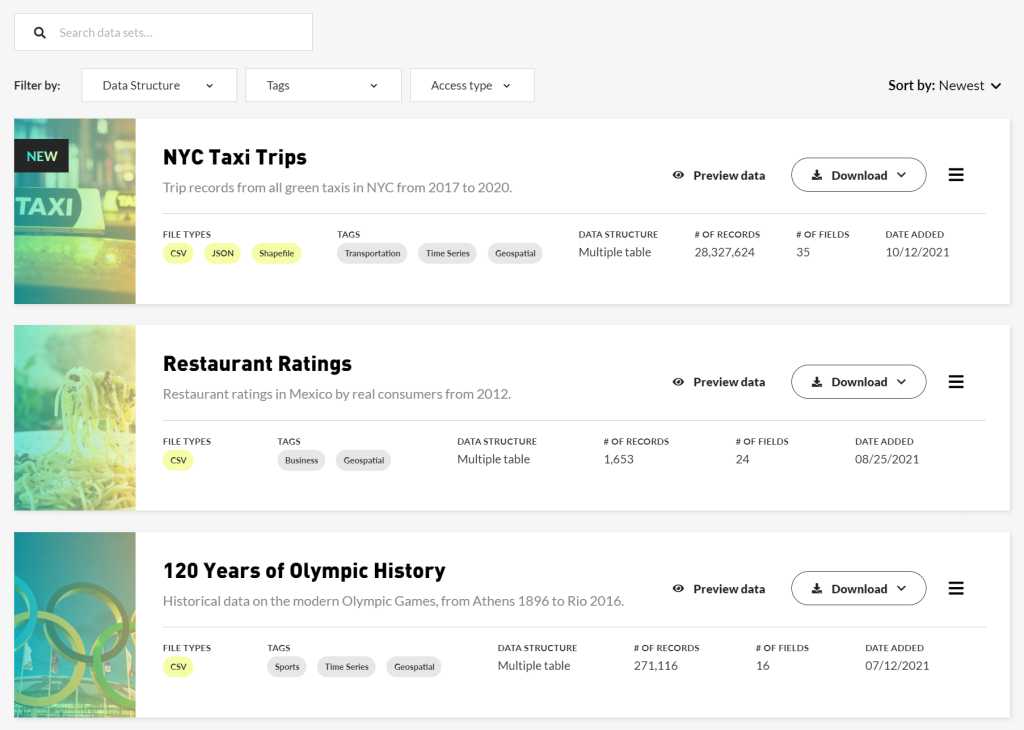
Shai Shalev-Shwartz and Shai Ben-David of the Hebrew University of Jerusalem made their machine learning book free to download.
The book covers the basic foundations up to advanced theory and algorithms. I copied the table of contents below. It’s kind of math heavy, but well explained with visual examples and pseudo-code.
Moreover, the book contains multiple exercises for you to internalize the knowledge and skills.
As an added bonus, the professors teach a number of machine learning courses, the lecture slides and materials of which you can also access for free via the book’s website.
Machine learning is one of the fastest growing areas of computer science, with far-reaching applications. The aim of this textbook is to introduce machine learning, and the algorithmic paradigms it offers, in a principled way. The book provides a theoretical account of the fundamentals underlying machine learning and the mathematical derivations that transform these principles into practical algorithms. Following a presentation of the basics, the book covers a wide array of central topics unaddressed by previous textbooks. These include a discussion of the computational complexity of learning and the concepts of convexity and stability; important algorithmic paradigms including stochastic gradient descent, neural networks, and structured output learning; and emerging theoretical concepts such as the PAC-Bayes approach and compression-based bounds. Designed for advanced undergraduates or beginning graduates, the text makes the fundamentals and algorithms of machine learning accessible to students and non-expert readers in statistics, computer science, mathematics and engineering.
About the book
If you want to reward the professors for their efforts, please do buy a hardcopy version of book.
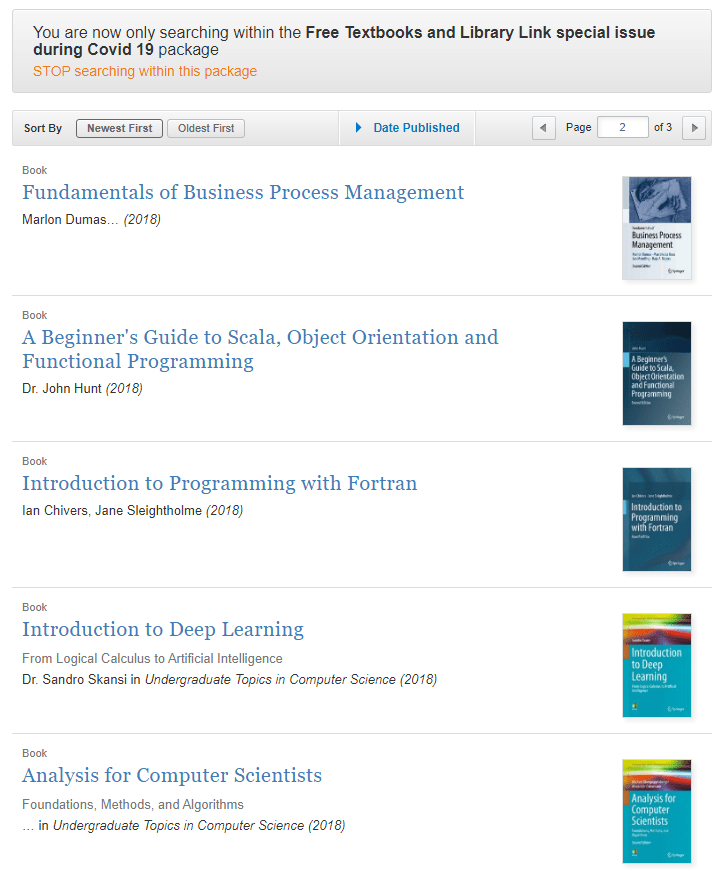
Table of contents
Part I: Foundations
- A gentle start
- A formal learning model
- Learning via uniform convergence
- The bias-complexity trade-off
- The VC-dimension
- Non-uniform learnability
- The runtime of learning
Part II: From Theory to Algorithms
- Linear predictors
- Boosting
- Model selection and validation
- Convex learning problems
- Regularization and stability
- Stochastic gradient descent
- Support vector machines
- Kernel methods
- Multiclass, ranking, and complex prediction problems
- Decision trees
- Nearest neighbor
- Neural networks
Part III: Additional Learning Models
- Online learning
- Clustering
- Dimensionality reduction
- Generative models
- Feature selection and generation
Part IV: Advanced Theory
- Rademacher complexities
- Covering numbers
- Proof of the fundamental theorem of learning theory
- Multiclass learnability
- Compression bounds
- PAC-Bayes
Appendices
- Technical lemmas
- Measure concentration
- Linear algebra