Coding Train is a Youtube channel by Daniel Shiffman that covers anything from the basics of programming languages like JavaScript (with p5.js) and Java (with Processing) to generative algorithms like physics simulation, computer vision, and data visualization. In particular, these latter topics, which Shiffman bundles under the label “the Nature of Code”, draw me to the channel.
In a recent series, Daniel draws from his free e-book to create his seven-video playlist where he elaborates on the inner workings of neural networks, visualizing the entire process as he programs the algorithm from scratch in Processing (Java). I recommend the two videos below consisting of the actual programming, especially for beginners who want to get an intuitive sense of how a neural network works.
Artificial neural networks (ANNs) are computing systems inspired by the human brain. They can teach themselves to do tasks, simply by considering examples of the tasks’ outcome. For example, they can learn to identify images that contain cats by analyzing example images that have been tagged “cat” or “no cat”. When given enough examples, the neural network can autonomously determine whether “untagged” images include cats or not (Wikipedia). If you want to learn more and have 20 minutes to spare, I can recommend this YouTube video by Brandon Rohrer.
Neural networks are commonly used for those machine learning problems where there is a vast amount of (complex) data available. Some toy examples include fingerprint recognition, language translation, car steering behaviours, object detection, text generation, and doodle recognition (by Google). Chances are pretty high that any system that makes complex recommendations these days (e.g., “Is this John in the picture?”, “Did you mean “South End Taco’s” instead of “Sout En dTacos”?”) has a neural net running in the background.
http://www.r-exercises.com designs tutorials for beginning programmers in R. On their website they host a learning series on neural networks, consisting of three sets of exercises: Part 1, Part 2, and Part 3. Afterwards, you can check your performance with the solutions: Solutions 1, Solutions 2, and Solutions 3.
XGBOOST stands for eXtreme Gradient Boosting. A big brother of the earlier AdaBoost, XGB is a supervised learning algorithm that uses an ensemble of adaptively boosted decision trees. For those unfamiliar with adaptive boosting algorithms, here’s a 2-minute explanation video and a written tutorial. Although XGBOOST often performs well in predictive tasks, the training process can be quite time-consuming (similar to other bagging/boosting algorithms (e.g., random forest)).
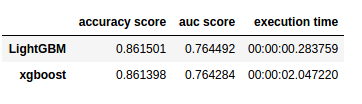
In a recent blog, Analytics Vidhya compares the inner workings as well as the predictive accuracy of the XGBOOST algorithm to an upcoming boosting algorithm: Light GBM. The blog demonstrates a stepwise implementation of both algorithms in Python. The table below reflects the main conclusion of the comparison: Although the algorithms are comparable in terms of their predictive performance, light GBM is much faster to train. With continuously increasing data volumes, light GBM, therefore, seems the way forward.
Laurae also benchmarked lightGBM against xgboost on a Bosch dataset and her results show that, on average, LightGBM (binning) is between 11x to 15x faster than xgboost (without binning):
However, the differences get smaller as more threads are used due to thread inefficiencies (idle-time increases because threads are not scheduled a next task fast enough).
Neil Schneider tested the three algorithms for gradient boosting in R (GBM, xgboost, and lightGBM) and sums up their (dis)advantages:
GBM has no specific advantages but its disadvantages include no early stopping, slower training and decreased accuracy,
xgboost has demonstrated successful on kaggle and though traditionally slower than lightGBM, tree_method = 'hist' (histogram binning) provides a significant improvement.
lightGBM has the advantages of training efficiency, low memory usage, high accuracy, parallel learning, corporate support, and scale-ability. However, its’ newness is its main disadvantage because there is little community support.
Yesterday, I read the most interesting article on how Uber uses academic research from the field of behavioral psychology to persuade their drivers to display desired behaviors. The tone of the article is quite negative and I most definitely agree there are several ethical issues at hand here. However, as a data scientist, I was fascinated by the way in which Uber has translated academic insights and statistical methodology into applications within their own organization that actually seem to pay off. Well, at least in the short term, as this does not seem a viable long-term strategy.
The full article is quite a long read (~20 min), and although I definitely recommend you read it yourself, here are my summary notes, for convenience quoted from the original article:
“Employing hundreds of social scientists and data scientists, Uber has experimented with video game techniques, graphics and noncash rewards of little value that can prod drivers into working longer and harder — and sometimes at hours and locations that are less lucrative for them.”
“To keep drivers on the road, the company has exploited some people’s tendency to set earnings goals — alerting them that they are ever so close to hitting a precious target when they try to log off.”
“Uber exists in a kind of legal and ethical purgatory […] because its drivers are independent contractors, they lack most of the protections associated with employment.”
“[…] much of Uber’s communication with drivers over the years has aimed at combating shortages by advising drivers to move to areas where they exist, or where they might arise. Uber encouraged its local managers to experiment with ways of achieving this.[…] Some local managers who were men went so far as to adopt a female persona for texting drivers, having found that the uptake was higher when they did.”
“[…] Uber was increasingly concerned that many new drivers were leaving the platform before completing the 25 rides that would earn them a signing bonus. To stem that tide, Uber officials in some cities began experimenting with simple encouragement: You’re almost halfway there, congratulations! While the experiment seemed warm and innocuous, it had in fact been exquisitely calibrated. The company’s data scientists had previously discovered that once drivers reached the 25-ride threshold, their rate of attrition fell sharply.”
“For months, when drivers tried to log out, the app would frequently tell them they were only a certain amount away from making a seemingly arbitrary sum for the day, or from matching their earnings from that point one week earlier.The messages were intended to exploit another relatively widespread behavioral tic — people’s preoccupation with goals — to nudge them into driving longer. […] Are you sure you want to go offline?” Below were two prompts: “Go offline” and “Keep driving.” The latter was already highlighted.”
“Sometimes the so-called gamification is quite literal. Like players on video game platforms such as Xbox, PlayStation and Pogo, Uber drivers can earn badges for achievements like Above and Beyond (denoted on the app by a cartoon of a rocket blasting off), Excellent Service (marked by a picture of a sparkling diamond) and Entertaining Drive (a pair of Groucho Marx glasses with nose and eyebrows).”
“More important, some of the psychological levers that Uber pulls to increase the supply of drivers have quite powerful effects. Consider an algorithm called forward dispatch […] that dispatches a new ride to a driver before the current one ends. Forward dispatch shortens waiting times for passengers, who may no longer have to wait for a driver 10 minutes away when a second driver is dropping off a passenger two minutes away. Perhaps no less important, forward dispatch causes drivers to stay on the road substantially longer during busy periods […]
[But] there is another way to think of the logic of forward dispatch: It overrides self-control. Perhaps the most prominent example is that such automatic queuing appears to have fostered the rise of binge-watching on Netflix. “When one program is nearing the end of its running time, Netflix will automatically cue up the next episode in that series for you,” wrote the scholars Matthew Pittman and Kim Sheehan in a 2015 study of the phenomenon. “It requires very little effort to binge on Netflix; in fact, it takes more effort to stop than to keep going.””
“Kevin Werbach, a business professor who has written extensively on the subject, said that while gamification could be a force for good in the gig economy — for example, by creating bonds among workers who do not share a physical space — there was a danger of abuse.”
“There is also the possibility that as the online gig economy matures, companies like Uber may adopt a set of norms that limit their ability to manipulate workers through cleverly designed apps. For example, the company has access to a variety of metrics, like braking and acceleration speed, that indicate whether someone is driving erratically and may need to rest. “The next step may be individualized targeting and nudging in the moment,” Ms. Peters said. “‘Hey, you just got three passengers in a row who said they felt unsafe. Go home.’” Uber has already rolled out efforts in this vein in numerous cities.”
“That moment of maturity does not appear to have arrived yet, however. Consider a prompt that Uber rolled out this year, inviting drivers to press a large box if they want the app to navigate them to an area where they have a “higher chance” of finding passengers. The accompanying graphic resembles the one that indicates that an area’s fares are “surging,” except in this case fares are not necessarily higher.”
Just as humans, computers learn by experience.The purpose of A/B testing is often to collect data to decide whether intervention A or B is better. As such, we provide one group with intervention A whereas another group receives intervention B. With the data of these two groups coming in, the computer can statistically estimate which intervention (A or B) is more effective. The more data the computer has, the more certain the estimate is. Here, a trade-off exists: we need to collect data on both interventions to be certain which is best. But we don’t want to conduct an inefficient intervention, say B, if we are quite sure already that intervention A is better.
In his post, Corné de Ruijt of Endouble writes about multi-armed bandit algorithms, which try to optimize this trade-off: “Multi-armed bandit algorithms try to overcome the high missed opportunity cost involved in learning, by exploiting and exploring at the same time. Therefore, these methods are in particular interesting when there is a high lost opportunity cost involved in the experiment, and when exploring and exploiting must be performed during a limited time interval.“
In the full article, you can read Corné’s comparison of this multi-armed bandit approach to the traditional A/B testing approach using a recruitment and selection example. For those of you who are interested in reading how anyone can apply this algorithm and others to optimize our own daily decisions, I highly recommend the book Algorithms to Live By: The Computer Science of Human Decisions available on Amazon or the Dutch bol.com.




 “[…] much of Uber’s communication with drivers over the years has aimed at combating shortages by advising drivers to move to areas where they exist, or where they might arise. Uber encouraged its local managers to experiment with ways of achieving this.[…] Some local managers who were men went so far as to adopt a female persona for texting drivers, having found that the uptake was higher when they did.”
“[…] much of Uber’s communication with drivers over the years has aimed at combating shortages by advising drivers to move to areas where they exist, or where they might arise. Uber encouraged its local managers to experiment with ways of achieving this.[…] Some local managers who were men went so far as to adopt a female persona for texting drivers, having found that the uptake was higher when they did.” “For months, when drivers tried to log out, the app would frequently tell them they were only a certain amount away from making a seemingly arbitrary sum for the day, or from matching their earnings from that point one week earlier.The messages were intended to exploit another relatively widespread behavioral tic — people’s preoccupation with goals — to nudge them into driving longer. […] Are you sure you want to go offline?” Below were two prompts: “Go offline” and “Keep driving.” The latter was already highlighted.”
“For months, when drivers tried to log out, the app would frequently tell them they were only a certain amount away from making a seemingly arbitrary sum for the day, or from matching their earnings from that point one week earlier.The messages were intended to exploit another relatively widespread behavioral tic — people’s preoccupation with goals — to nudge them into driving longer. […] Are you sure you want to go offline?” Below were two prompts: “Go offline” and “Keep driving.” The latter was already highlighted.”