In this awesome 8-minute read, R-progidy Colin Fay explains in laymen’s terms what Docker images, Docker containers, and Volumes are; what Rocker is; and how to set up a Docker container with an R image and run code on it:
On your machine, you’re going to need two things: images, and containers. Images are the definition of the OS, while the containers are the actual running instances of the images. […] To compare with R, this is the same principle as installing vs loading a package: a package is to be downloaded once, while it has to be launched every time you need it. And a package can be launched in several R sessions at the same time easily.
Michael Freeman — information researcher at the University of Washington — was asked whether he could manipulate images with only R programming and he thought to give it a try. In his blog, Michael demonstrates how he used ggplot2 and the imager packages, among others, to go from this original photo:
I recently got pointed towards a 2017 paper on bioRxiv that blew my mind: three researchers at the Computational Neuroscience Laboratories at Kyoto, Japan, demonstrate how they trained a deep neural network to decode human functional magnetic resonance imaging (fMRI) patterns and then generate the stimulus images.
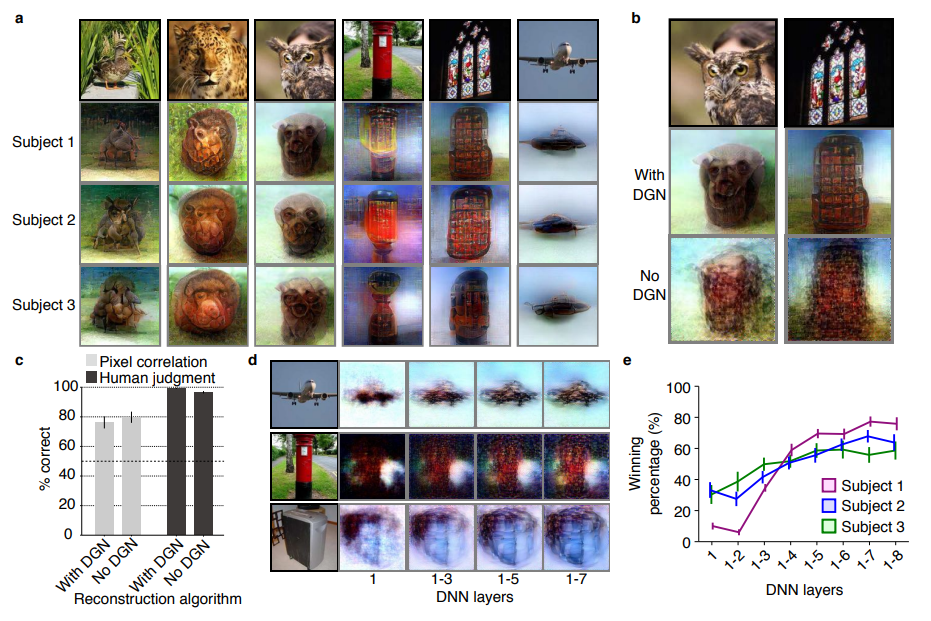
In simple words, the scholars used sophisticated machine learning to reconstruct the photo’s their research particpants saw based on their brain activity… INSANE! The below shows the analysis workflow, and an actual reconstructed image. More reconstructions follow further on.
Figure 1 | Deep image reconstruction. Overview of deep image reconstruction is shown. The pixels’ values of the input image are optimized so that the DNN features of the image are similar to those decoded from fMRI activity. A deep generator network (DGN) is optionally combined with the DNN to produce natural-looking images, in which optimization is performed at the input space of the DGN. [original]Three healthy young adults participated in two types of experiments: an image presentation experiment and an imagery experiment.
In the image presentation experiments, participants were presented with several natural images from the ImageNet database, with 40 images geometrical shapes, and with 10 images of black alphabetic characters. These visual stimuli were rear-projected onto a screen in an fMRI scanner bore. Data from each subject were collected over multiple scanning sessions spanning approximately 10 months. Images were flashed at 2 Hz for several seconds. In the imagery experiment, subjects were asked to visually imagine / remember one of 25 images of the presentation experiments. Subjects were
required to start imagining a target image after seeing some cue words.
In both experimental setups, fMRI data were collected using 3.0-Tesla Siemens MAGNETOM Verio scanner located at the Kokoro Research Center, Kyoto University.
The results, some of which I copied below, are plainly amazing.
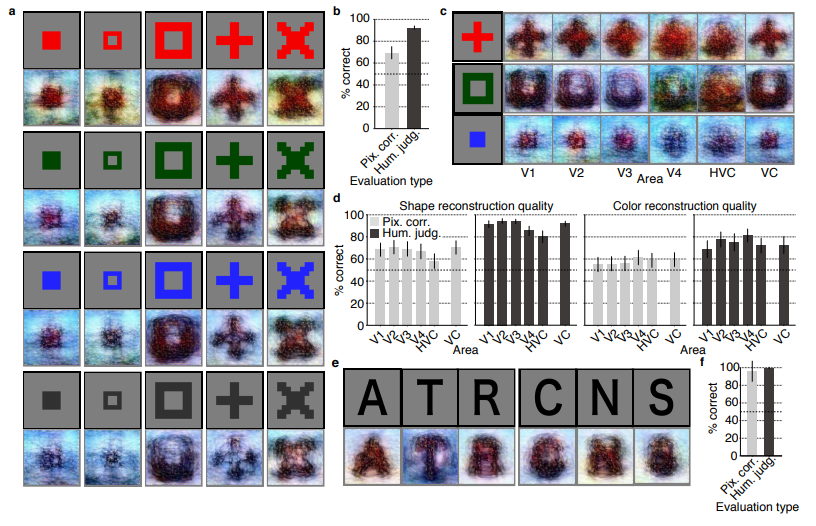
Figure 2 | Seen natural image reconstructions. Images with black and gray frames show presented and reconstructed images, respectively (reconstructed from VC activity). a) Reconstructions utilizing the DGN (using DNN1–8). Three reconstructed images correspond to reconstructions from three subjects. b) Reconstructions with and without the DGN (DNN1–8). The first, second, and third rows show presented images, reconstructions with and without the DGN, respectively. c) Reconstruction quality of seen natural images (error bars, 95% confidence interval (C.I.) across samples; three subjects pooled; chance level, 50%). d) Reconstructions using different combinations of DNN layers (without the DGN). e) Subjective assessment of reconstructions from different combinations of DNN layers (error bars, 95% C.I. across samples) [original]Figure 3 | Seen artificial shape reconstructions. Images with black and gray frames show presented and reconstructed images (DNN 1–8, without the DGN). a) Reconstructions for seen colored artificial shapes (VC activity). b, Reconstruction quality of colored artificial shapes. c) Reconstructions of colored artificial shapes obtained from multiple visual areas. d) Reconstruction quality of shape and colors for different visual areas. e) Reconstructions of alphabetical letters. f) Reconstruction quality for alphabetical letters. For b, d, f, error bars indicate 95% C.I. across samples (three subjects pooled; chance level, 50%) [original] Supplementary Figure 2 | Other examples of natural image reconstructions obtained with the DGN. Images with black and gray frames show presented and reconstructed images, respectively (reconstructed from VC activity using all DNN layers). Three reconstructed images correspond to reconstructions from three subjects. [original]Supplementary Figure 3 | Reconstructions through optimization processes. Reconstructed images obtained through the optimization processes are shown (reconstructed from VC activity of Subject 1 using all DNN layers and the DGN). Images with black and gray frames show presented and reconstructed images, respectively. [original]There were many more examples of reconstructed images, as well as much more detailed information regarding the machine learning approach and experimental setup, so I strongly advise you check out the orginal paper.
I can’t even imagine what such technology would imply for society… Proper minority report stuff here.
Here’s the abstract as an additional teaser:
Abstract
Machine learning-based analysis of human functional magnetic resonance imaging
(fMRI) patterns has enabled the visualization of perceptual content. However, it has been limited to the reconstruction with low-level image bases (Miyawaki et al., 2008; Wen et al., 2016) or to the matching to exemplars (Naselaris et al., 2009; Nishimoto et al., 2011). Recent work showed that visual cortical activity can be decoded (translated) into hierarchical features of a deep neural network (DNN) for the same input image, providing a way to make use of the information from hierarchical visual features (Horikawa & Kamitani, 2017). Here, we present a novel image reconstruction method, in which the pixel values of an image are optimized to make its DNN features similar to those decoded from human brain activity at multiple layers. We found that the generated images resembled the stimulus images (both natural images and artificial shapes) and the subjective visual content during imagery. While our model was solely trained with natural images, our method successfully generalized the reconstruction to artificial shapes, indicating that our model indeed ‘reconstructs’ or ‘generates’ images from brain activity, not simply matches to exemplars. A natural image prior introduced by another deep neural network effectively rendered semantically meaningful details to reconstructions by constraining reconstructed images to be similar to natural images. Furthermore, human judgment of reconstructions suggests the effectiveness of combining multiple DNN layers to enhance visual quality of generated images. The results suggest that hierarchical visual information in the brain can be effectively combined to reconstruct perceptual and subjective images.
Zack Nado wrote the best machine learning application I’ve seen so far: a neural network architecture that generates new Pusheen pictures.
This is an orginal Pusheen picture.
In his blog, Zack describes his generative adversarial network (GAN) , a special type of machine learning architecture where two neural networks try to fool each other. Zack first gave the discriminator network some real Pusheen images, so it gets an idea of what Pusheen looks like. Next, the generator network gets a bunch of random numbers so it can generate completely new (fake) images. These generated images are then fed back into the discriminator, so it knows what generated images look like. Zack repeated this process several hundred thousand times, so he obtained a generator network that’s great at making new Pusheen images which the discriminator (nearly) can’t dinstinguish from the original, real ones. Below is the learning process of the generator network visualized:
Samples output by the generator network. It learns distinctive features of “real” Pusheen (e.g., tail, eyes, ears) over time [original]
In the end, the generated images are very much like the real Pusheen. Zack added an interactive module (using Tensorflow.js) to the blog so you can generate some Pusheens yourself. (it didn’t work for me though…) On a final note, Zack wrote the orginal blog both in plain English, for non-experts, and in jargon, for the more experienced data scientists. I highly recommend you read either one of those versions!
Some of the Pusheen’s generated by Zack’s GAN [original]
The field of computer vision tries to replicate our human visual capabilities, allowing computers to perceive their environment in a same way as you and I do. The recent breakthroughs in this field are super exciting and I couldn’t but share them with you.
In the TED talk below by Joseph Redmon (PhD at the University of Washington) showcases the latest progressions in computer vision resulting, among others, from his open-source research on Darknet – neural network applications in C. Most impressive is the insane speed with which contemporary algorithms are able to classify objects. Joseph demonstrates this by detecting all kinds of random stuff practically in real-time on his phone! Moreover, you’ve got to love how well the system works: even the ties worn in the audience are classified correctly!
The second talk, below, is more scientific and maybe even a bit dry at the start. Blaise Aguera y Arcas (engineer at Google) starts with a historic overview brain research but, fortunately, this serves a cause, as ~6 minutes in Blaise provides one of the best explanations I have yet heard of how a neural network processes images and learns to perceive and classify the underlying patterns. Blaise continues with a similarly great explanation of how this process can be reversed to generate weird, Asher-like images, one could consider creative art:
An example of a reversed neural network thus “estimating” an image of a bird [via Youtube]Blaise’s colleagues at Google took this a step further and used t-SNE to visualize the continuous space of animal concepts as perceived by their neural network, here a zoomed in part on the Armadillo part of the map, apparently closely located to fish, salamanders, and monkeys?
A zoomed view of part of a t-SNE map of latent animal concepts generated by reversing a neural network [via Youtube]We’ve seen these latent spaces/continua before. This example Andrej Karpathy shared immediately comes to mind:
If you want to learn more about this process of image synthesis through deep learning, I can recommend the scientific papers discussed by one of my favorite Youtube-channels, Two-Minute Papers. Karoly’s videos, such as the ones below, discuss many of the latest developments:
Let me know if you have any other video’s, papers, or materials you think are worthwhile!
Super-resolution imaging is a class of techniques that enhance the resolution of an imaging system (Wikipedia). The entertainment series CSI has been ridiculed for relying on exaggerated and unrealistic applications of it:
As a result, there are now several applications where machines have learned to literallyfill in the blanks in imagery. Most notable seems the method developed by Google: Rapid and Accurate Image Super Resolution, or RAISR is short. In contrast to other approaches, RAISR does not rely on (adversarial) neural network(s) and is thus not as resource-demanding to train. Moreover, it’s performance is quite remarkable:
I guess you’re eager to test this super resolution out yourself?! letsenhance.io let’s you enhance the resolution of five images for free, after which it charges you $5 per twenty pictures processed. The website feeds the input image to a neural net and puts out an image of which the resolution has been increased four fold! I tested it with this random blurry picture I retrieved from Google/Pinterest.
Original 500×500
Enhanced 2000×2000
Do you see how much more detailed (though still blurry) the second image is? Nevertheless, upscaling four times seems about the limit as that is the default factor for both RAISR and Let’s Enhance. I am very curious to see how this super resolution is going to develop in the future, how it will be used to decrease memory or network demands, whether it will be integrated with video platforms like YouTube or Netflix, and which algorithm will ultimately take the crown!



















 You can read more details in the
You can read more details in the 


