In Glad You Asked, Vox dives deep into timely questions around the impact of systemic racism on our communities and in our daily lives.
In this video, they look into the role of tech in societal discrimination. People assume that tech and data are neutral, and we have turned to tech as a way to replace biased human decision-making. But as data-driven systems become a bigger and bigger part of our lives, we see more and more cases where they fail. And, more importantly, that they don’t fail on everyone equally.
Why do we think tech is neutral? How do algorithms become biased? And how can we fix these algorithms before they cause harm? Find out in this mini-doc:
I just love psychological experiments around our human biases.
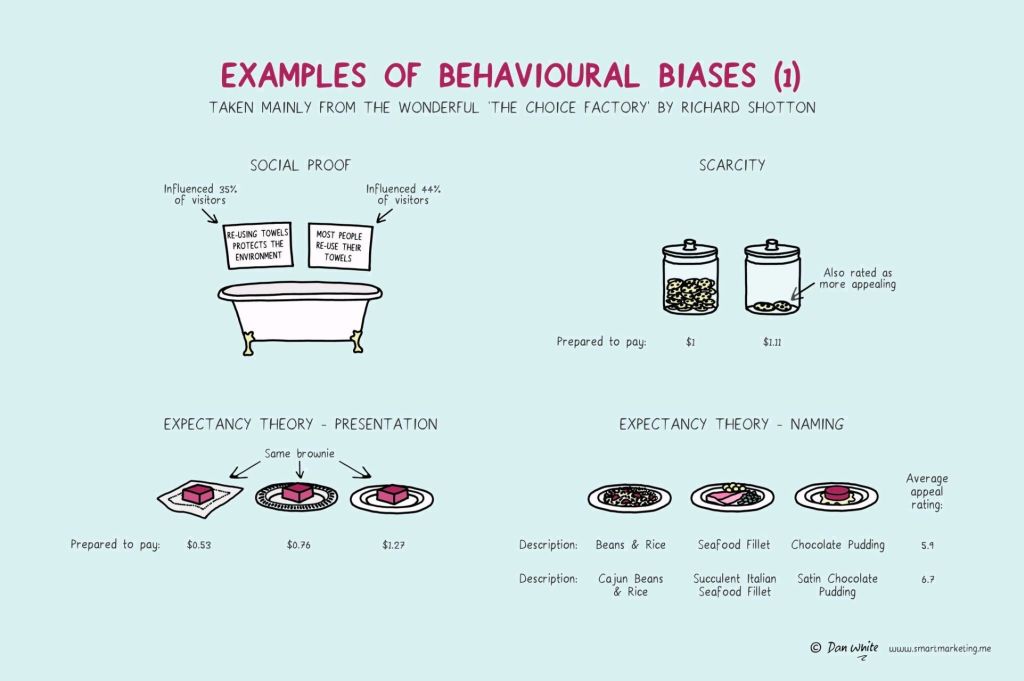
In this case, Dan White visualized some of the psychological biases mentioned in Richard Shotton‘s book “The Choice Factory“.
These biases make for irrational human behavior in the way we make daily decisions.
For example, you will be prepared to pay more for a cookie, when there are less of them in the jar. The generic principle here is that we assign higher valuations to objects under conditions of scarcity.
Once you are aware of such psychological biases, you will start to notice how they are (mis)used nearly everywhere these days. Particularly in sales and marketing. In restaurants, shops, online, and in virtually any case where we act as a consumer, we are subconciously influenced to make certain purchasing decision.
Nudging, is what they call these attempts to manipulate your behavior.
Maybe not so ethical, but still these infographics look amazing and these biases are good to be aware of!
Disclaimer: This page contains one or more links to Amazon. Any purchases made through those links provide us with a small commission that helps to host this blog.
The assumption that a Machine Learning (ML) project is done when a trained model is put into production is quite faulty. Neverthless, according to Alexandre Gonfalonieri — artificial intelligence (AI) strategist at Philips — this assumption is among the most common mistakes of companies taking their AI products to market.
Actually, in the real world, we see pretty much the opposite of this assumption. People like Alexandre therefore strongly recommend companies keep their best data scientists and engineers on a ML project, especially after it reaches production!
Why?
If you’ve ever productionized a model and really started using it, you know that, over time, your model will start performing worse.
In order to maintain the original accuracy of a ML model which is interacting with real world customers or processes, you will need to continuously monitor and/or tweak it!
In the best case, algorithms are retrained with each new data delivery. This offers a maintenance burden that is not fully automatable. According to Alexandre, tending to machine learning models demands the close scrutiny, critical thinking, and manual effort that only highly trained data scientists can provide.
This means that there’s a higher marginal cost to operating ML products compared to traditional software. Whereas the whole reason we are implementing these products is often to decrease (the) costs (of human labor)!
What causes this?
Your models’ accuracy will often be at its best when it just leaves the training grounds.
Building a model on relevant and available data and coming up with accurate predictions is a great start. However, for how long do you expect those data — that age by the day — continue to provide accurate predictions?
Chances are that each day, the model’s latent performance will go down.
This phenomenon is called concept drift, and is heavily studied in academia but less often considered in business settings. Concept drift means that the statistical properties of the target variable, which the model is trying to predict, change over time in unforeseen ways.
In simpler terms, your model is no longer modelling the outcome that it used to model. This causes problems because the predictions become less accurate as time passes.
Particularly, models of human behavior seem to suffer from this pitfall.
The key is that, unlike a simple calculator, your ML model interacts with the real world. And the data it generates and that reaches it is going to change over time. A key part of any ML project should be predicting how your data is going to change over time.
You need to create a monitoring strategy before reaching production!
According to Alexandre, as soon as you feel confident with your project after the proof-of-concept stage, you should start planning a strategy for keeping your models up to date.
How often will you check in?
On the whole model, or just some features?
What features?
In general, sensible model surveillance combined with a well thought out schedule of model checks is crucial to keeping a production model accurate. Prioritizing checks on the key variables and setting up warnings for when a change has taken place will ensure that you are never caught by a surprise by a change to the environment that robs your model of its efficacy.
Your strategy will strongly differ based on your model and your business context.
Moreover, there are many different types of concept drift that can affect your models, so it should be a key element to think of the right strategy for you specific case!
Once you observe degraded model performance, you will need to redesign your model (pipeline).
One solution is referred to as manual learning. Here, we provide the newly gathered datato our model and re-train and re-deploy it just like the first time we build the model. If you think this sounds time-consuming, you are right. Moreover, the tricky part is not refreshing and retraining a model, but rather thinking of new features that might deal with the concept drift.
A second solution could be to weight your data. Some algorithms allow for this very easily. For others you will need to custom build it in yourself. One recommended weighting schema is to use the inversely proportional age of the data. This way, more attention will be paid to the most recent data (higher weight) and less attention to the oldest of data (smaller weight) in your training set. In this sense, if there is drift, your model will pick it up and correct accordingly.
According to Alexandre and many others, the third and best solution is to build your productionized system in such a way that you continuously evaluate and retrain your models. The benefit of such a continuous learning system is that it can be automated to a large extent, thus reducing (the human labor) maintance costs.
Although Alexandre doesn’t expand on how to do these, he does formulate the three steps below:
In my personal experience, if you have your model retrained (automatically) every now and then, using a smart weighting schema, and keep monitoring the changes in the parameters and for several “unit-test” cases, you will come a long way.
If you’re feeling more adventureous, you could improve on matters by having your model perform some exploration (at random or rule-wise) of potential new relationships in your data (see for instance multi-armed bandits). This will definitely take you a long way!
The following are my summary and take-aways from Janelle Shane’s 2019 book named You look like a thing and I love you. Most of the below are excerpts from Janelle’s book, combined, or rewritten by me. For the sake of copyright, just consider everything Janelle’s : )
AI weirdness
You look like a thing and I love you is about AI. More specifically, the book is about what AI can and can not do. And how and why AI often fails in miserably hilareous ways.
Janelle has spend her time foing fun experiments with AI. In this book, she shares those experiments along with many real life examples of AIs in practice. While explaining the technical details behind these AIs in an accesible though technically correct way, she informs the reader where, how, and why AIs fail.
Janelle took AIs out of their comfort zone and it produced some hilareously weird results. She proposes five principles of AI Weirdness:
The danger of AI is not that it’s too smart, but that it’s not smart enough
AI has the approximate brainpower of a worm
AI does not really understand the problem you want it to solve
But: AI will do exactly what you tell it to. Or at least it will try its best.
And AI willt ake the path of the least resistance
Definitions: What is (not) AI?
If it seems like AI is everywhere, it’s partly because Artificial Intelligence means lots of things, depending on whether you’re reading science fiction or selling a new app or doing academic research.
To spot an AI in the wild, it’s important to know the difference between machine learning algorithms (what Janelle calls AI in her book) and traditional, rules-based programs.
To solve a problem with a rules-based program, you have to know every step required to complete the program’s task and how to describe each one of those steps. But a machine learning algorithm figures out the rules for itself via trail and error, gauging its success on goals the programmer has specified. As the AI tries to reach this goal, it can discover rules and correlations that the programmer didn’t even know existed. This is what makes AIs attractive problem solvers and is particularly handy if the rules are really complicated or just plain mysterious.
Sometimes an AI’s brilliant problem-solving rules actually rely on mistaken assumptions. Rules that served it well in training but fail miserably when it encountered the real world. While training errors are common in complex AIs, the consequences of these mistakes can be serious.
It’s often not easy to tell when AIs make mistakes. Since we don’t write the rules, they come up with their own, and they don’t write them down or explain them the way a human would.
The difference between succesful AI problem solving and failure usually has a lot to do with the suitability of the task for an AI solution. And there are plenty of tasks for which AI solutions are more efficient than human solutions. But there are also plenty of cases where things go miserably wrong.
Janelle proposes four signs of “AI Doom”, contexts where machine learning will not produce the desired results:
The problem is too hard, broad, or complex
The problem is not what we thought it was
There are sneaky shortcuts to solving the problem
The AI tried to solve the problem learning from flawed data
Programming an AI is almost more like teaching a child than programming a computer.
Explaining how AI works
In her book, Janelle takes us through many example problems which she or others tried to solve using AIs. These example problems are increasingly hilareous, but I assure you that they are technically and didactically sound:
Playing tic-tac-toe
Managing a cockroach farm
Riding a bicycle
Rating sandwich deliciousness
Tossing a sandwich into a wall
Guiding people through a hallway
Answering questions regarding photo’s
Categorizing doodles
Categorizing fish
Tossing pancakes
Autonomous walking
Autonomous driving
Playing Pacman
The amazing thing is these ridiculous example problems actually serve a purpose. They are used to explain different algorithms and their applications, strengths, and limitations! Janelle covers a wide variety of algorithms in such a way that anyone new to machine learning would understand, while people with some experience will still be amused.
Janelle talks about artificial neural networks, random forests, and markov chains. Moreover, she explains how activation functions, recurrancy and long short-term memory, evolutionary algorithms and gradient descent work. And all in understandable though technically correct language.
Janelle herself seems particularly fond of generative algorithms. She’s elaborates on having deployed recurrent neural nets, generative adversial networks, and markov chains for a wide variety of generative tasks. In the book, Jabekke explains what went well and went wrong when coming up with new and original…
Janelle’s book is lingered with examples of failing AI. As a matter of fact, the whole book seems like an ode to how machine learning can and will inevitably fail. Particularly in the latter chapters, Janelle covers many limitations of and issues with AI in much detail:
I have yet to come across a book that explain AI in this much detail and in a manner as accessible and entertaining as Janelle Shane does in You look like a thing and I love you. Janelle makes machine learning and AI understandable for a wide public without passing on the deeper technical details. Taking a critical stance, she provides a good overview of the strenghts and weaknesses of AI, and a realistic outlook for the future to come. This book is not looking for sensation or hype, although reading it will be a most amusing experience for the more technical as well as the lay reader.
I highly recommend you reward yourself with a copy!
We can’t just throw data into machines and expect to see any meaning […], we need to think [about this]. I see a strong trend in the practitioners community to just automate everything, to just throw data into a black box and expect to get money out of it, and I really don’t believe in that.
All pictures below are slides from the above video.
My summary / interpretation
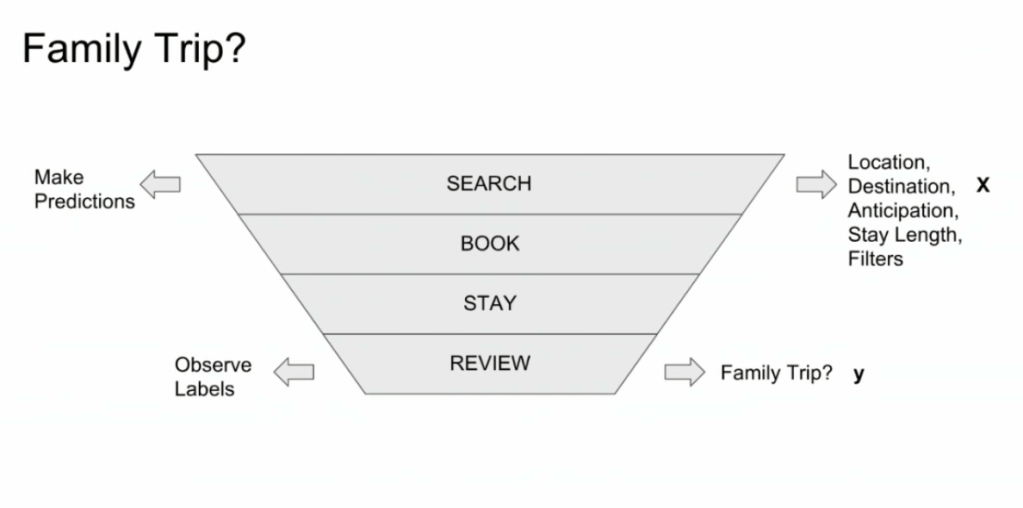
Lucas highlights an example he has been working on at Booking.com, where they seek to predict which searching activities on their website are for family trips.
What happens is that people forget to specify that they intend to travel as a family, forget to input one/two/three child travellers will come along on the trip, and end up not being able to book the accomodations that come up during their search. If Booking.com would know, in advance, that people (may) be searching for family accomodations, they can better guide these bookers to family arrangements.
The problem here is that many business processes in real life look and act like a funnel. Samples drop out of the process during the course of it. So too the user search activity on Booking.com’s website acts like a funnel.
People come to search for arrangements
Less people end up actually booking arrangements
Even less people actually go on their trip
And even less people then write up a review
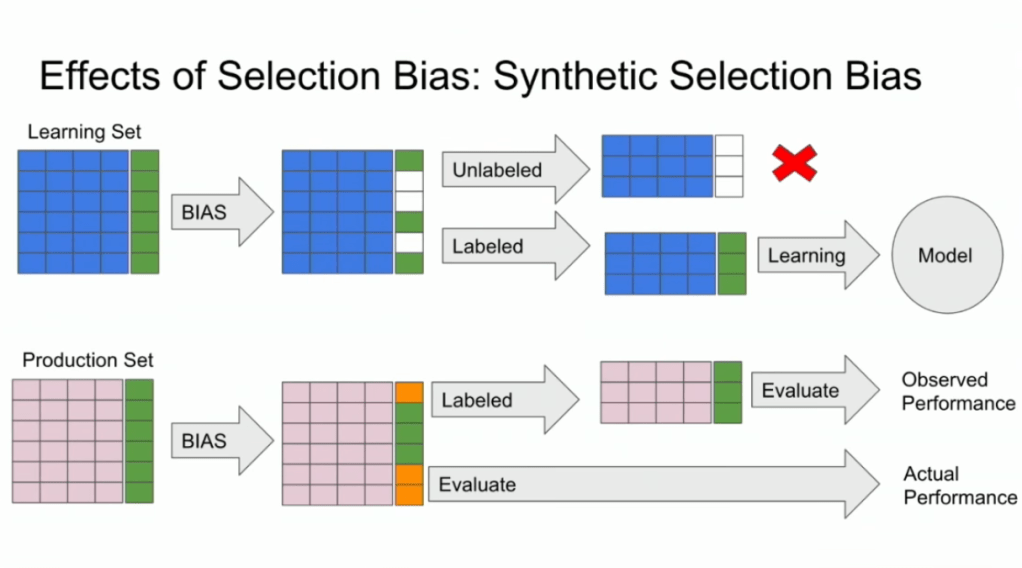
However, only for those people that end up writing a review, Booking.com knows 100% certain that they it concerned a family trip, as that is the moment the user can specify so. Of all other people, who did not reach stage 4 of the funnel, Booking.com has no (or not as accurate an) idea whether they were looking for family trips.
Such a funnel thus inherently produces business data with selection bias in it. Only for people making it to the review stage we know whether they were family trips or not. And only those labeled data can be used to train our machine learning model.
And now for the issue: if you train and evaluate a machine learning model on data generated with such a selection bias, your observed performance metrics will not reflect the actual performance of your machine learning model!
Actually, they are pretty much overestimates.
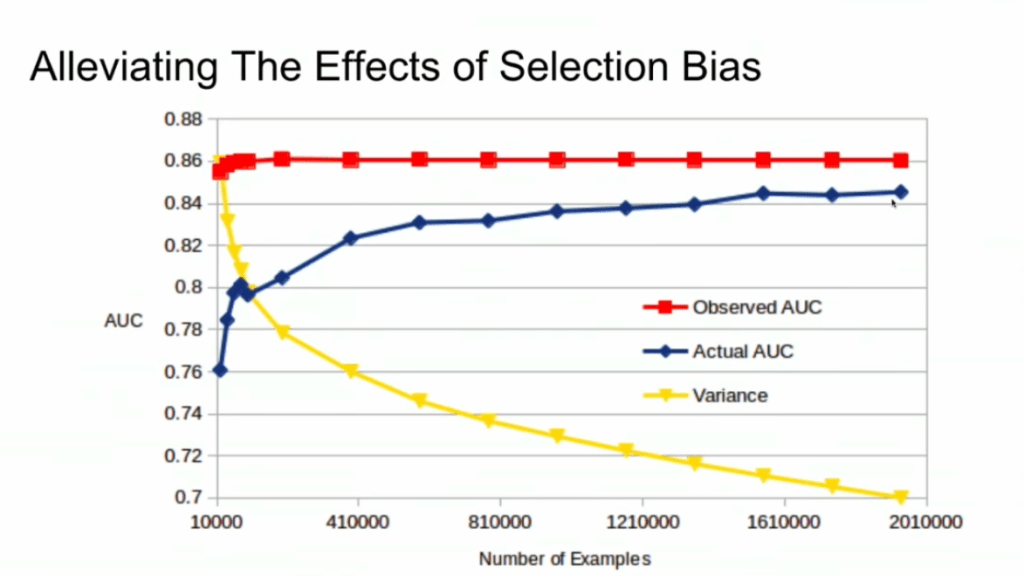
This is very much an issue, even though many ML practitioners don’t see aware. Selection bias makes us blind as to the real performance of our machine learning models. It produces high variance in the region of our feature space where labels are missing. This leads us to being overconfident in our ability to predict whether some user is looking for a family trip. And if the mechanism causing the selection bias is still there, we could never find out that we are overconfident. Consistently estimating, say, 30% of people are looking for family trips, whereas only 25% are.
Fortunately, Lucas proposes a very simple solution! Just adding more observations can (partially) alleviate this detrimental effect of selection bias. Although our bias still remains, the variance goes down and the difference between our observed and actual performance decreases.
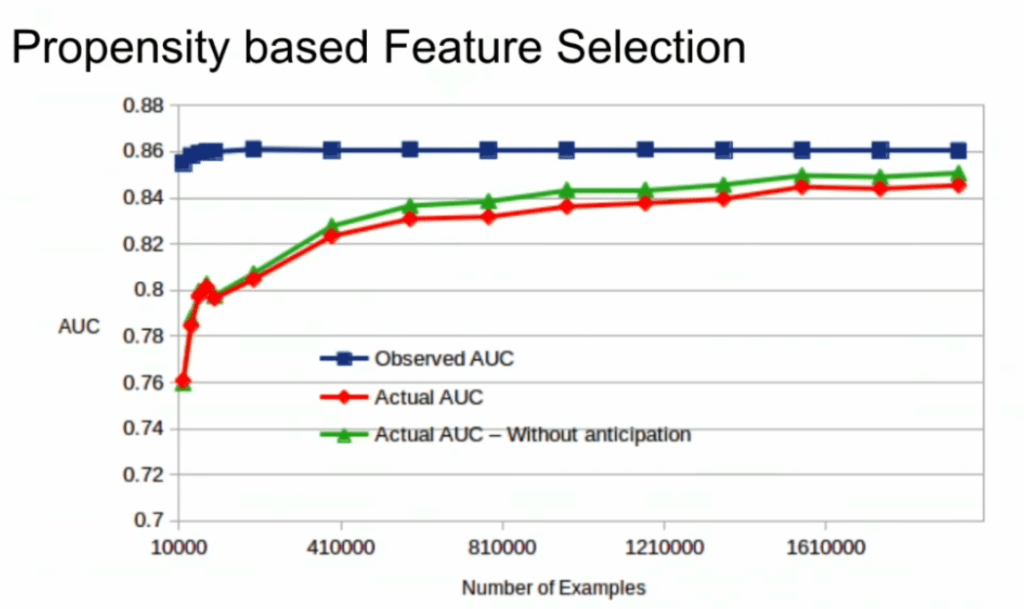
A second issue and solution to selection bias relates to propensity (see also): the extent to which your features X influence not only the outcome Y, but also the selection criteria s.
If our features X influence both the outcome Y but also the selection criteria s, selection bias will occur in your data and can thus screw up your conclusion. In order to inspect to what extent this occurs in your setting, you will want to estimate a propensity model. If that model is good, and X appears valuable in predicting s, you have a selection bias problem.
Via a propensity model s ~ X, we quantify to what extent selection bias influences our data and model. The nice thing is that we, as data scientists, control the features X we use to train a model. Hence, we could just use only features X that do not predict s to predict Y. Conclusion: we can conduct propensity-based feature selection in our Y ~ X by simply avoiding features X that predicted s!
Still, Lucas does point that this becomes difficult when you have valuable features that predict both s and Y. Hence, propensity-based feature selection may end up cost(ing) you performance, as you will need to remove features relevant to Y.