Google Brain researchers published this amazing paper, with accompanying GIF where they show the true power of AutoML.
AutoML stands for automated machine learning, and basically refers to an algorithm autonomously building the best machine learning model for a given problem.
This task of selecting the best ML model is difficult as it is. There are many different ML algorithms to choose from, and each of these has many different settings ([hyper]parameters) you can change to optimalize the model’s predictions.
For instance, let’s look at one specific ML algorithm: the neural network. Not only can we try out millions of different neural network architectures (ways in which the nodes and lyers of a network are connected), but each of these we can test with different loss functions, learning rates, dropout rates, et cetera. And this is only one algorithm!
In their new paper, the Google Brain scholars display how they managed to automatically discover complete machine learning algorithms just using basic mathematical operations as building blocks. Using evolutionary principles, they have developed an AutoML framework that tailors its own algorithms and architectures to best fit the data and problem at hand.
This is AI research at its finest, and the results are truly remarkable!
The following are my summary and take-aways from Janelle Shane’s 2019 book named You look like a thing and I love you. Most of the below are excerpts from Janelle’s book, combined, or rewritten by me. For the sake of copyright, just consider everything Janelle’s : )
AI weirdness
You look like a thing and I love you is about AI. More specifically, the book is about what AI can and can not do. And how and why AI often fails in miserably hilareous ways.
Janelle has spend her time foing fun experiments with AI. In this book, she shares those experiments along with many real life examples of AIs in practice. While explaining the technical details behind these AIs in an accesible though technically correct way, she informs the reader where, how, and why AIs fail.
Janelle took AIs out of their comfort zone and it produced some hilareously weird results. She proposes five principles of AI Weirdness:
The danger of AI is not that it’s too smart, but that it’s not smart enough
AI has the approximate brainpower of a worm
AI does not really understand the problem you want it to solve
But: AI will do exactly what you tell it to. Or at least it will try its best.
And AI willt ake the path of the least resistance
Definitions: What is (not) AI?
If it seems like AI is everywhere, it’s partly because Artificial Intelligence means lots of things, depending on whether you’re reading science fiction or selling a new app or doing academic research.
To spot an AI in the wild, it’s important to know the difference between machine learning algorithms (what Janelle calls AI in her book) and traditional, rules-based programs.
To solve a problem with a rules-based program, you have to know every step required to complete the program’s task and how to describe each one of those steps. But a machine learning algorithm figures out the rules for itself via trail and error, gauging its success on goals the programmer has specified. As the AI tries to reach this goal, it can discover rules and correlations that the programmer didn’t even know existed. This is what makes AIs attractive problem solvers and is particularly handy if the rules are really complicated or just plain mysterious.
Sometimes an AI’s brilliant problem-solving rules actually rely on mistaken assumptions. Rules that served it well in training but fail miserably when it encountered the real world. While training errors are common in complex AIs, the consequences of these mistakes can be serious.
It’s often not easy to tell when AIs make mistakes. Since we don’t write the rules, they come up with their own, and they don’t write them down or explain them the way a human would.
The difference between succesful AI problem solving and failure usually has a lot to do with the suitability of the task for an AI solution. And there are plenty of tasks for which AI solutions are more efficient than human solutions. But there are also plenty of cases where things go miserably wrong.
Janelle proposes four signs of “AI Doom”, contexts where machine learning will not produce the desired results:
The problem is too hard, broad, or complex
The problem is not what we thought it was
There are sneaky shortcuts to solving the problem
The AI tried to solve the problem learning from flawed data
Programming an AI is almost more like teaching a child than programming a computer.
Explaining how AI works
In her book, Janelle takes us through many example problems which she or others tried to solve using AIs. These example problems are increasingly hilareous, but I assure you that they are technically and didactically sound:
Playing tic-tac-toe
Managing a cockroach farm
Riding a bicycle
Rating sandwich deliciousness
Tossing a sandwich into a wall
Guiding people through a hallway
Answering questions regarding photo’s
Categorizing doodles
Categorizing fish
Tossing pancakes
Autonomous walking
Autonomous driving
Playing Pacman
The amazing thing is these ridiculous example problems actually serve a purpose. They are used to explain different algorithms and their applications, strengths, and limitations! Janelle covers a wide variety of algorithms in such a way that anyone new to machine learning would understand, while people with some experience will still be amused.
Janelle talks about artificial neural networks, random forests, and markov chains. Moreover, she explains how activation functions, recurrancy and long short-term memory, evolutionary algorithms and gradient descent work. And all in understandable though technically correct language.
Janelle herself seems particularly fond of generative algorithms. She’s elaborates on having deployed recurrent neural nets, generative adversial networks, and markov chains for a wide variety of generative tasks. In the book, Jabekke explains what went well and went wrong when coming up with new and original…
Janelle’s book is lingered with examples of failing AI. As a matter of fact, the whole book seems like an ode to how machine learning can and will inevitably fail. Particularly in the latter chapters, Janelle covers many limitations of and issues with AI in much detail:
I have yet to come across a book that explain AI in this much detail and in a manner as accessible and entertaining as Janelle Shane does in You look like a thing and I love you. Janelle makes machine learning and AI understandable for a wide public without passing on the deeper technical details. Taking a critical stance, she provides a good overview of the strenghts and weaknesses of AI, and a realistic outlook for the future to come. This book is not looking for sensation or hype, although reading it will be a most amusing experience for the more technical as well as the lay reader.
I highly recommend you reward yourself with a copy!
Past days, I discovered this series of blogs on how to win the classic game of Battleships (gameplay explanation) using different algorithmic approaches. I thought they might amuse you as well : )
The story starts with this 2012 Datagenetics blog where Nick Berry constrasts four algorithms’ performance in the game of Battleships. The resulting levels of artificial intelligence (AI) seem to compare respectively to a distracted baby, two sensible adults, and a mathematical progidy.
The first, stupidest approach is to just take Random shots. The AI resulting from such an algorithm would just pick a random tile to shoot at each turn. Nick simulated 100 million games with this random apporach and computed that the algorithm would require 96 turns to win 50% of games, given that it would not be defeated before that time. At best, the expertise level of this AI would be comparable to that of a distracted baby. Basically, it would lose from the average toddler, given that the toddler would survive the boredom of playing such a stupid AI.
A first major improvement results in what is dubbed the Hunt algorithm. This improved algorithm includes an instruction to explore nearby spaces whenever a prior shot hit. Every human who has every played Battleships will do this intuitively. A great improvement indeed as Nick’s simulations demonstrated that this Hunt algorithm completes 50% of games within ~65 turns, as long as it is not defeated beforehand. Your little toddler nephew will certainly lose, and you might experience some difficulty as well from time to time.
A visual representation of the “Hunting” of the algorithm on a hit [via]
Another minor improvement comes from adding the so-called Parity principle to this Hunt algorithm (i.e., Nick’s Hunt + Parity algorithm). This principle instructs the algorithm to take into account that ships will always cover odd as well as even numbered tiles on the board. This information can be taken into account to provide for some more sensible shooting options. For instance, in the below visual, you should avoid shooting the upper left white tile when you have already shot its blue neighbors. You might have intuitively applied this tactic yourself in the past, shooting tiles in a “checkboard” formation. With the parity principle incorporated, the median completion rate of our algorithm improves to ~62 turns, Nick’s simulations showed.
Now, Nick’s final proposed algorithm is much more computationally intensive. It makes use of Probability Density Functions. At the start of every turn, it works out all possible locations that every remaining ship could fit in. As you can imagine, many different combinations are possible with five ships. These different combinations are all added up, and every tile on the board is thus assigned a probability that it includes a ship part, based on the tiles that are already uncovered.
Computing the probability that a tile contains a ship based on all possible board layouts [via]
At the start of the game, no tiles are uncovered, so all spaces will have about the same likelihood to contain a ship. However, as more and more shots are fired, some locations become less likely, some become impossible, and some become near certain to contain a ship. For instance, the below visual reflects seven misses by the X’s and the darker tiles which thus have a relatively high probability of containing a ship part.
An example distribution with seven misses on the grid. [via]
Nick simulated 100 million games of Battleship for this probabilistic apporach as well as the prior algorithms. The below graph summarizes the results, and highlight that this new probabilistic algorithm greatly outperforms the simpler approaches. It completes 50% of games within ~42 turns! This algorithm will have you crying at the boardgame table.
Relative performance of the algorithms in the Datagenetics blog, where “New Algorithm” refers to the probabilistic approach and “No Parity” refers to the original “Hunt” approach.
Reddit user /u/DataSnaek reworked this probablistic algorithm in Python and turned its inner calculations into a neat GIF. Below, on the left, you see the probability of each square containing a ship part. The brighter the color (white <- yellow <- red <- black), the more likely a ship resides at that location. It takes into account that ships occupy multiple consecutive spots. On the right, every turn the algorithm shoots the space with the highest probability. Blue is unknown, misses are in red, sunk ships in brownish, hit “unsunk” ships in light blue (sorry, I am terribly color blind).
The probability matrix as a heatmap for every square after each move in the game. [via]
This latter attempt by DataSnaek was inspired by Jonathan Landy‘s attempt to train a reinforcement learning (RL) algorithm to win at Battleships. Although the associated GitHub repository doesn’t go into much detail, the approach is elaborately explained in this blog. However, it seems that this specific code concerns the training of a neural network to perform well on a very small Battleships board, seemingly containing only a single ship of size 3 on a board with only a single row of 10 tiles.
Fortunately, Sue He wrote about her reinforcement learning approach to Battleships in 2017. Building on the open source phoenix-battleship project, she created a Battleship app on Heroku, and asked co-workers to play. This produced data on 83 real, two-person games, showing, for instance, that Sue’s coworkers often tried to hide their size 2 ships in the corners of the Battleships board.
Probability heatmaps of ship placement in Sue He’s reinforcement learning Battleships project [via]
Next, Sue scripted a reinforcement learning agent in PyTorch to train and learn where to shoot effectively on the 10 by 10 board. It became effective quite quickly, requiring only 52 turns (on average over the past 25 games) to win, after training for only a couple hundreds games.
The performance of the RL agent at Battleships during the training process [via]
However, as Sue herself notes in her blog, disappointly, this RL agent still does not outperform the probabilistic approach presented earlier in this current blog.
Reddit user /u/christawful faced similar issues. Christ (I presume he is called) trained a convolutional neural network (CNN) with the below architecture on a dataset of Battleships boards. Based on the current board state (10 tiles * 10 tiles * 3 options [miss/hit/unknown]) as input data, the intermediate convolutional layers result in a final output layer containing 100 values (10 * 10) depicting the probabilities for each tile to result in a hit. Again, the algorithm can simply shoot the tile with the highest probability.
Christ’s convolutional neural network architecture for Battleships [via]
Christ was nice enough to include GIFs of the process as well [via]. The first GIF shows the current state of the board as it is input in the CNN — purple represents unknown tiles, black a hit, and white a miss (i.e., sea). The next GIF represent the calculated probabilities for each tile to contain a ship part — the darker the color the more likely it contains a ship. Finally, the third picture reflects the actual board, with ship pieces in black and sea (i.e., miss) as white.
As cool as this novel approach was, Chris ran into the same issue as Sue, his approach did not perform better than the purely probablistic one. The below graph demonstrates that while Christ’s CNN (“My Algorithm”) performed quite well — finishing a simulated 9000 games in a median of 52 turns — it did not outperform the original probabilistic approach of Nick Berry — which came in at 42 turns. Nevertheless, Chris claims to have programmed this CNN in a couple of hours, so very well done still.
The performance of Christ’s Battleship CNN compared to Nick Berry’s original algorithms [via]
Interested by all the above, I searched the web quite a while for any potential improvement or other algorithmic approaches. Unfortunately, in vain, as I did not find a better attempt than that early 2012 Datagenics probability algorithm by Nick.
Surely, with today’s mass cloud computing power, someone must be able to train a deep reinforcement learner to become the Battleship master? It’s not all probability right, there must be some patterns in generic playing styles, like Sue found among her colleagues. Or maybe even the ability of an algorithm to adapt to the opponent’s playin style, as we see in Libratus, the poker AI. Maybe the guys at AlphaGo could give it a shot?
For starters, Christ’s provided some interesting improvements on his CNN approach. Moreover, while the probabilistic approach seems the best performing, it might not the most computationally efficient. All in all, I am curious to see whether this story will continue.
Did you know that dragonflies are one of the most effective and accurate predators alive? And that while it has a brain consisting of very few neurons. Neuroscientist Greg Gage and his colleagues studied how a dragonfly locks onto its preys and captures it within milliseconds. Actually, a dragonfly seems to be little more than a small neural network hooked up to some wings, and optimized through millions of years of evolution.
Joel Simon is the genius behind an experimental project exploring optimized school blueprints. Joel used graph-contraction and ant-colony pathing algorithms as growth processes, which could generate elementary school designs optimized for all kinds of characteristics: walking time, hallway usage, outdoor views, and escape routes just to name a few.
Two generated designs, minimizing the traffic flow (left) as well as escape routes (right) [original]Other designs tried to maximize the number of windows, resulting in seemingly random open courtyards [original]
The original floor plan [original]Definitely check out the original write-up if you are interested in the details behind the generation process! Or have a look at some of Joel’s other projects.
In optimizing their transportation services, Uber uses evolutionary strategies and genetic algorithms to train deep neural networks through reinforcement learning. A lot of difficult words in one sentence; you can imagine the complexity of the process.
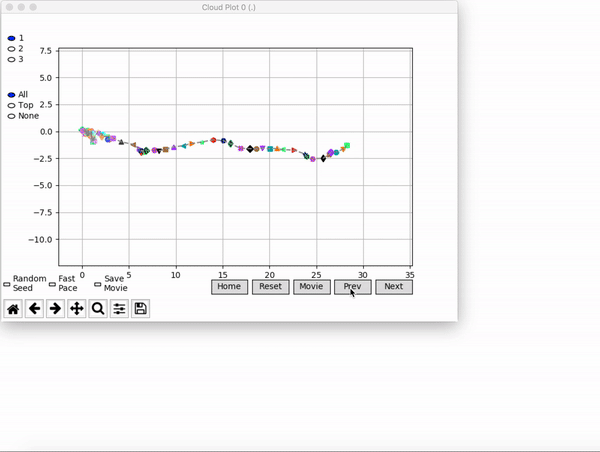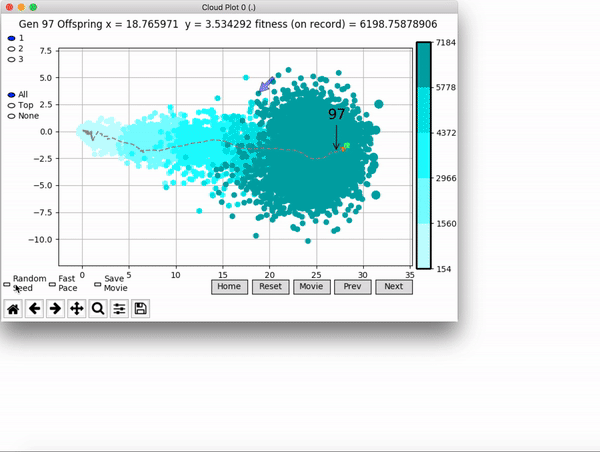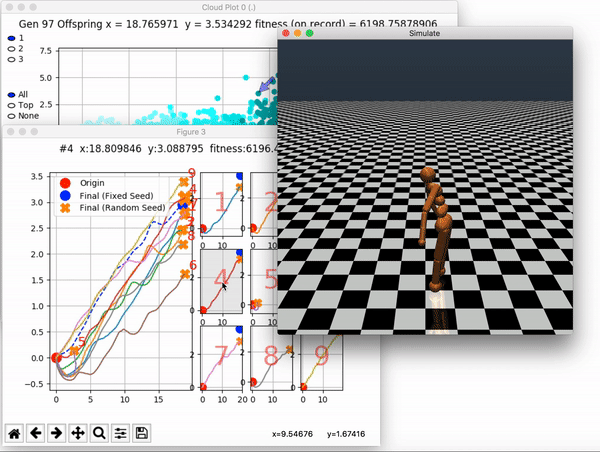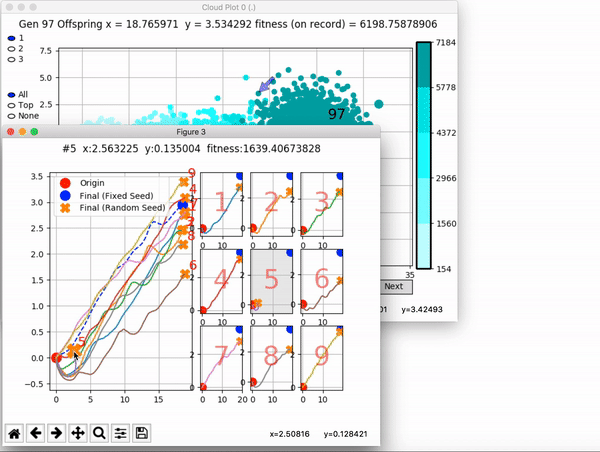
Because it is particularly difficult to observe the underlying dynamics of this learning process in neural network optimization, Uber built VINE – a Visual Inspector for NeuroEvolution. VINE helps to discover how evolutionary strategies and genetic optimizing are performing under the hood. In a recent article, they demonstrate how VINE works on the MujocoHumanoid Locomotion task.
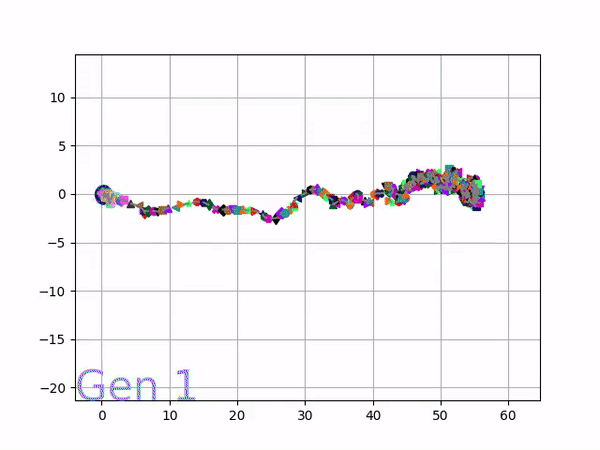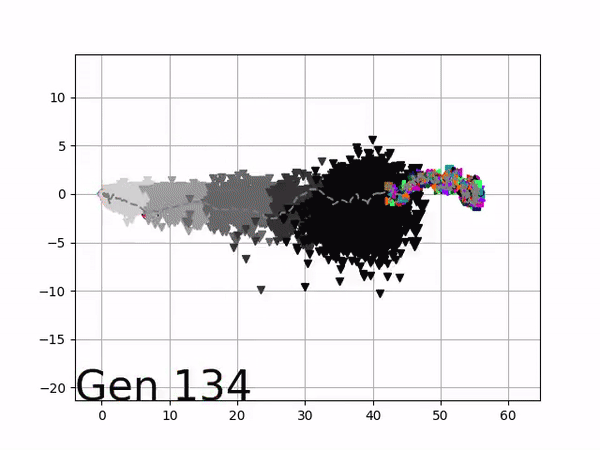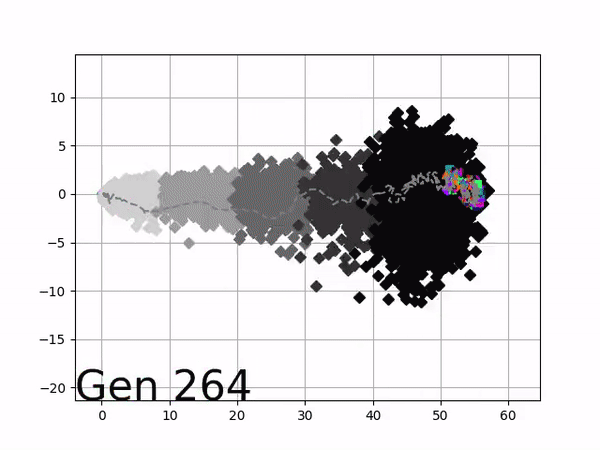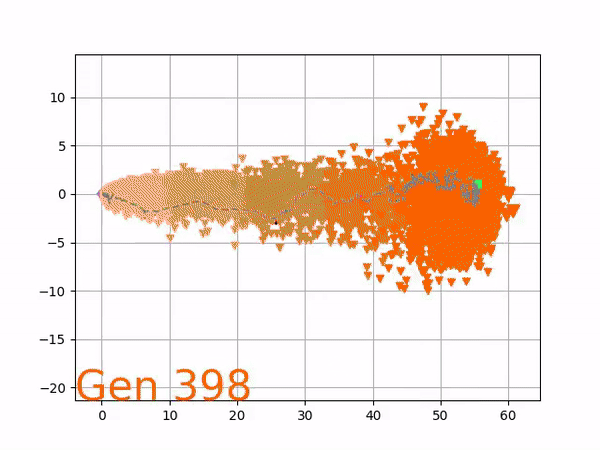
[…] In the Humanoid Locomotion Task, each pseudo-offspring neural network controls the movement of a robot, and earns a score, called its fitness, based on how well it walks. [Evolutionary principles] construct the next parent by aggregating the parameters of pseudo-offspring based on these fitness scores […]. The cycle then repeats.
VINE plots parent neural networks and their pseudo-offspring according to their performance. Users can then interact with these plots to:
visualize parents, top performance, and/or the entire pseudo-offspring cloud of any generation,
compare between and within generation performance,
and zoom in on any pseudo-offspring (points) in the plot to display performance information.
The GIFs below demonstrate what VINE is capable of displaying:
The evolution of performance over generations. The color changes in each generation. Within a generation, the color intensity of each pseudo-offspring is based on the percentile of its fitness score in that generation (aggregated into five bins). [original]Vine allows user to deep dive into each single generation, comparing generations and each pseudo-offspring within them [original]VINE can be found at this link. It is lightweight, portable, and implemented in Python.