In Glad You Asked, Vox dives deep into timely questions around the impact of systemic racism on our communities and in our daily lives.
In this video, they look into the role of tech in societal discrimination. People assume that tech and data are neutral, and we have turned to tech as a way to replace biased human decision-making. But as data-driven systems become a bigger and bigger part of our lives, we see more and more cases where they fail. And, more importantly, that they don’t fail on everyone equally.
Why do we think tech is neutral? How do algorithms become biased? And how can we fix these algorithms before they cause harm? Find out in this mini-doc:
Case.law seems like a very interesting data source for a machine learning or text mining project:
The Caselaw Access Project (“CAP”) expands public access to U.S. law. Our goal is to make all published U.S. court decisions freely available to the public online, in a consistent format, digitized from the collection of the Harvard Law Library.
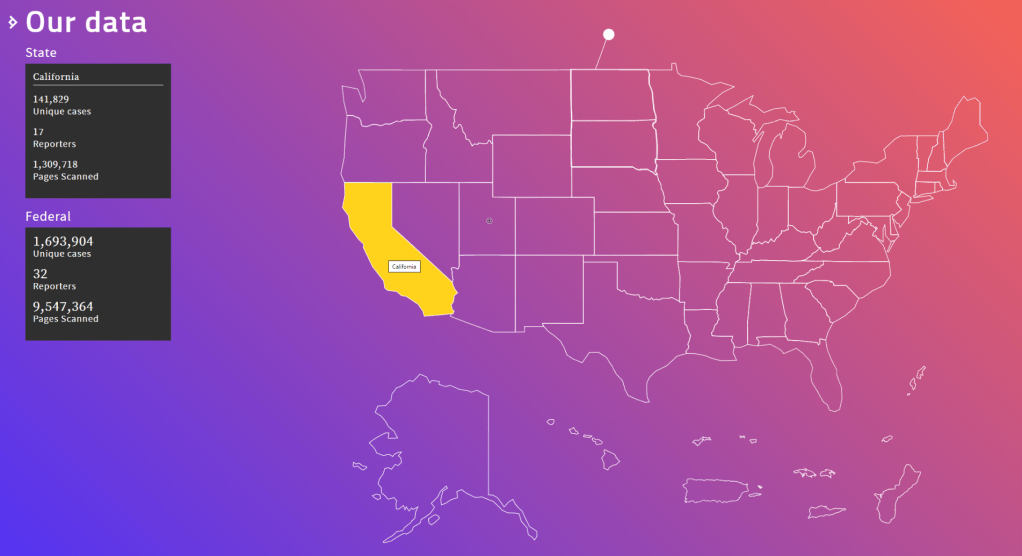
The capstone of the Caselaw Access Project is a robust set of tools which facilitate access to the cases and their associated metadata. We currently offer five ways to access the data: API, bulk downloads, search, browse, and a historical trends viewer.
Our open-source API is the best option for anybody interested in programmatically accessing our metadata, full-text search, or individual cases.
If you need a large collection of cases, you will probably be best served by our bulk data downloads. Bulk downloads for Illinois and Arkansas are available without a login, and unlimited bulk files are available to research scholars.
Case metadata, such as the case name, citation, court, date, etc., is freely and openly accessible without limitation. Full case text can be freely viewed or downloaded but you must register for an account to do so, and currently you may view or download no more than 500 cases per day. In addition, research scholars can qualify for bulk data access by agreeing to certain use and redistribution restrictions. You can request a bulk access agreement by creating an account and then visiting your account page.
Access limitations on full text and bulk data are a component of Harvard’s collaboration agreement with Ravel Law, Inc. (now part of Lexis-Nexis). These limitations will end, at the latest, in March of 2024. In addition, these limitations apply only to cases from jurisdictions that continue to publish their official case law in print form. Once a jurisdiction transitions from print-first publishing to digital-first publishing, these limitations cease. Thus far, Illinois and Arkansas have made this important and positive shift and, as a result, all historical cases from these jurisdictions are freely available to the public without restriction. We hope many other jurisdictions will follow their example soon.
A different project altogether is helping the team behind Caselaw improve its data quality:
Our data inevitably includes countless errors as part of the digitization process. The public launch of this project is only the start of discovering errors, and we hope you will help us in finding and fixing them.
Some parts of our data are higher quality than others. Case metadata, such as the party names, docket number, citation, and date, has received human review. Case text and general head matter has been generated by machine OCR and has not received human review.
You can report errors of all kinds at our Github issue tracker, where you can also see currently known issues. We particularly welcome metadata corrections, feature requests, and suggestions for large-scale algorithmic changes. We are not currently able to process individual OCR corrections, but welcome general suggestions on the OCR correction process.
PyData is famous for it’s great talks on machine learning topics. This 2019 London edition, Vincent Warmerdamagain managed to give a super inspiring presentation. This year he covers what he dubs Artificial Stupidity™. You should definitely watch the talk, which includes some great visual aids, but here are my main takeaways:
Vincent speaks of Artificial Stupidity, of machine learning gone HorriblyWrong™ — an example of which below — for which Vincent elaborates on three potential fixes:
Example of a model that goes HorriblyWrong™, according to Vincent’s talk.
1. Predict Less, but Carefully
Vincent argues you shouldn’t extrapolate your predictions outside of your observed sampling space. Even better: “Not predicting given uncertainty is a great idea.” As an alternative, we could for instance design a fallback mechanism, by including an outlier detection model as the first step of your machine learning model pipeline and only predict for non-outliers.
I definately recommend you watch this specific section of Vincent’s talk because he gives some very visual and intuitive explanations of how extrapolation may go HorriblyWrong™.
Be careful! One thing we should maybe start talking about to our bosses: Algorithms merely automate, approximate, and interpolate. It’s the extrapolation that is actually kind of dangerous.
Vincent Warmerdam @ Pydata 2019 London
Basically, we can choose to not make automated decisions sometimes.
2. Constrain thy Features
What we feed to our models really matters. […] You should probably do something to the data going into your model if you want your model to have any sort of fairness garantuees.
Vincent Warmerdam @ Pydata 2019 London
Often, simply removing biased features from your data does not reduce bias to the extent we may have hoped. Fortunately, Vincent demonstrates how to remove biased information from your variables by applying some cool math tricks.
Unfortunately, doing so will often result in a lesser predictive accuracy. Unsurprisingly though, as you are not closely fitting the biased data any more. What makes matters more problematic, Vincent rightfully mentions, is that corporate incentives often not really align here. It might feel that you need to pick: it’s either more accuracy or it’s more fairness.
However, there’s a nice solution that builds on point 1. We can now take the highly accurate model and the highly fair model, make predictions with both, and when these predictions differ, that’s a very good proxy where you potentially don’t want to make a prediction. Hence, there may be observations/samples where we are comfortable in making a fair prediction, whereas in most other situations we may say “right, this prediction seems unfair, we need a fallback mechanism, a human being should look at this and we should not automate this decision”.
Vincent does not that this is only one trick to constrain your model for fairness, and that fairness may often only be fair in the eyes of the beholder. Moreover, in order to correct for these biases and unfairness, you need to know about these unfair biases. Although outside of the scope of this specific topic, Vincent proposes this introduces new ethical issues:
Basically, we can choose to put our models on a controlled diet.
3. Constrain thy Model
Vincent argues that we should include constraints (based on domain knowledge, or common sense) into our models. In his presentation, he names a few. For instance, monotonicity, which implies that the relationship between X and Y should always be either entirely non-increasing, or entirely non-decreasing. Incorporating the previously discussed fairness principles would be a second example, and there are many more.
If we every come up with a model where more smoking leads to better health, that’s bad. I have enough domain knowledge to say that that should never happen. So maybe I should just make a system where I can say “look this one column with relationship to Y should always be strictly negative”.
Vincent Warmerdam @ Pydata 2019 London
Basically, we can integrate domain knowledge or preferences into our models.
Voor Privacyweb schreef ik onlangs over people analytics en het mogelijk resulterende nudgen van medewerkers: kleine aanpassingen of duwtjes die mensen in de goede richting zouden moeten sturen. Medewerkers verleiden tot goed gedrag, als het ware. Maar wie bepaalt dan wat goed is, en wanneer zouden werkgevers wel of niet mogen of zelfs moeten nudgen?
Like any large tech company, Etsy relies heavily on statistics to improve their way of doing business. In their case, data from real-life experiments provide the business intelligence that allow effective decision-making. For instance, they experiment with the layout of their buttons, with the text shown near products, or with the suggestions made after a search query. To detect whether such changes have (ever so) small effects on Etsy’s KPI’s (e.g., conversion), data scientists such as Emily rely on traditional A/B testing.
In a 40-minute presentation, Emily explains how statistical issues such as skewed distributions, outliers, and power are dealt with at Etsy, among others using bootstrapping and simulations. Moreover, 30 minutes in Emily shares her lessons when it comes to working with (less stats-savvy) business stakeholders. For instance, how to help identify and transform business questions into data questions back into business solutions, or how to deal with the desire to peek at the results of experiments early.
Overall, I can the presentation below, the slides of which you find on Emily’s GitHub.
Yesterday, I read the most interesting article on how Uber uses academic research from the field of behavioral psychology to persuade their drivers to display desired behaviors. The tone of the article is quite negative and I most definitely agree there are several ethical issues at hand here. However, as a data scientist, I was fascinated by the way in which Uber has translated academic insights and statistical methodology into applications within their own organization that actually seem to pay off. Well, at least in the short term, as this does not seem a viable long-term strategy.
The full article is quite a long read (~20 min), and although I definitely recommend you read it yourself, here are my summary notes, for convenience quoted from the original article:
“Employing hundreds of social scientists and data scientists, Uber has experimented with video game techniques, graphics and noncash rewards of little value that can prod drivers into working longer and harder — and sometimes at hours and locations that are less lucrative for them.”
“To keep drivers on the road, the company has exploited some people’s tendency to set earnings goals — alerting them that they are ever so close to hitting a precious target when they try to log off.”
“Uber exists in a kind of legal and ethical purgatory […] because its drivers are independent contractors, they lack most of the protections associated with employment.”
“[…] much of Uber’s communication with drivers over the years has aimed at combating shortages by advising drivers to move to areas where they exist, or where they might arise. Uber encouraged its local managers to experiment with ways of achieving this.[…] Some local managers who were men went so far as to adopt a female persona for texting drivers, having found that the uptake was higher when they did.”
“[…] Uber was increasingly concerned that many new drivers were leaving the platform before completing the 25 rides that would earn them a signing bonus. To stem that tide, Uber officials in some cities began experimenting with simple encouragement: You’re almost halfway there, congratulations! While the experiment seemed warm and innocuous, it had in fact been exquisitely calibrated. The company’s data scientists had previously discovered that once drivers reached the 25-ride threshold, their rate of attrition fell sharply.”
“For months, when drivers tried to log out, the app would frequently tell them they were only a certain amount away from making a seemingly arbitrary sum for the day, or from matching their earnings from that point one week earlier.The messages were intended to exploit another relatively widespread behavioral tic — people’s preoccupation with goals — to nudge them into driving longer. […] Are you sure you want to go offline?” Below were two prompts: “Go offline” and “Keep driving.” The latter was already highlighted.”
“Sometimes the so-called gamification is quite literal. Like players on video game platforms such as Xbox, PlayStation and Pogo, Uber drivers can earn badges for achievements like Above and Beyond (denoted on the app by a cartoon of a rocket blasting off), Excellent Service (marked by a picture of a sparkling diamond) and Entertaining Drive (a pair of Groucho Marx glasses with nose and eyebrows).”
“More important, some of the psychological levers that Uber pulls to increase the supply of drivers have quite powerful effects. Consider an algorithm called forward dispatch […] that dispatches a new ride to a driver before the current one ends. Forward dispatch shortens waiting times for passengers, who may no longer have to wait for a driver 10 minutes away when a second driver is dropping off a passenger two minutes away. Perhaps no less important, forward dispatch causes drivers to stay on the road substantially longer during busy periods […]
[But] there is another way to think of the logic of forward dispatch: It overrides self-control. Perhaps the most prominent example is that such automatic queuing appears to have fostered the rise of binge-watching on Netflix. “When one program is nearing the end of its running time, Netflix will automatically cue up the next episode in that series for you,” wrote the scholars Matthew Pittman and Kim Sheehan in a 2015 study of the phenomenon. “It requires very little effort to binge on Netflix; in fact, it takes more effort to stop than to keep going.””
“Kevin Werbach, a business professor who has written extensively on the subject, said that while gamification could be a force for good in the gig economy — for example, by creating bonds among workers who do not share a physical space — there was a danger of abuse.”
“There is also the possibility that as the online gig economy matures, companies like Uber may adopt a set of norms that limit their ability to manipulate workers through cleverly designed apps. For example, the company has access to a variety of metrics, like braking and acceleration speed, that indicate whether someone is driving erratically and may need to rest. “The next step may be individualized targeting and nudging in the moment,” Ms. Peters said. “‘Hey, you just got three passengers in a row who said they felt unsafe. Go home.’” Uber has already rolled out efforts in this vein in numerous cities.”
“That moment of maturity does not appear to have arrived yet, however. Consider a prompt that Uber rolled out this year, inviting drivers to press a large box if they want the app to navigate them to an area where they have a “higher chance” of finding passengers. The accompanying graphic resembles the one that indicates that an area’s fares are “surging,” except in this case fares are not necessarily higher.”












 “[…] much of Uber’s communication with drivers over the years has aimed at combating shortages by advising drivers to move to areas where they exist, or where they might arise. Uber encouraged its local managers to experiment with ways of achieving this.[…] Some local managers who were men went so far as to adopt a female persona for texting drivers, having found that the uptake was higher when they did.”
“[…] much of Uber’s communication with drivers over the years has aimed at combating shortages by advising drivers to move to areas where they exist, or where they might arise. Uber encouraged its local managers to experiment with ways of achieving this.[…] Some local managers who were men went so far as to adopt a female persona for texting drivers, having found that the uptake was higher when they did.” “For months, when drivers tried to log out, the app would frequently tell them they were only a certain amount away from making a seemingly arbitrary sum for the day, or from matching their earnings from that point one week earlier.The messages were intended to exploit another relatively widespread behavioral tic — people’s preoccupation with goals — to nudge them into driving longer. […] Are you sure you want to go offline?” Below were two prompts: “Go offline” and “Keep driving.” The latter was already highlighted.”
“For months, when drivers tried to log out, the app would frequently tell them they were only a certain amount away from making a seemingly arbitrary sum for the day, or from matching their earnings from that point one week earlier.The messages were intended to exploit another relatively widespread behavioral tic — people’s preoccupation with goals — to nudge them into driving longer. […] Are you sure you want to go offline?” Below were two prompts: “Go offline” and “Keep driving.” The latter was already highlighted.”