The following are my summary and take-aways from Janelle Shane’s 2019 book named You look like a thing and I love you. Most of the below are excerpts from Janelle’s book, combined, or rewritten by me. For the sake of copyright, just consider everything Janelle’s : )
AI weirdness
You look like a thing and I love you is about AI. More specifically, the book is about what AI can and can not do. And how and why AI often fails in miserably hilareous ways.
Janelle has spend her time foing fun experiments with AI. In this book, she shares those experiments along with many real life examples of AIs in practice. While explaining the technical details behind these AIs in an accesible though technically correct way, she informs the reader where, how, and why AIs fail.
Janelle took AIs out of their comfort zone and it produced some hilareously weird results. She proposes five principles of AI Weirdness:
The danger of AI is not that it’s too smart, but that it’s not smart enough
AI has the approximate brainpower of a worm
AI does not really understand the problem you want it to solve
But: AI will do exactly what you tell it to. Or at least it will try its best.
And AI willt ake the path of the least resistance
Definitions: What is (not) AI?
If it seems like AI is everywhere, it’s partly because Artificial Intelligence means lots of things, depending on whether you’re reading science fiction or selling a new app or doing academic research.
To spot an AI in the wild, it’s important to know the difference between machine learning algorithms (what Janelle calls AI in her book) and traditional, rules-based programs.
To solve a problem with a rules-based program, you have to know every step required to complete the program’s task and how to describe each one of those steps. But a machine learning algorithm figures out the rules for itself via trail and error, gauging its success on goals the programmer has specified. As the AI tries to reach this goal, it can discover rules and correlations that the programmer didn’t even know existed. This is what makes AIs attractive problem solvers and is particularly handy if the rules are really complicated or just plain mysterious.
Sometimes an AI’s brilliant problem-solving rules actually rely on mistaken assumptions. Rules that served it well in training but fail miserably when it encountered the real world. While training errors are common in complex AIs, the consequences of these mistakes can be serious.
It’s often not easy to tell when AIs make mistakes. Since we don’t write the rules, they come up with their own, and they don’t write them down or explain them the way a human would.
The difference between succesful AI problem solving and failure usually has a lot to do with the suitability of the task for an AI solution. And there are plenty of tasks for which AI solutions are more efficient than human solutions. But there are also plenty of cases where things go miserably wrong.
Janelle proposes four signs of “AI Doom”, contexts where machine learning will not produce the desired results:
The problem is too hard, broad, or complex
The problem is not what we thought it was
There are sneaky shortcuts to solving the problem
The AI tried to solve the problem learning from flawed data
Programming an AI is almost more like teaching a child than programming a computer.
Explaining how AI works
In her book, Janelle takes us through many example problems which she or others tried to solve using AIs. These example problems are increasingly hilareous, but I assure you that they are technically and didactically sound:
Playing tic-tac-toe
Managing a cockroach farm
Riding a bicycle
Rating sandwich deliciousness
Tossing a sandwich into a wall
Guiding people through a hallway
Answering questions regarding photo’s
Categorizing doodles
Categorizing fish
Tossing pancakes
Autonomous walking
Autonomous driving
Playing Pacman
The amazing thing is these ridiculous example problems actually serve a purpose. They are used to explain different algorithms and their applications, strengths, and limitations! Janelle covers a wide variety of algorithms in such a way that anyone new to machine learning would understand, while people with some experience will still be amused.
Janelle talks about artificial neural networks, random forests, and markov chains. Moreover, she explains how activation functions, recurrancy and long short-term memory, evolutionary algorithms and gradient descent work. And all in understandable though technically correct language.
Janelle herself seems particularly fond of generative algorithms. She’s elaborates on having deployed recurrent neural nets, generative adversial networks, and markov chains for a wide variety of generative tasks. In the book, Jabekke explains what went well and went wrong when coming up with new and original…
Janelle’s book is lingered with examples of failing AI. As a matter of fact, the whole book seems like an ode to how machine learning can and will inevitably fail. Particularly in the latter chapters, Janelle covers many limitations of and issues with AI in much detail:
I have yet to come across a book that explain AI in this much detail and in a manner as accessible and entertaining as Janelle Shane does in You look like a thing and I love you. Janelle makes machine learning and AI understandable for a wide public without passing on the deeper technical details. Taking a critical stance, she provides a good overview of the strenghts and weaknesses of AI, and a realistic outlook for the future to come. This book is not looking for sensation or hype, although reading it will be a most amusing experience for the more technical as well as the lay reader.
I highly recommend you reward yourself with a copy!
I’ve seen some uses of reinforcement learning and generative algorithms for architectural purposes already, like these evolving blueprints for school floorplans. However, this new application called ArchiGAN blew me away!
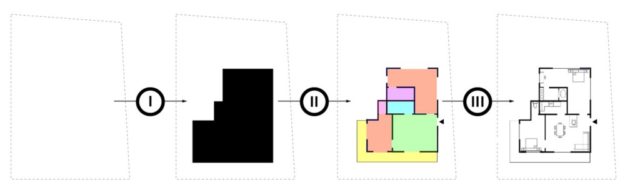
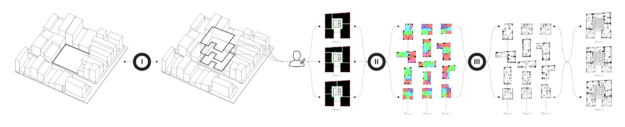
ArchiGAN (try here) was made by Stanislas Chaillou as a Harvard master’s thesis project. The program functions in three steps:
building footprint massing
program repartition
furniture layout
Stanislas’ three generation steps
Each of these three steps uses a TensorFlow Pix2Pix GAN-model (Christopher Hesse’s implementation) in the back-end, and their combination makes for a entire apartment building “generation stack” — according to Stanislas — which also allows for user input at each step.
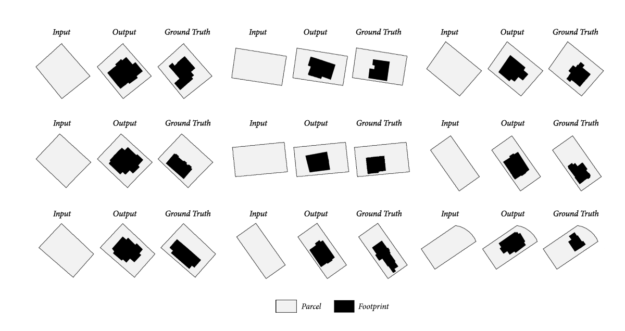
The design of a building can be inferred from the piece of land it stands on. Hence, Stanislas fed his first model using GIS-data (Geographic Information System) from the city of Boston in order to generate typical footprints based on parcel shapes.
The inputs and outputs of model I
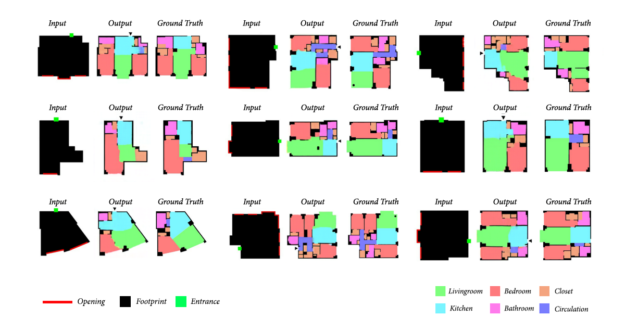
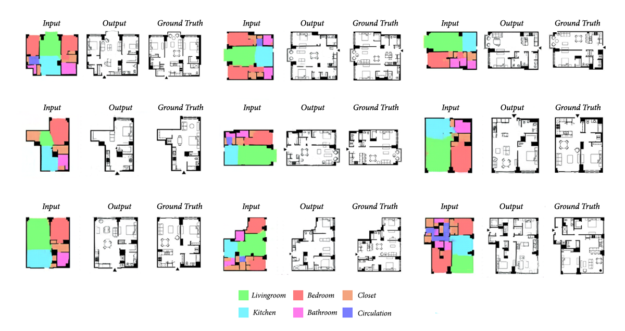
Stanislas’ second model was responsible for repartition and fenestration (the placement of windows and doors). This GAN took the footprint of the building (the output of model I) as input, along with the position of the entrance door (green square), and the positions of the user-specified windows.
Stanislas used a database of 800+ plans of apartments for training. To visualize the output, rooms are color-coded and walls and fenestration are blackened.
The inputs and outputs of model II
Finally, in the third model, the rooms are filled with appropriate furniture. What training data Stanislas has used here, he did not specify in the original blog.
The inputs and outputs of model III
Now, to put all things together, Stanislas created a great interactive tool you can play with yourself. The original NVIDEA blog contains some great GIFs of the tool being used:
Stanislas’ GAN-models progressively learned to design rooms and realistically position doors and windows. It took about 250 iterations to get some realistic floorplans out of the algorithm. Here’s how an example learning sequence looked like:
Visualization of the training process
Now, Stanislas was not done yet. He also scaled the utilization of GANs to design whole apartment buildings. Here, he chains the models and processes multiple units as single images at each step.
Generating whole appartment blocks using ArchiGAN
Stanislas did other cool things to improve the flexibility of his ArchiGAN models, about which you can read more in the original blog. Let these visuals entice you to read more:
ArchiGAN scaled to handle whole appartment blocks and neighborhoods.
I believe a statistical approach to design conception will shape AI’s potential for Architecture. This approach is less deterministic and more holistic in character. Rather than using machines to optimize a set of variables, relying on them to extract significant qualities and mimicking them all along the design process represents a paradigm shift.
I am so psyched about these innovative applications of machine learning, so please help me give Stanislas the attention and credit he deserved.
Currently, Stanislas is Data Scientist & Architect at Spacemaker.ai. Read more about him in his NVIDEA developer bio here. He recently published a sequence of articles, laying down the premise of AI’s intersection with Architecture. Read here about the historical background behind this significant evolution, to be followed by AI’s potential for floor plan design, and for architectural style analysis & generation.