For those of you unfamiliar with the tidyverse, it is a collection of R packages that share common philosophies and are designed to work together. Most if not all, are created by R-god Hadley Wickham, one of the leads at RStudio. I was introduced to the tidyverse-packages such as ggplot2 and dplyr in my second R-course, and they have cleaned and sped up my workflow tremendously ever since.
Although I don’t want to mix in the political debate, I came across such a wonderful example of how the tidyverse has simplified coding in R. On the downside, those unfamiliar with the syntax have trouble understanding what happens in the code the author uses.
Running the following R-code will install the core packages of the tidyverse:
install.packages(‘tidyverse’)
These consist among others of the following:
ggplot2: a more potent way of visualizationtibble: an upgrade to the standarddata.framedplyr: adds great new functionality for manipulating data framestidyr: adds even more new functions for wrangling data framesmagrittr: adds piping functionality to improve code readability and workflowreadr: provides easier functions to load in datapurr: adds new functional programming functionality
There are several other packages included (e.g, stringr), but the above are the ones you are most likely to use in everyday projects.
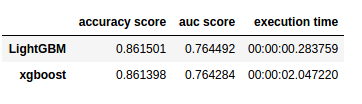
Now, how about dissecting the code in the post. The author (1) loads some functionality in R, (2) scrapes data on approval rates from the web, (3) cleans it up, and creates a wonderful visualization. S/He does this all in only 35 lines of code! Better even, 2 of these code lines are blank, 3 are setup, 6 have aesthetic purposes, and many others could be combined being only several characters long. Due to the tidyverse syntax, the code is easy to read, transparent, and reproducible (it only consists of two chained code blocks, after loading the packages), and takes only 7 seconds to run!
user system elapsed 5.67 0.85 6.53
In the rest of this article, I walk you through the code of this post to explain what’s happening:
hrbrthemesincludes additionalggplot2themes (plot colors, etc.)rvestincludes functionalities for web scrapingtidyversewe discussed earlier
library(hrbrthemes) library(rvest) library(tidyverse)
Below, the author then creates a list containing the links to the online data to scrape and run it through a magrittr pipe (%>%) to apply the next bit of code to it.
map_df() comes from the purrr package and applies the subsequent code to every element in the earlier list:
- Read in the html files specified earlier in the list %>%
- Convert them to a table %>%
- Store the name of the list (this is the name of the president) as .id %>%
- Store that as a data.frame %>%
- Select columns (and rename them) %>%
- Use the earlier stored president id and add it as a column (‘who’) %>%
- Save the output as a dataframe called ratings.
list(
Obama="http://m.rasmussenreports.com/public_content/politics/obama_administration/obama_approval_index_history",
Trump="http://m.rasmussenreports.com/public_content/politics/trump_administration/trump_approval_index_history"
) %>%
map_df(~{
read_html(.x) %>%
html_table() %>%
.[[1]] %>%
tbl_df() %>%
select(date=Date, approve=`Total Approve`, disapprove=`Total Disapprove`)
}, .id="who") -> ratings
Below, the author then starts a new chained code block. S/He first changes (mutate()), from the ratings dataframe, the approval & disapproval data with a custom function (get rid of the % sign and divide by 100), which is then piped through:
- Mutate dates to a data format (
lubridateis yet another tidyverse package) %>% - Filter out any missing values %>%
- Group by the ‘who’-column (President name) %>%
- Sort the data file by earlier specified date %>%
- Give every line an id number, from 1 up to the number of records (
n()returns the sample size per President due to the earliergroup_by()) %>% - Ungroup the data %>%
For readability, I split the code here, but it actually still continues as depicted by the %>% at the end.
mutate_at(ratings, c("approve", "disapprove"), function(x) as.numeric(gsub("%", "", x, fixed=TRUE))/100) %>%
mutate(date = lubridate::dmy(date)) %>%
filter(!is.na(approve)) %>%
group_by(who) %>%
arrange(date) %>%
mutate(dnum = 1:n()) %>%
ungroup() %>%
The output is now entered into the ggplot2 visualization function below:
ggplot()creates a layered plot, where the aes(thetics) (parameters) are defined as- x = the id number,
- y = the approval rate,
- and the color = the President name
Layers and details to this plot are specified/added using +
- The first (bottom) layer of the plot is
geom_hline()which creates a horizontal line at [x = 0; y = 0.5] with a size = 0.5. + - The 2nd layer is a scatterplot as
geom_point()adds points with size = 0.25 on the x & y predefined inggplot(aes())+ - Next the limits of the Y-axis are set to run from 0 to 1 +
- A custom/manual color scheme is set +
- Custom titles and labels are applied to the axis +
- A predefined theme for the plot is used, drawn from hrbrthemes-package loading in at the start +
- The direction of the legend is set +
- The position of the legend is set
ggplot(aes(dnum, approve, color=who)) +
geom_hline(yintercept = 0.5, size=0.5) +
geom_point(size=0.25) +
scale_y_percent(limits=c(0,1)) +
scale_color_manual(name=NULL, values=c("Obama"="#313695", "Trump"="#a50026")) +
labs(x="Day in office", y="Approval Rating",
title="Presidential approval ratings from day 1 in office",
subtitle="For fairness, data was taken solely from Trump's favorite polling site (Ramussen)",
caption="Data Source: \nCode: ") +
theme_ipsum_rc(grid="XY", base_size = 16) +
theme(legend.direction = "horizontal") +
theme(legend.position=c(0.8, 1.05))
Theggplot()command at the start automatically prints the plot when it is finished (when no more + is found). The result is just wonderful, isn’t it? With only 35 lines, 2 chained commands, and 7 seconds runtime.

Found on https://www.r-bloggers.com.