
These days, I am often programming in multiple different languages for my projects. I will do some data generation and machine learning in Python. The data exploration and some quick visualizations I prefer to do in R. And if I’m feeling adventureous, I might add some Processing or JavaScript visualizations.
Obviously, I want to track and store the versions of my programs and the changes between them. I probably don’t have to tell you that git is the tool to do so.
Normally, you’d have a .gitignore file in your project folder, and all files that are not listed (or have patterns listed) in the .gitignore file are backed up online.
However, when you are working in multiple languages simulatenously, it can become a hassle to assure that only the relevant files for each language are committed to Github.
Each language will have their own “by-files”. R projects come with .Rdata, .Rproj, .Rhistory and so on, whereas Python projects generate pycaches and what not. These you don’t want to commit preferably.
Enter the stage, gitignore.io:

Here you simply enter the operating systems, IDEs, or Programming languages you are working with, and it will generate the appropriate .gitignore contents for you.
Let’s try it out
For my current project, I am working with Python and R in Visual Studio Code. So I enter:
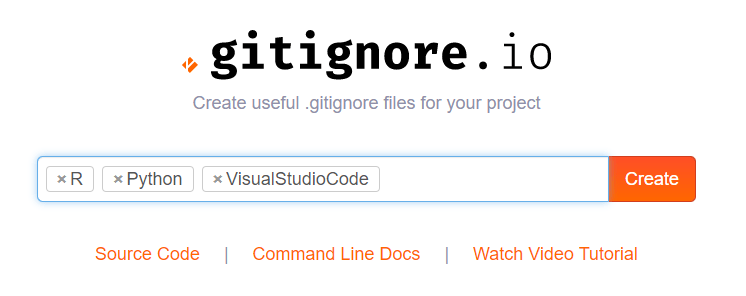
And Voila, I get the perfect .gitignore including all specifics for these programs and languages:
# Created by https://www.gitignore.io/api/r,python,visualstudiocode
# Edit at https://www.gitignore.io/?templates=r,python,visualstudiocode
### Python ###
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
pip-wheel-metadata/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# pyenv
.python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# Mr Developer
.mr.developer.cfg
.project
.pydevproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
### R ###
# History files
.Rhistory
.Rapp.history
# Session Data files
.RData
.RDataTmp
# User-specific files
.Ruserdata
# Example code in package build process
*-Ex.R
# Output files from R CMD build
/*.tar.gz
# Output files from R CMD check
/*.Rcheck/
# RStudio files
.Rproj.user/
# produced vignettes
vignettes/*.html
vignettes/*.pdf
# OAuth2 token, see https://github.com/hadley/httr/releases/tag/v0.3
.httr-oauth
# knitr and R markdown default cache directories
*_cache/
/cache/
# Temporary files created by R markdown
*.utf8.md
*.knit.md
### R.Bookdown Stack ###
# R package: bookdown caching files
/*_files/
### VisualStudioCode ###
.vscode/*
!.vscode/settings.json
!.vscode/tasks.json
!.vscode/launch.json
!.vscode/extensions.json
### VisualStudioCode Patch ###
# Ignore all local history of files
.history
# End of https://www.gitignore.io/api/r,python,visualstudiocodeTry it out yourself: http://gitignore.io/













 time to sort
time to sort  . Moreover, some algorithms are stable — in the sense that they always take the same amount of time to process
. Moreover, some algorithms are stable — in the sense that they always take the same amount of time to process 


