How do scurvy, astronomy, alchemy and data science relate to each other?
In this goto conference presentation, Lucas Vermeer — Director of Experimentation at Booking.com — uses some amazing storytelling to demonstrate how the value of data (science) is largely by organizations capability to gather the right data — the data they actually need.
It’s a definite recommendation to watch for data scientists and data science leaders out there.
Here are the slides, and they contain some great oneliners:
YouTube recommended I’d watch this recorded presentation by Raymond Hettinger at PyBay2019 last October. Quite a long presentation for what I’d normally watch, but what an eye-openers it contains!
Raymond Hettinger is a Python core developer and in this video he presents 10 programming strategies in these 60 minutes, all using live examples. Some are quite obvious, but the presentation and examples make them very clear. Raymond presents some serious programming truths, and I think they’ll stick.
First, Raymond discusses chunking and aliasing. He brings up the theory that the human mind can only handle/remember 7 pieces of information at a time, give or take 2. Anything above proves to much cognitive load, and causes discomfort as well as errors. Hence, in a programming context, we need to make sure programmers can use all 7 to improve the code, rather than having to decypher what’s in front of them. In a programming context, we do so by modularizing and standardizing through functions, modules, and packages. Raymond uses the Python random module to hightlight the importance of chunking and modular code. This part was quite long, but still interesting.
For the next two strategies, Raymond quotes the Feinmann method of solving problems: “(1) write down a clear problem specification; (2) think very, very hard; (3) write down a solution”. Using the example of a tree walker, Raymond shows how the strategies of incremental development and solving simpler programs can help you build programs that solve complex problems. This part only lasts a couple of minutes but really underlines the immense value of these strategies.
Next, Raymond touches on the DRY principle: Don’t Repeat Yourself. But in a context I haven’t seen it in yet, object oriented programming [OOP], classes, and inherintance.
Raymond continues to build his arsenal of programming strategies in the next 10 minutes, where he argues that programmers should repeat tasks manually until patterns emerge, before they starting moving code into functions. Even though I might not fully agree with him here, he does have some fun examples of file conversion that speak in his case.
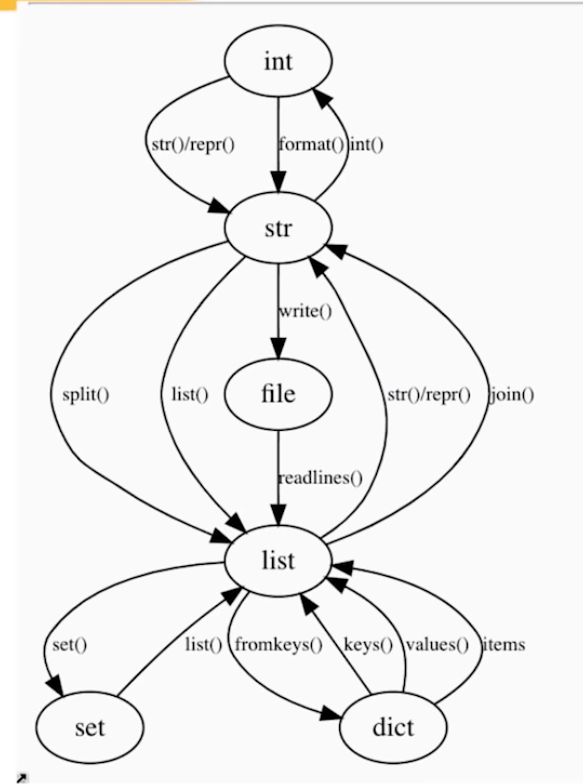
Lastly, Raymond uses the graph below to make the case that OOP is a graph traversal problem. According to Raymond, the Python ecosystem is so rich that there’s often no need to make new classes. You can simply look at the graph below. Look for the island you are currently on, check which island you need to get to, and just use the methods that are available, or write some new ones.
While there were several more strategies that Raymond wanted to discuss, he doesn’t make it to the end of his list of strategies as he spend to much time on the first, chunking bit. Super curious as to the rest? Contact Raymond on Twitter.
Wanting to broaden your scope and learn a new programming language? This great workshop was given at EARL 2018 by Mango Solutions and helps R programmers transition into Python building on their existing R knowledge. The workshop includes exercises that introduce you to the key concepts of Python and some of its most powerful packages for data science, including numpy, pandas, sklearn, and seaborn.
Have a look at the associated workshop guide that walk you through the assignments, or at the github repo with all materials in Jupyter notebooks.
Fortunately, so much of the conference is shared on Twitter and media outlets that I still felt included. Here are some things that I liked and learned from, despite the Austin-Tilburg distance.
Garrick Aden-Buie made a fabulous Shiny app that allows you to review all #rstudioconf tweets during and since the conference. It even includes some random statistics about the tweets, and a page with all the shared media.
Data scientists can fail by: ❌not saying no enough ❌not providing anything more than a cursory analysis ❌assuming PM knows enough to ask question in the right way and not collaborating with them ❌caring more about using fancy method than solving business problems#rstudioconf
Did you know that RStudio also posts all the webinars they host? There really are some hidden pearls among them. For instance, this presentation by Nathan Stephens on rendering rmarkdown to powerpoint will save me tons of work, and those new to broom will also be astonished by this webinar by Alex Hayes.
PyData provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other. The communities approach data science using many languages, including (but not limited to) Python, Julia, and R.
April 2018, a PyData conference was held in London, with three days of super interesting sessions and hackathons. While I couldn’t attend in person, I very much enjoy reviewing the sessions at home as all are shared open access on YouTube channel PyDataTV!
In the following section, I will outline some of my favorites as I progress through the channel:
Winning with simple, even linear, models:
One talk that really resonated with me is Vincent Warmerdam‘s talk on “Winning with Simple, even Linear, Models“. Working at GoDataDriven, a data science consultancy firm in the Netherlands, Vincent is quite familiar with deploying deep learning models, but is also midly annoyed by all the hype surrounding deep learning and neural networks. Particularly when less complex models perform equally well or only slightly less. One of his quote’s nicely sums it up:
“Tensorflow is a cool tool, but it’s even cooler when you don’t need it!”
— Vincent Warmerdam, PyData 2018
In only 40 minutes, Vincent goes to show the finesse of much simpler (linear) models in all different kinds of production settings. Among others, Vincent shows:
how to solve the XOR problem with linear models
how to win at timeseries with radial basis features
how to use weighted regression to deal with historical overfitting
how deep learning models introduce a new theme of horror in production
how to create streaming models using passive aggressive updating
how to build a real-time video game ranking system using mere histograms
how to create a well performing recommender with two SQL tables
how to rock at data science and machine learning using Python, R, and even Stan