Google’s guidebook to human-centered AI design refered to the Design Kit, containing numerous helpful tools to help you design products with user experience in mind.
The design kit website contains many practical methods, tools, case studies and much more resources to help you in the design process.
Human-centered design is a practical, repeatable approach to arriving at innovative solutions. Think of these Methods as a step-by-step guide to unleashing your creativity, putting the people you serve at the center of your design process to come up with new answers to difficult problems.
The design kit methods section provides some seriously handy guidelines to help you design your products with the customer in mind. A step-by-step process guideline is offered, as well as neat worksheets to records the information you collect in the process, and a video explanation of the method.
As a company that uses a lot of automation, optimization, and machine learning in their day-to-day business, Google is set on developing AI in a socially responsible way.
Fortunately for us, Google decided to share their principles and best practices for us to read.
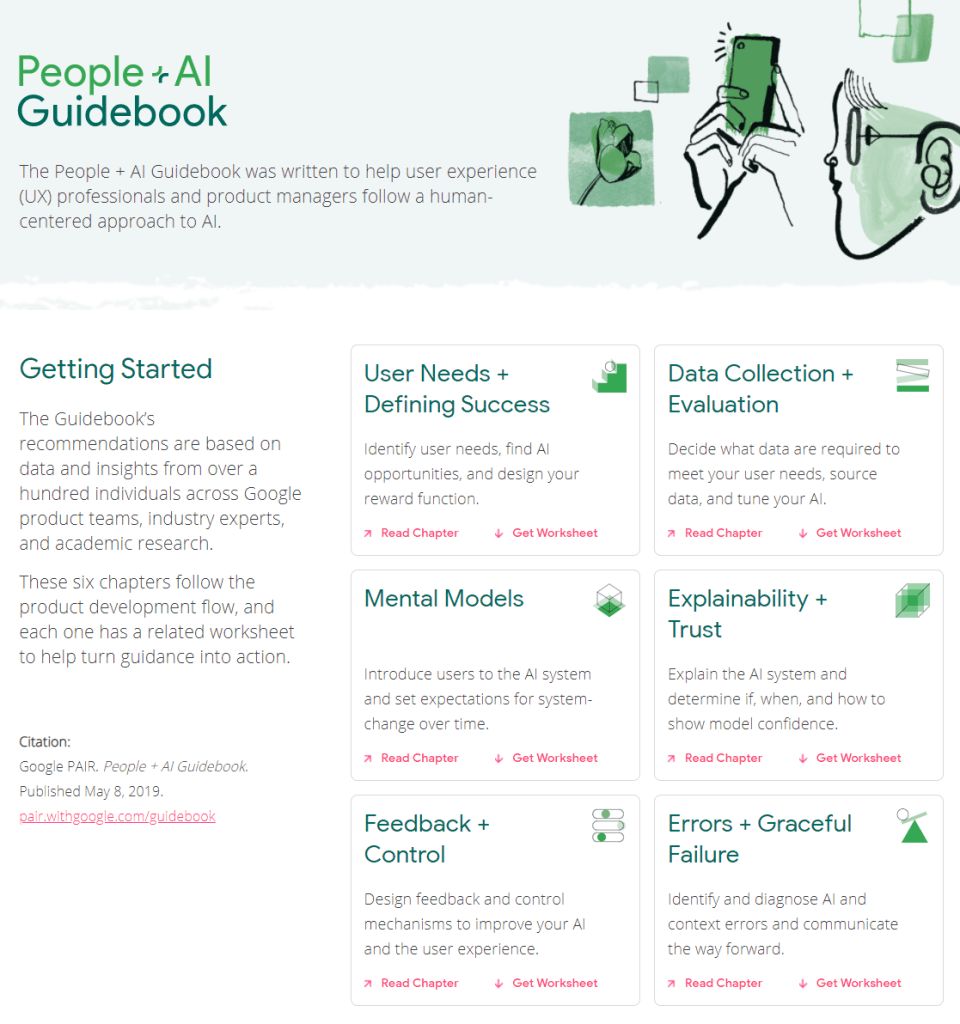
The People + AI Guidebook was written to help user experience (UX) professionals and product managers follow a human-centered approach to AI.
The Guidebook’s recommendations are based on data and insights from over a hundred individuals across Google product teams, industry experts, and academic research.
These six chapters follow the product development flow, and each one has a related worksheet to help turn guidance into action.
The People & AI guidebook is one of the products of the major PAIR project team (People & AI Research).
Here are the direct links to the six guidebook chapters:
Sometimes I find these AI / programming hobby projects that I just wished I had thought of…
Will Stedden combined OpenAI’s GPT-2 deep learning text generation model with another deep-learning language model by Google called BERT (Bidirectional Encoder Representations from Transformers) and created an elaborate architecture that had one purpose: posting the best replies on Reddit.
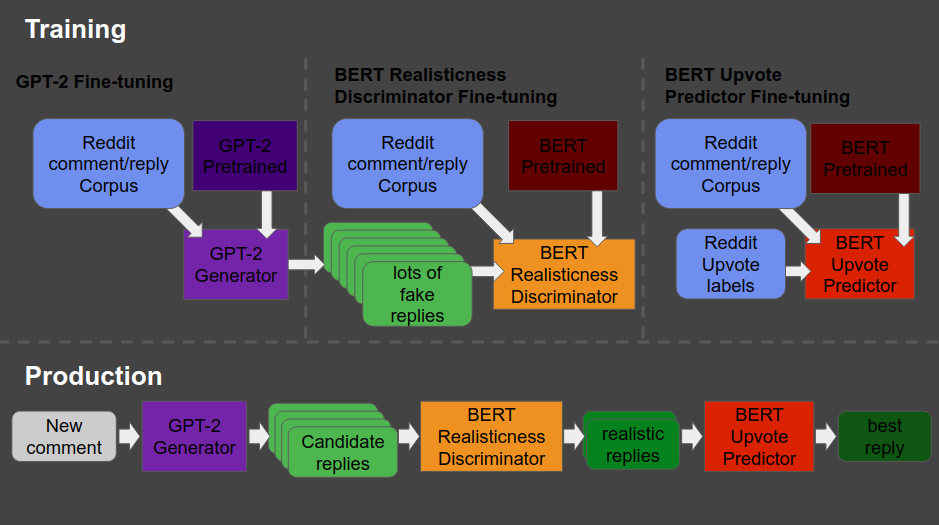
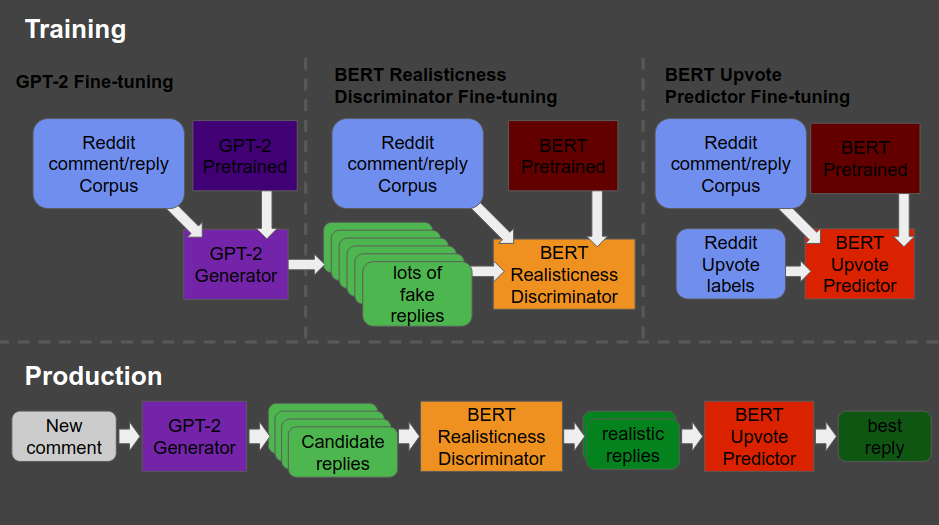
The architecture is shown at the end of this post — copied from Will’s original bloghere. Moreover, you can read this post for details regarding the construction of the system. But let me see whether I can explain you what it does in simple language.
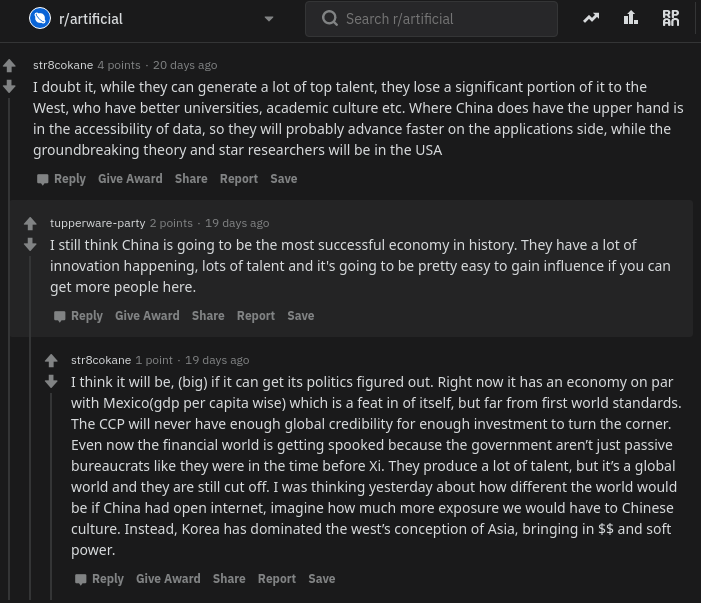
The below is what a Reddit comment and reply thread looks like. We have str8cokane making a comment to an original post (not in the picture), and then tupperware-party making a reply to that comment, followed by another reply by str8cokane. Basically, Will wanted to create an AI/bot that could write replies like tupperware-party that real people like str8cokane would not be able to distinguish from “real-people” replies.
Note that with 4 points, str8cokane‘s original comments was “liked” more than tupperware-party‘s reply and str8cokane‘s next reply, which were only upvoted 2 and 1 times respectively.
So here’s what the final architecture looks like, and my attempt to explain it to you.
Basically, we start in the upper left corner, where Will uses a database (i.e. corpus) of Reddit comments and replies to fine-tune a standard, pretrained GPT-2 model to get it to be good at generating (red: “fake”) realistic Reddit replies.
Next, in the upper middle section, these fake replies are piped into a standard, pretrained BERT model, along with the original, real Reddit comments and replies. This way the BERT model sees both real and fake comments and replies. Now, our goal is to make replies that are undistinguishable from real replies. Hence, this is the task the BERT model gets. And we keep fine-tuning the original GPT-2 generator until the BERT discriminator that follows is no longer able to distinguish fake from real replies. Then the generator is “fooling” the discriminator, and we know we are generating fake replies that look like real ones! You can find more information about such generative adversarial networks here.
Next, in the top right corner, we fine-tune another BERT model. This time we give it the original Reddit comments and replies along with the amount of times they were upvoted (i.e. sort of like likes on facebook/twitter). Basically, we train a BERT model to predict for a given reply, how much likes it is going to get.
Finally, we can go to production in the lower lane. We give a real-life comment to the GPT-2 generator we trained in the upper left corner, which produces several fake replies for us. These candidates we run through the BERT discriminator we trained in the upper middle section, which determined which of the fake replies we generated look most real. Those fake but realistic replies are then input into our trained BERT model of the top right corner, which predicts for every fake but realistic reply the amount of likes/upvotes it is going to get. Finally, we pick and reply with the fake but realistic reply that is predicted to get the most upvotes!
What Will’s final architecture, combining GPT-2 and BERT, looked like (via bonkerfield.org)
The results are astonishing! Will’s bot sounds like a real youngster internet troll! Do have a look at the original blog, but here are some examples. Note that tupperware-party — the Reddit user from the above example — is actually Will’s AI.
Will ends his blog with a link to the tutorial if you want to build such a bot yourself. Have a try!
Moreover, he also notes the ethical concerns:
I know there are definitely some ethical considerations when creating something like this. The reason I’m presenting it is because I actually think it is better for more people to know about and be able to grapple with this kind of technology. If just a few people know about the capacity of these machines, then it is more likely that those small groups of people can abuse their advantage.
I also think that this technology is going to change the way we think about what’s important about being human. After all, if a computer can effectively automate the paper-pushing jobs we’ve constructed and all the bullshit we create on the internet to distract us, then maybe it’ll be time for us to move on to something more meaningful.
If you think what I’ve done is a problem feel free to email me , or publically shame me on Twitter.
Looking for a custom typeface to use in your data visualizations? Google Fonts is an awesome databank of nearly a thousands font families you can access, download, and use for free.