
This blog highlights a recent PNAS paper in which 457 data scientists and academic scholars were challenged use machine learning to predict life outcomes using a rich dataset.
Yet, I can not summarize the result better than this tweet by the author of the paper:
Over 750 scientific papers have used the Fragile Families dataset.
The dataset is famous for its richness of cohort (survey) data on the included families’ lives and their childrens’ upbringings. It includes a whopping 12.942 variables!!
Some of these variables reflect interesting life outcomes of the included families.
For instance, the childrens’ grade point averages (GPA) and grit, but also whether the family was ever evicted or experienced hardship, or whether their primary caregiver had received job training or was laid off at work.
You can read more about the exact data contents in the paper’s appendix.

via pnas.org/content/pnas/117/15/8398/F1.medium.gif
Now Matthew and his co-authors shared this enormous dataset with over 160 teams consisting of 457 academics researchers and data scientists alike. Each of them well versed in statistics and predictive modelling.
These data scientists were challenged with this task: by all means possible, make the most predictive model for the six life outcomes (i.e., GPA, conviction, etc).
The scientists could use all the Fragile Families data, and any algorithm they liked, and their final model and its predictions would be compared against the actual life outcomes in a holdout sample.
According to the paper, many of these teams used machine-learning methods that are not typically used in social science research and that explicitly seek to maximize predictive accuracy.
Now, here’s the summary again:
If hundreds of [data] scientists created predictive algorithms with high-quality data, how well would the best predict life outcomes?
Not very well.
@msalganik
Even the best among the 160 teams’ predictions showed disappointing resemblance of the actual life outcomes. None of the trained models/algorithms achieved an R-squared of over 0.25.
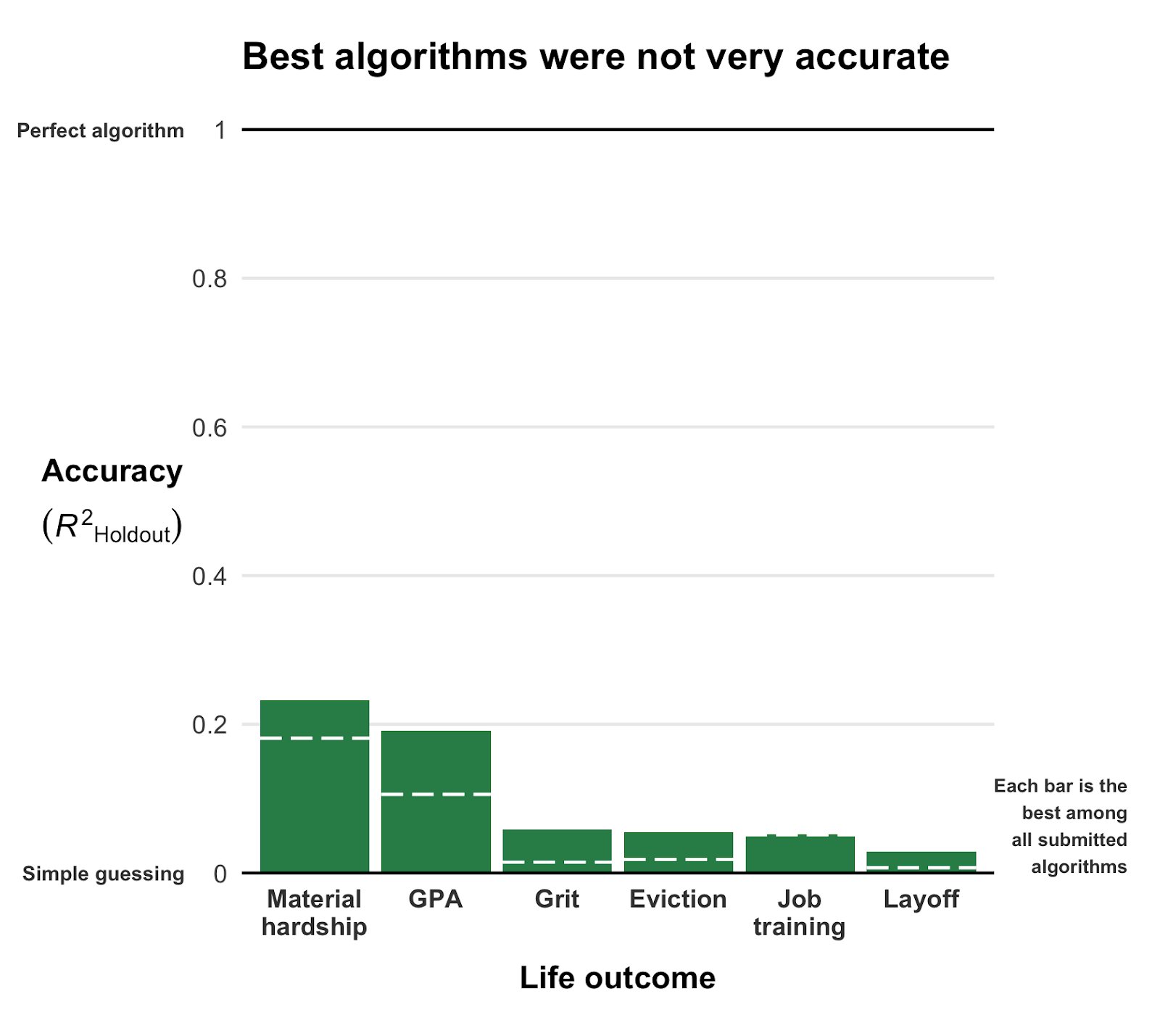
Here’s that same plot again, but from the original publication and with more detail:

Wondering what these best R-squared of around 0.20 look like? Here’s the disappointg reality of plot C enlarged: the actual TRUE GPA’s on the x-axis, plotted against the best team’s predicted GPA’s on the y-axis.
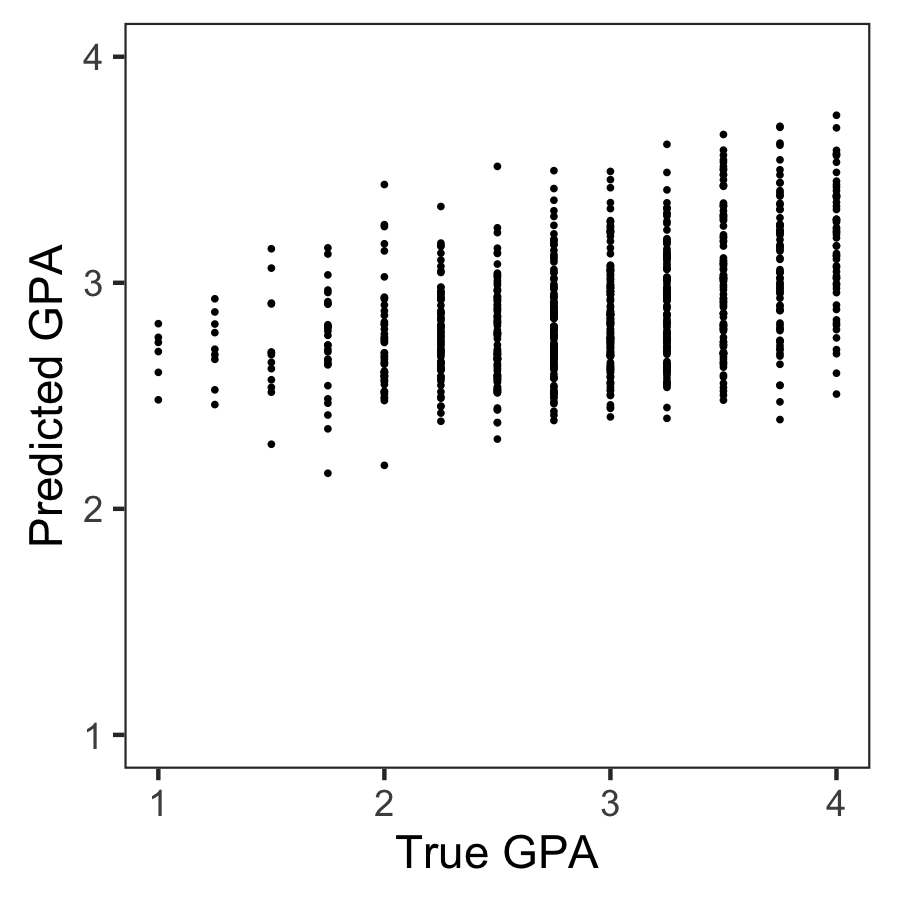
Sure, there’s some relationship, with higher actual scores getting higher (average) predictions. But it ain’t much.
Moreover, there’s very little variation in the predictions. They all clump together between the range of about 2.1 and 3.8… that’s not really setting apart the geniuses from the less bright!
Matthew sums up the implications quite nicely in one of his tweets:
For policymakers deploying predictive algorithms in high-stakes decisions, our result is a reminder of a basic fact: one should not assume that algorithms predict well. That must be demonstrated with transparent, empirical evidence.
@msalganik
According to Matthew this “collective failure of 160 teams” is hard to ignore. And it failure highlights the understanding vs. predicting paradox: these data have been used to generate knowledge on how the world works in over 750 papers, yet few checked to see whether these same data and the scientific models would be useful to predict the life outcomes we’re trying to understand.
I was super excited to read this paper and I love the approach. It is actually quite closely linked to a series of papers I have been working on with Brian Spisak and Brian Doornenbal on trying to predict which people will emerge as organizational leaders. (hint: we could not really, at least not based on their personality)
Apparently, others were as excited as I am about this paper, as Filiz Garip already published a commentary paper on this research piece. Unfortunately, it’s behind a paywall so I haven’t read it yet.
Moreover, if you want to learn more about the approaches the 160 data science teams took in modelling these life outcomes, here are twelve papers in which some teams share their attempts.
Very curious to hear what you think of the paper and its implications. You can access it here, and I’d love to read your comments below.







 Alternatively, scatterplots can be easily generated. Displaying missings at 10 percent below the minimum of the airquality dataset. Scatterplots of ozone and solar radiation (A), and ozone and temperature (B). These plots demonstrate that there are missings in ozone and solar radiation, but not in temperature.
Alternatively, scatterplots can be easily generated. Displaying missings at 10 percent below the minimum of the airquality dataset. Scatterplots of ozone and solar radiation (A), and ozone and temperature (B). These plots demonstrate that there are missings in ozone and solar radiation, but not in temperature.



