrick-winston-professor-obituary-0719
I’ve written about Patrick’s MIT course on Artificial Intelligence before, as all 20+ lectures have been shared open access online on Youtube. I’ve worked through the whole course in 2017/2018, and it provided me many new insights into the inner workings of common machine learning algorithms.
Now, I stumbled upon another legacy of Patrick that has been opened up as of December 20th 2019. A lecture on “How to Speak” – where Patrick explains what he think makes a talk enticing, inspirational, and interesting.
Patrick Winston’s How to Speak talk has been an MIT tradition for over 40 years. Offered every January, the talk is intended to improve your speaking ability in critical situations by teaching you a few heuristic rules.
https://ocw.mit.edu/resources/res-tll-005-how-to-speak-january-iap-2018/
That’s all I’m going to say about it, you should have a look yourself! If you don’t apply these techniques yet, do try them out, they will really upgrade your public speaking effectiveness: