How do scurvy, astronomy, alchemy and data science relate to each other?
In this goto conference presentation, Lucas Vermeer — Director of Experimentation at Booking.com — uses some amazing storytelling to demonstrate how the value of data (science) is largely by organizations capability to gather the right data — the data they actually need.
It’s a definite recommendation to watch for data scientists and data science leaders out there.
Here are the slides, and they contain some great oneliners:
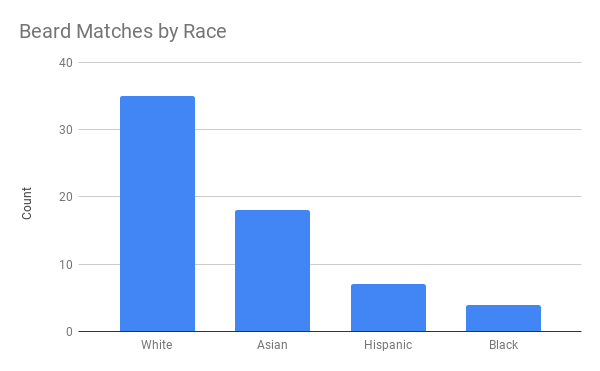
This WordPress blogger I came across — let’s call him “John” for now — has a very peculiar way of testing out his looks. Using dating-apps like Tinder, John conducted A/B-tests to find out whether people would prefer him romantically with or without a beard.
Via a proper experimental setup, John found out that bearded John receives much more attention in the form of Tinder matches. However, not from girls whom John characterized as being asian, that group seemed to prefer shaven John.
While the sample size was not too large (Nbearded = 500; Nshaven = 500) and the response rate even lower (Nbearded = 64; Nshaven = 30), this seems like a fun way to make your look more data-driven!
I wrote about Emily Robinson and her A/B testing activities at Etsy before, but now she’s back with a great new blog full of practical advice: Emily provides 12 guidelines for A/B testing that help to setup effective experiments and mitigate data-driven but erroneous conclusions:
Decision making under uncertainty is complicated. These days, many business rely on real-life experiments, or A/B tests, to reduce that uncertainty and improve their decision-making. For instance, here’s a presentation on how A/B testing helps improve business outcomes at Etsy.
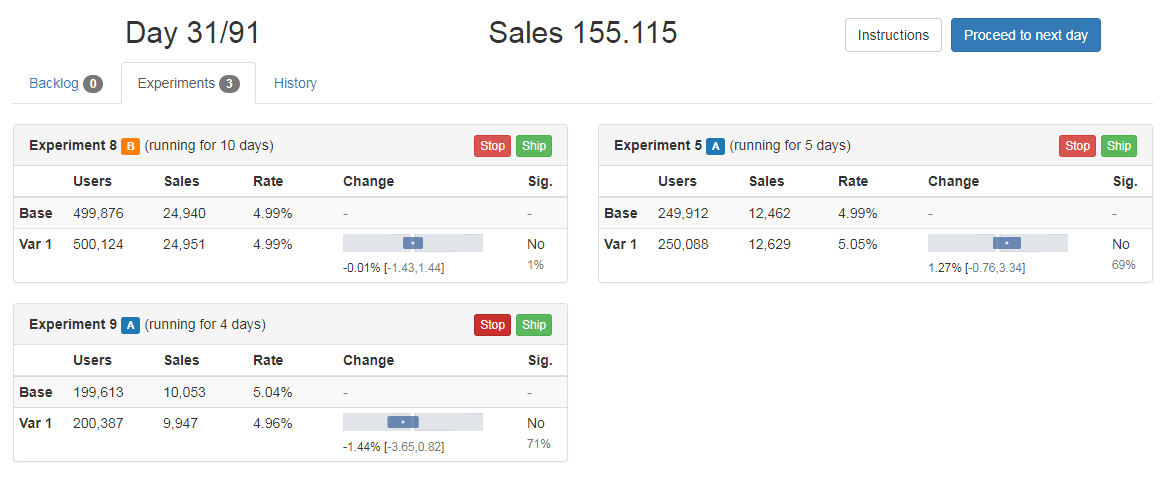
Lukas Vermeer built So You Think You Can Test, an online simulation game in which you are the decision-maker in a company. You control the backlog and running of experiments and each day you have to decide which tasks to prioritize (or deleted entirely). Your decisions affect the sales of the company, so be wise and use the experimental information to your advantage.
The below reiterates and summarizes this Stat article.
Recently, I addressed how bias may slip into Machine Learning applications and this weekend I came across another real-life example: IBM’s Watson, specifically Watson for Oncology. With a single machine, IBM intended to tackle humanity’s most vexing diseases and revolutionize medicine and they quickly zeroed in on a high-profile target: cancer.
However, three years later now, a STAT investigation has found that the supercomputer isn’t living up to the lofty expectations IBM created for it. IBM claims that, through Artificial Intelligence, Watson for Oncology can generate new insights and identify “new approaches” to cancer care. However, the STAT investigation (video below) concludes that the system doesn’t create new knowledge and is artificially intelligent only in the most rudimentary sense of the term. Similarly, cancer specialists using the product argue Watson is still in its “toddler stage” when it comes to oncology.
Let’s start with the positive side. For specific treatments, Watson can scan academic literature, immediately providing the “best data” about a treatment — survival rates, for example — thereby relieving doctors of tedious literature searches. Due to this transparency, Watson may level the hierarchy commonly found in hospital settings, by holding (senior) doctors accountable to the data and empowering junior physicians to back up their arguments. Furthermore, Watson’s information may empower patients as they can be offered a comprehensive packet of treatment options, including potential treatment plans along with relevant scientific articles. Patients can do their own research about these treatments, and maybe even disagree with the doctor about the right course of action.
Although study results demonstrate that Watson saves doctors time and can have a high concordance rate with their treatment recommendations, much more research is needed. The studies were all conference abstracts, which haven’t been published in peer-reviewed journals — and all but one was either conducted by a paying customer or included IBM staff on the author list, or both. More importantly, IBM has failed to exposed Watson for Oncology to critical review by outside scientists nor have they conducted clinical trials to assess its effectiveness. It would be very interesting to examine whether Watson’s implementation is actually saving lives or making healthcare more efficient/effective.
IBM Watson HealthSuch validation is especially necessary because several issues are identified. First, the actual capabilities of Watson for Oncology are not well-understood by the public, and even by some of the hospitals that use it. It’s taken nearly six years of painstaking work by data engineers and doctors to train Watson in just seven types of cancer, and keep the system updated with the latest knowledge. Moreover, because of the complexity of the underlying machine learning algorithms, the recommendations Watson puts out are a black box, and Watson can not provide the specific reasons for picking treatment A over treatment B.
Second, the system is essentially Memorial Sloan Kettering in a portable box. IBM celebrates Memorial Sloan Kettering’s role as the only trainer of Watson. After all, who better to educate the system than doctors at one of the world’s most renowned cancer hospitals? However, doctors claim that Memorial Sloan Kettering’s training has caused bias in the system, because the treatment recommendations it puts into Watson don’t always comport with the practices of doctors elsewhere in the world. When users ask Watson for advice, the system also searches published literature — some of which is curated by Memorial Sloan Kettering — to provide relevant studies and background information to support its recommendation. But the recommendation itself is derived from the training provided by the hospital’s doctors, not the outside literature.
Doctors at Memorial Sloan Kettering acknowledged their influence on Watson. “We are not at all hesitant about inserting our bias, because I think our bias is based on the next best thing to prospective randomized trials, which is having a vast amount of experience,” said Dr. Andrew Seidman, one of the hospital’s lead trainers of Watson. “So it’s a very unapologetic bias.”
However, this bias causes serious problems when Watson for Oncology is implemented in other countries/hospitals. The generally affluent population treated at Memorial Sloan Kettering doesn’t reflect the diversity of people around the world. According to Martijn van Oijen, an epidemiologist and associate professor at Academic Medical Center in the Netherlands, Watson has not been implemented in because of country level differences in treatment approaches. Similarly, oncologists at one hospital in Denmark said they have dropped implementation altogether after finding that local doctors agreed with Watson in only about 33 percent of cases. Different problems occurred in South Korea, where researchers reported that the treatment Watson most often recommended for breast cancer patients simply wasn’t covered by their national insurance system.
Kris, the lead trainer at Memorial Sloan Kettering, says nobody wants to hear the problems. “All they want to hear is that Watson is the answer. And it always has the right answer, and you get it right away, and it will be cheaper. But like anything else, it’s kind of human.”
Veritasium makes educational video’s, mostly about science, and recently they recorded one offering an intuitive explanation of Bayes’ Theorem. They guide the viewer through Bayes’ thought process coming up with the theory, explain its workings, but also acknowledge some of the issues when applying Bayesian statistics in society.
“The thing we forget in Bayes’ Theorem is that our actions play a role in determining outcomes, in determining how true things actually are.” 8.23
“A really good understanding of Bayes’ Theorem implies that experimentation is essential: if you’ve been doing the same thing for a long time and getting the same result – that you’re not necessarily happy with – maybe it’s time to change.” 8.48










![imaging-video[1].jpg](https://paulvanderlaken.com/wp-content/uploads/2017/09/imaging-video1.jpg)
