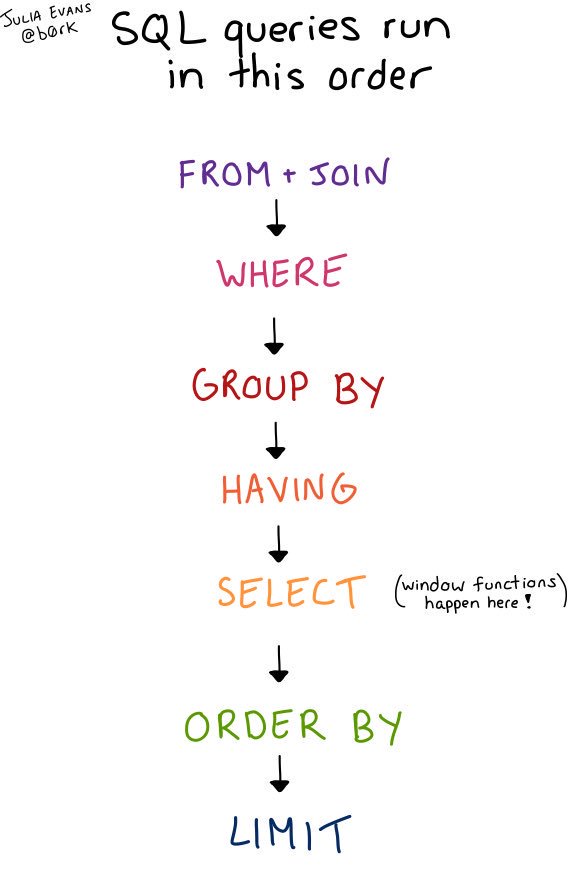
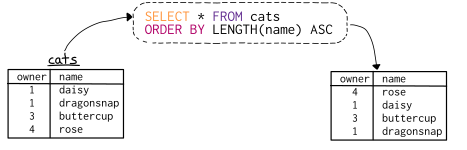
This zine explains SELECT queries step by step with tons of examples that will show you exactly what’s happening when you run a query. You’ll be able to easily translate your questions about your data into queries and get answers fast.
The magazine will set you back 12 dollars, but will make you a SQL master in no time. Plus, you will always have a cheat sheet by hand! Here’s what’s in it:
Here’s some of the actual contents you can expect, via Julia’s Twitter and the original webpage:
The title of the magazine is also quite well thought out : ) I hope you enjoy it!
This video I’ve been meaning to watch for a while now. It another great visual explanation of a statistics topic by the 3Blue1Brown Youtube channel (which I’ve covered before, multiple times).
This time, it’s all about Bayes theorem, and I just love how Grant Sanderson explains the concept so visually. He argues that rather then memorizing the theorem, we’d rather learn how to draw out the context. Have a look at the video, or read my summary below:
Grant Sanderson explains the concept very visually following an example outlined in Daniel Kahneman’s and Amos Tversky’s book Thinking Fast, Thinking Slow:
Steve is very shy and withdrawn, invariably helpful but with very little interest in people or in the world of reality. A meek and tidy soul, he has a need for order and structure, and a passion for detail.”
Is Steve more likely to be a librarian or a farmer?
Kahneman and Tversky argue that people take into account Steve’s disposition and therefore lean towards librarians.
However, few people take into account that librarians are quite scarce in our society, which is rich with farmers. For every librarian, there are 20+ farmers. Hence, despite the disposition, Steve is probably more like to be a farmer.
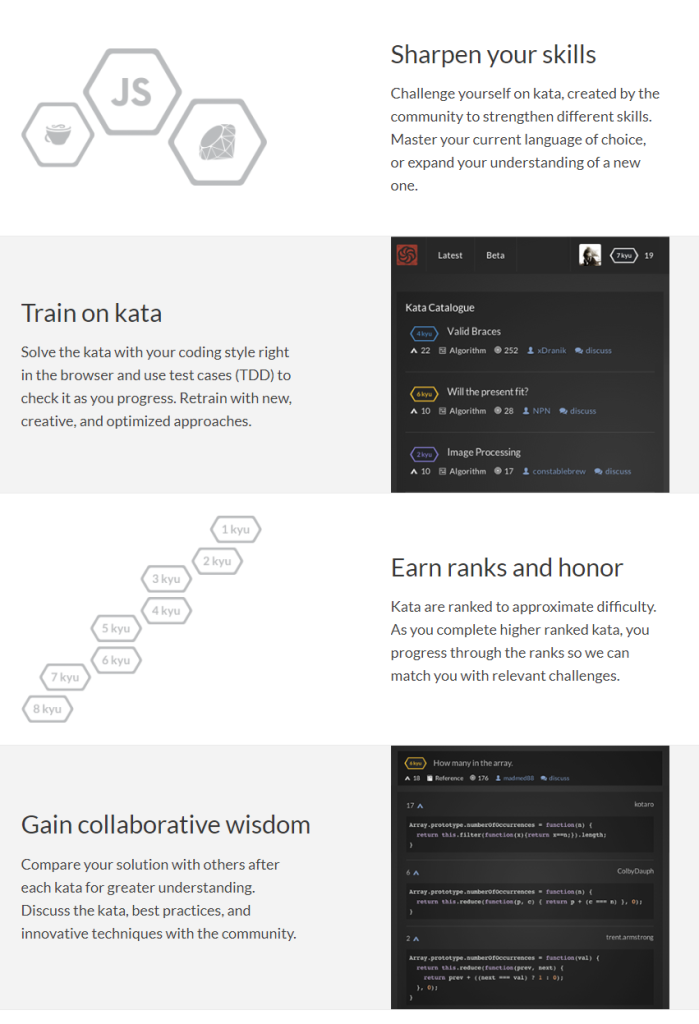
As I wrote about Project Euler and CodingGame before, someone recommended me CodeWars. CodeWars offers free online learning exercises to develop your programming skills through fun daily challenges.
In line with Project Euler, you are tasked with solving increasingly complex programming challenges. At CodeWars, these little problems you need to solve with code are called kata.
Kata take a test-driven development approach: the programs you write need to pass the tests of the developer who made the kata in the first place. Only then are you awarded with honour and can you earn your ranks and progress to the more complex kata.
Sounds fun right? I’m definitely going to check this out, as they support a wide range of programming languages, each with many kata to solve!
Python, Ruby, C++, Java, JavaScript and many other main programming languages are already supported, but CodeWards is also still developing kata for more niche or upcoming languages like R, Lua, Kotlin, and Scala.
Reddit is a treasure trove of random stuff. However, every now and then, in the better groups, quite valuable topics pop up. Here’s one I came across on r/statistics:
Particularly the advice by grandzooby seemed worth a like, and he linked to several useful resources which I’ve summarized for you below.
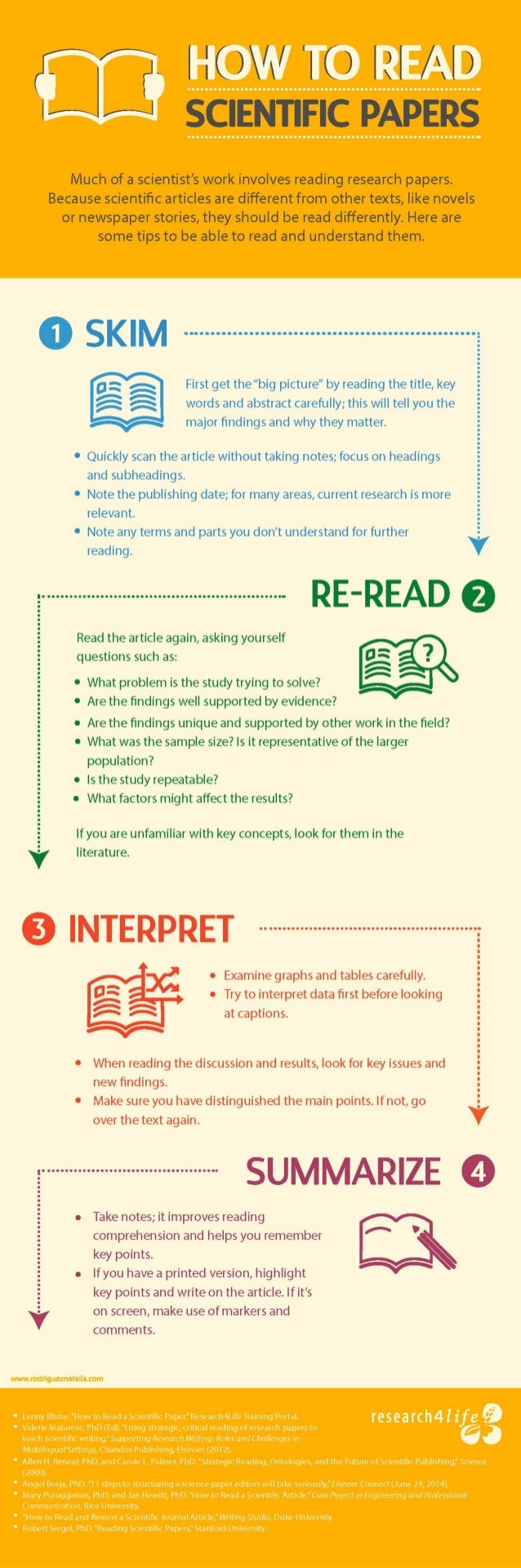
An 11-step guide to reading a paper
Jennifer Raff — assistant professor at the University of Kansas — wrote this 3-page guide on how to read papers. It elaborates on 11 main pieces of advice for reading academic papers:
Begin by reading the introduction, skip the abstract.
Identify the general problem: “What problem is this research field trying to solve?”
Try to uncover the reason and need for this specific study.
Identify the specific problem: “What problems is this paper trying to solve?”
Identify what the researchers are going to do to solve that problem
Read & identify the methods: draw the studies in diagrams
Read & identify the results: write down the main findings
Determine whether the results solve the specific problem
Read the conclusions and determine whether you agree
Mary Purugganan and Jan Hewitt of Rice University propose slightly different steps for reading academic papers. Though they seem more general pointers to keep in mind to me:
Skim the article and identify its structure
Distinguish its main points
Generate questions before and during reading
Draw inferences while reading
Take notes while reading
Regarding the note taking Mary and Jan propose the following template which may proof useful:
Citation:
URL:
Keywords:
General subject:
Specific subject:
Hypotheses:
Methodology:
Results:
Key points:
Context (in the broader field/your work):
Significance (to the field/your work):
Important figures/tables (description/page numbers):
References for further reading:
Other comments:
Scholars sharing their experiences
Science Magazine dedicated a long read to how to seriously read scientific papers, in which they asked multiple scholars to share their experiences and tips.
Anatomy of a scientific paper
This 13-page guide by the American Society of Plant Biologists was recommended by some, but I personally don’t find it as useful as the other advices here. Nevertheless, for the laymen, it does include a nice visualization of the anatomy of scientific papers:
This course gives you easy access to the invaluable learning techniques used by experts in art, music, literature, math, science, sports, and many other disciplines. We’ll learn about the how the brain uses two very different learning modes and how it encapsulates (“chunks”) information. We’ll also cover illusions of learning, memory techniques, dealing with procrastination, and best practices shown by research to be most effective in helping you master tough subjects.
Finland developed a crash course on AI to educate its citizens. The course was arguably a great local success, with over 50 thousand Fins taking the course (1% of the population).
Now, as a gift to the European Union, Finland has opened up the course for the rest of Europe and the world to enjoy.
All pictures are screenshots taken from the website
The course is even being translated into several local languages. At the time of writing, five Northern European languages are already supported, but additional translation efforts are still in progress.
Elements of AI takes six weeks and functions as a crash course and beginner introduction to the field of AI:
Harvard (bio)statisticians Miguel Hernan and Jamie Robins just released their new book, online and accessible for free!
The Causal Inference book provides a cohesive presentation of causal inference, its concepts and its methods. The book is divided in 3 parts of increasing difficulty: causal inference without models, causal inference with models, and causal inference from complex longitudinal data. Here’s the official Harvard page for the book release.
This is definitely an interesting read for epidemiologists, statisticians, psychologists, economists, sociologists, political scientists, data scientists, computer scientists, and any other person with a love for proper data analysis!