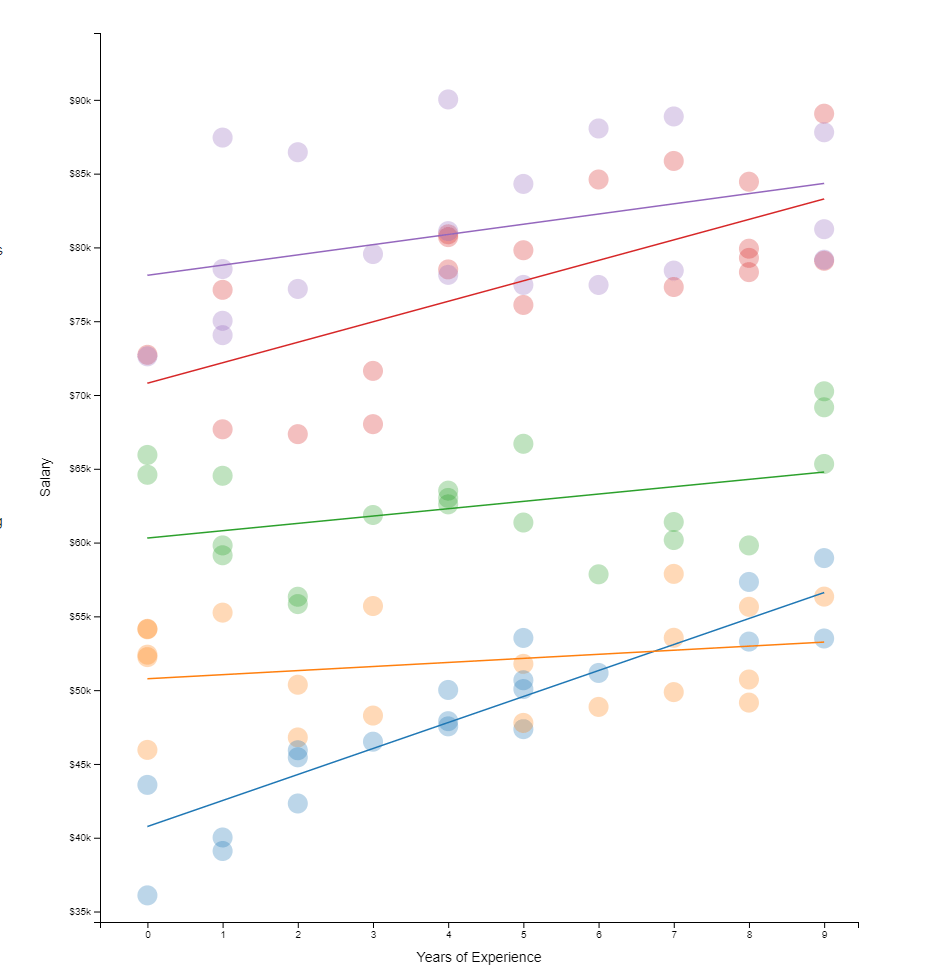Hierarchical models I have covered before on this blog. These models are super relevant in practice. For instance, in HR, employee data is always nested within teams which are in turn nested within organizational units. Also in my current field of insurances, claims are always nested within policies, which can in turn be nested within product categories. Data is hierachical, and we need to take that into account when we model it.
Hierarchical models do just that. Interested in how they do this? Have a look at this amazing browser application made in React.js!
All code for this project is on GitHub, including the script to create the data and run regressions (done inR). Feel free to issue a pull request for improvements, and if you like it, share it on Twitter. Layout inspired by Tony Chu.
Harvard (bio)statisticians Miguel Hernan and Jamie Robins just released their new book, online and accessible for free!
The Causal Inference book provides a cohesive presentation of causal inference, its concepts and its methods. The book is divided in 3 parts of increasing difficulty: causal inference without models, causal inference with models, and causal inference from complex longitudinal data. Here’s the official Harvard page for the book release.
This is definitely an interesting read for epidemiologists, statisticians, psychologists, economists, sociologists, political scientists, data scientists, computer scientists, and any other person with a love for proper data analysis!
Christopher of Neurotroph.de compiled this short list of data science podcastsworth listening to. See Chris’ original article for more details on the podcasts, but the links below take you to them directly:
Thanks to Sebastian Raschka I am able to share this great GitHub overview page of relevant graph classification techniques, and the scientific papers behind them. The overview divides the algorithms into four groups:
As well as a link to relevant graph classification benchmark datasets.
"Awesome Graph Classification" — A collection of graph classification methods, covering embedding, deep learning, graph kernel, and factorization papers with reference implementations https://t.co/ugpL3xSvf1
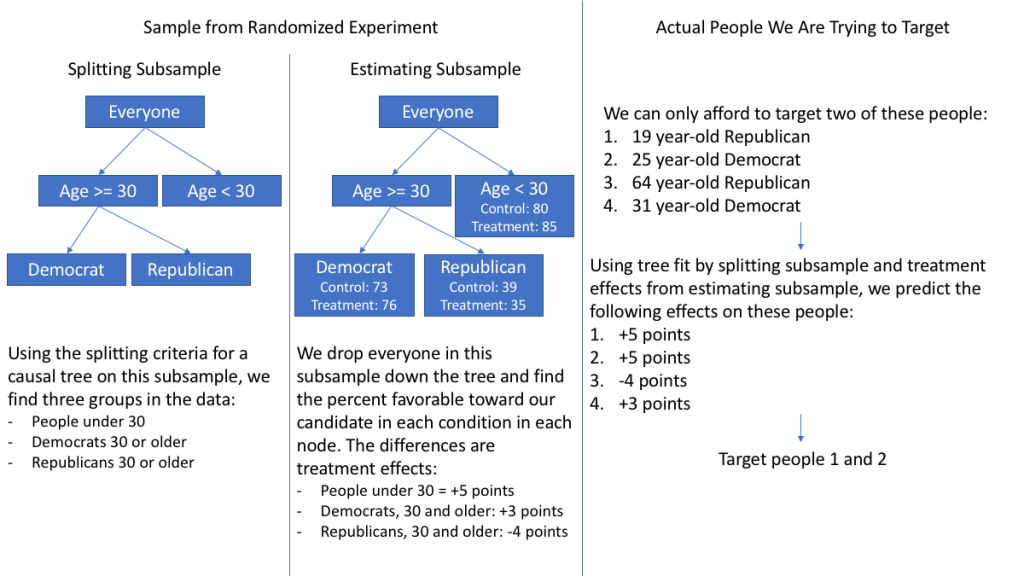
I stumbled accros this incredibly interesting read by Mark White, who discusses the (academic) theory behind, inner workings, and example (R) applications of causal random forests:
These so-called “honest” forests seem a great technique to identify opportunities for personalized actions: think of marketing, HR, medicine, healthcare, and other personalized recommendations. Note that an experimental setup for data collection is still necessary to gather the right data for these techniques.
Since 1988, the Royal Society has celebrated outstanding popular science writing and authors.
Each year, a panel of expert judges choose the book that they believe makes popular science writing compelling and accessible to the public.
Over the decades, the Prize has celebrated some notable winners including Bill Bryson and Stephen Hawking.
The author of the winning book receives £25,000 and £2,500 is awarded to each of the five shortlisted books. And this year’s shortlist includes some definite must-reads on data and statistics!
The captivating story of mathematics’ greatest ever idea: calculus. Without it, there would be no computers, no microwave ovens, no GPS, and no space travel. But before it gave modern man almost infinite powers, calculus was behind centuries of controversy, competition, and even death.
Taking us on a thrilling journey through three millennia, Professor Steven Strogatz charts the development of this seminal achievement, from the days of Archimedes to today’s breakthroughs in chaos theory and artificial intelligence. Filled with idiosyncratic characters from Pythagoras to Fourier, Infinite Powers is a compelling human drama that reveals the legacy of calculus in nearly every aspect of modern civilisation, including science, politics, medicine, philosophy, and more.
Imagine a world where your phone is too big for your hand, where your doctor prescribes a drug that is wrong for your body, where in a car accident you are 47% more likely to be seriously injured, where every week the countless hours of work you do are not recognised or valued. If any of this sounds familiar, chances are that you’re a woman.
Invisible Women shows us how, in a world largely built for and by men, we are systematically ignoring half the population. It exposes the gender data gap–a gap in our knowledge that is at the root of perpetual, systemic discrimination against women, and that has created a pervasive but invisible bias with a profound effect on women’s lives. From government policy and medical research, to technology, workplaces, urban planning and the media, Invisible Women reveals the biased data that excludes women.
This book does not deal with data or statistics specifically, but might even be more interesting, as it covers the topic of quantum physics:
Quantum physics is strange. It tells us that a particle can be in two places at once. That particle is also a wave, and everything in the quantum world can be described entirely in terms of waves, or entirely in terms of particles, whichever you prefer.
All of this was clear by the end of the 1920s, but to the great distress of many physicists, let alone ordinary mortals, nobody has ever been able to come up with a common sense explanation of what is going on. Physicists have sought ‘quanta of solace’ in a variety of more or less convincing interpretations.
This short guide presents us with the six theories that try to explain the wild wonders of quantum. All of them are crazy, and some are crazier than others, but in this world crazy does not necessarily mean wrong, and being crazier does not necessarily mean more wrong.