Google Brain researchers published this amazing paper, with accompanying GIF where they show the true power of AutoML.
AutoML stands for automated machine learning, and basically refers to an algorithm autonomously building the best machine learning model for a given problem.
This task of selecting the best ML model is difficult as it is. There are many different ML algorithms to choose from, and each of these has many different settings ([hyper]parameters) you can change to optimalize the model’s predictions.
For instance, let’s look at one specific ML algorithm: the neural network. Not only can we try out millions of different neural network architectures (ways in which the nodes and lyers of a network are connected), but each of these we can test with different loss functions, learning rates, dropout rates, et cetera. And this is only one algorithm!
In their new paper, the Google Brain scholars display how they managed to automatically discover complete machine learning algorithms just using basic mathematical operations as building blocks. Using evolutionary principles, they have developed an AutoML framework that tailors its own algorithms and architectures to best fit the data and problem at hand.
This is AI research at its finest, and the results are truly remarkable!
I recently got pointed towards a 2017 paper on bioRxiv that blew my mind: three researchers at the Computational Neuroscience Laboratories at Kyoto, Japan, demonstrate how they trained a deep neural network to decode human functional magnetic resonance imaging (fMRI) patterns and then generate the stimulus images.
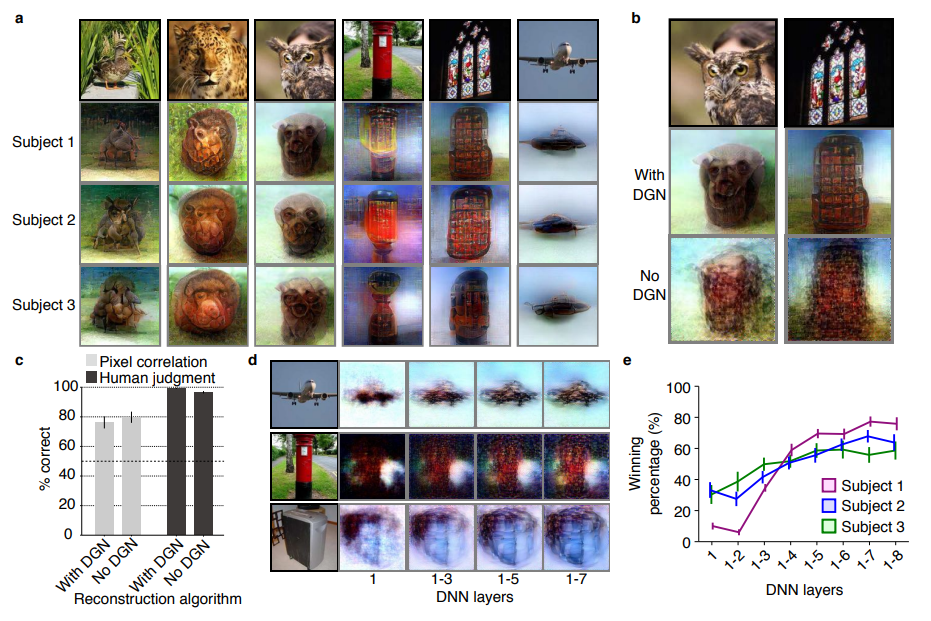
In simple words, the scholars used sophisticated machine learning to reconstruct the photo’s their research particpants saw based on their brain activity… INSANE! The below shows the analysis workflow, and an actual reconstructed image. More reconstructions follow further on.
Figure 1 | Deep image reconstruction. Overview of deep image reconstruction is shown. The pixels’ values of the input image are optimized so that the DNN features of the image are similar to those decoded from fMRI activity. A deep generator network (DGN) is optionally combined with the DNN to produce natural-looking images, in which optimization is performed at the input space of the DGN. [original]Three healthy young adults participated in two types of experiments: an image presentation experiment and an imagery experiment.
In the image presentation experiments, participants were presented with several natural images from the ImageNet database, with 40 images geometrical shapes, and with 10 images of black alphabetic characters. These visual stimuli were rear-projected onto a screen in an fMRI scanner bore. Data from each subject were collected over multiple scanning sessions spanning approximately 10 months. Images were flashed at 2 Hz for several seconds. In the imagery experiment, subjects were asked to visually imagine / remember one of 25 images of the presentation experiments. Subjects were
required to start imagining a target image after seeing some cue words.
In both experimental setups, fMRI data were collected using 3.0-Tesla Siemens MAGNETOM Verio scanner located at the Kokoro Research Center, Kyoto University.
The results, some of which I copied below, are plainly amazing.
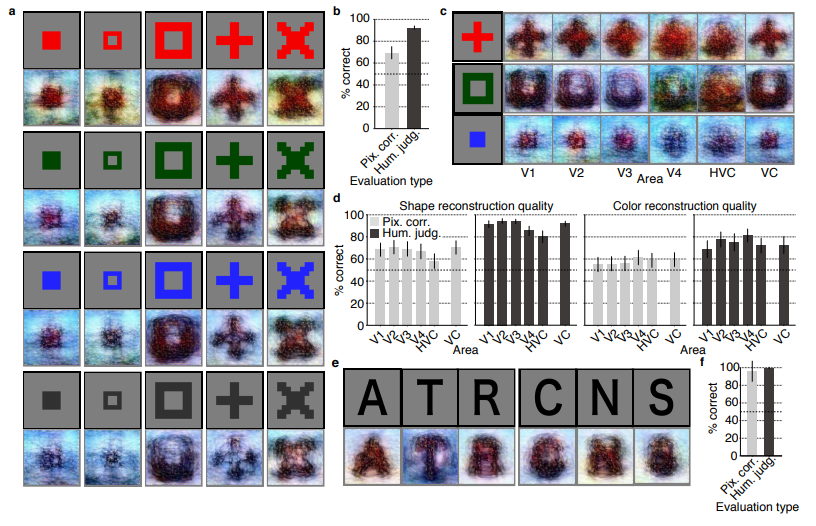
Figure 2 | Seen natural image reconstructions. Images with black and gray frames show presented and reconstructed images, respectively (reconstructed from VC activity). a) Reconstructions utilizing the DGN (using DNN1–8). Three reconstructed images correspond to reconstructions from three subjects. b) Reconstructions with and without the DGN (DNN1–8). The first, second, and third rows show presented images, reconstructions with and without the DGN, respectively. c) Reconstruction quality of seen natural images (error bars, 95% confidence interval (C.I.) across samples; three subjects pooled; chance level, 50%). d) Reconstructions using different combinations of DNN layers (without the DGN). e) Subjective assessment of reconstructions from different combinations of DNN layers (error bars, 95% C.I. across samples) [original]Figure 3 | Seen artificial shape reconstructions. Images with black and gray frames show presented and reconstructed images (DNN 1–8, without the DGN). a) Reconstructions for seen colored artificial shapes (VC activity). b, Reconstruction quality of colored artificial shapes. c) Reconstructions of colored artificial shapes obtained from multiple visual areas. d) Reconstruction quality of shape and colors for different visual areas. e) Reconstructions of alphabetical letters. f) Reconstruction quality for alphabetical letters. For b, d, f, error bars indicate 95% C.I. across samples (three subjects pooled; chance level, 50%) [original] Supplementary Figure 2 | Other examples of natural image reconstructions obtained with the DGN. Images with black and gray frames show presented and reconstructed images, respectively (reconstructed from VC activity using all DNN layers). Three reconstructed images correspond to reconstructions from three subjects. [original]Supplementary Figure 3 | Reconstructions through optimization processes. Reconstructed images obtained through the optimization processes are shown (reconstructed from VC activity of Subject 1 using all DNN layers and the DGN). Images with black and gray frames show presented and reconstructed images, respectively. [original]There were many more examples of reconstructed images, as well as much more detailed information regarding the machine learning approach and experimental setup, so I strongly advise you check out the orginal paper.
I can’t even imagine what such technology would imply for society… Proper minority report stuff here.
Here’s the abstract as an additional teaser:
Abstract
Machine learning-based analysis of human functional magnetic resonance imaging
(fMRI) patterns has enabled the visualization of perceptual content. However, it has been limited to the reconstruction with low-level image bases (Miyawaki et al., 2008; Wen et al., 2016) or to the matching to exemplars (Naselaris et al., 2009; Nishimoto et al., 2011). Recent work showed that visual cortical activity can be decoded (translated) into hierarchical features of a deep neural network (DNN) for the same input image, providing a way to make use of the information from hierarchical visual features (Horikawa & Kamitani, 2017). Here, we present a novel image reconstruction method, in which the pixel values of an image are optimized to make its DNN features similar to those decoded from human brain activity at multiple layers. We found that the generated images resembled the stimulus images (both natural images and artificial shapes) and the subjective visual content during imagery. While our model was solely trained with natural images, our method successfully generalized the reconstruction to artificial shapes, indicating that our model indeed ‘reconstructs’ or ‘generates’ images from brain activity, not simply matches to exemplars. A natural image prior introduced by another deep neural network effectively rendered semantically meaningful details to reconstructions by constraining reconstructed images to be similar to natural images. Furthermore, human judgment of reconstructions suggests the effectiveness of combining multiple DNN layers to enhance visual quality of generated images. The results suggest that hierarchical visual information in the brain can be effectively combined to reconstruct perceptual and subjective images.