Tilburg University has set up a masterclass Predictive HR Analytics. In 3 days, the Professional Learning program will teach you all you need to know to implement predictive analytics and take HR to the next level. More information can be found here.
What makes this program unique?
The masterclass Predictive HR Analytics goes beyond HR analytics and focuses on transformational people predictions. You learn how to embed predictive HR analytics into your HR Strategy and how to use your findings to convince others.
The masterclass is developed at the prestigious Human Resources department at Tilburg University, which has obtained international recognition with its high-quality academic research in the HRM field.
The mix of professors in conjunction with leading HR professionals leads to a strong academic program with a practical approach.
Your peer participants will make sure that the class opens up a high-quality network of HR specialists. The diversity of leading companies from different sectors in the classroom creates new insights for all the participants.
The program is like a 3-day pressure cooker. By combining online and offline components, we can create more in-depth discussions in the classroom.
You will experience a high impact on your daily practice, since the program is focused on direct implementation.
Your profile
This course is ideal for anyone in HR seeking to become more adept in using quantitative data for decision making. Typical participants are (future) HR analysts, HR managers, HR business partners, HR consultants and (financial) business analysts with a strong link on people resources. Participants are from various sectors, such as financial services, healthcare institutions, government agencies and business services.
Things can get confusing quite quickly if you’re a layman. People boast about boosting while deep, brain-like networks are used to play child’s games. Data guru’s speak of mighty, though random woodlands and the media simultaneously praise and criticize IBM Watson. To create even more confusion, consultancy firms introduce a new type of analytics every year, each one more valuable than its predecessor. I am not even kidding, I counted seveneightnineten eleven types: descriptive, diagnostic, exploratory, inferential, strategic, causal, enterprise, advanced, predictive, prescriptive, adaptive, and cognitive analytics, roughly in that order of complexity.
The resulting confusion I experience firsthand in my work. In my workshops, people would ask questions like “How can I use data mining to make our dashboards to morepredictive?” or“How can I build neural networks to understand our customer needs?”. Similarly, I’ve heard managers ask for more “cognitive solutions” or “one of those fancy neural networks“. However, things can get pretty ugly, pretty soon, once unnecessary complexity is introduced without good reasons (e.g., superior performance, processing speed), appropriate foundations (e.g., accurate, valid, and sufficient data), or good research designs (e.g., control conditions, random assignment, out-of-sample validation).
It is high time to demystify the data domain. If people outside the direct domain know what’s what, they will better understand what can and can’t be done with data. Moreover, they will not be as easily fooled by the cognitive AI mumbojumbo of consultants. A recent blog made me very happy. David Robinson — data scientist at StackOverflow — proposes very simple definitions of three interrelated domains (data science, machine learning, and artificial intelligence) and highlights their differences. If you haven’t yet, do read it, but to summarize David’s take:
Data science produces insights
Machine learning produces predictions
Artificial intelligence produces actions
These definitions are overly simplistic, David acknowledges, and not without their flaws: “A fortune teller makes predictions, but we’d never say that they’re doing machine learning!”. However, I feel its a great first attempt at demystification. Particularly, the applied example with which David continues make matters more clear:
Suppose we were building a self-driving car, and were working on the specific problem of stopping at stop signs. We would need skills drawn from all three of these fields.
Machine learning: The car has to recognize a stop sign using its cameras. We construct a dataset of millions of photos of streetside objects, and train an algorithm to predict which have stop signs in them.
Artificial intelligence: Once our car can recognize stop signs, it needs to decide when to take the action of applying the brakes. It’s dangerous to apply them too early or too late, and we need it to handle varying road conditions (for example, to recognize on a slippery road that it’s not slowing down quickly enough), which is a problem of control theory.
Data science: In street tests, we find that the car’s performance isn’t good enough, with some false negatives in which it drives right by a stop sign. After analyzing the street test data, we gain the insight that the rate of false negatives depends on the time of day: it’s more likely to miss a stop sign before sunrise or after sunset. We realize that most of our training data included only objects in full daylight, so we construct a better dataset including nighttime images and go back to the machine learning step.
This got me thinking about how I would explain the field to a layman. In Human Resource Management (my PhD domain), there is enormous confusion around what’s what. When HR professionals speak of analytics they can mean about anything from a group average or a bar chart up to a deep neural network. I hoped that a simple diagram could help solve some of the confusion in terminology. Here’s my attempt:
A process diagram in order to demystify the fancy analytical terminology.
Note that this diagram reflects my personal, implicit definitions of the concepts. Hence, in many ways, it may be biased, incorrect, or plain stupid. Fortunately, the r/datascience and r/MachineLearning communities were very willing to help me improve it. I should also stress that David’s blog inspired the attempt in the first place. While the diagram still greatly oversimplifies matters (and is in conflict with the purist academic definitions), I hope its helps as a layman’s introduction to the field.
How to read it? From left to right, we start out with raw data. Often, we’d first transform this data into usable features/variables: discriminatory characteristics of the objects were trying to analyze. On the one hand, a researcher may engineer these features. For instance, by some (statistical) transformation such as taking the average X within groups or reducing the number of categories for Z. On the other hand, unsupervised machine learning techniques may be applied to (semi-)automatically engineer features by identifying relevant clusters or dimensions in the data.
Next, the features can be input into statistical analysis. Taking the upper path, both unsupervised and supervised machine learning techniques can be used to build models that can be interpreted to gain insights about phenomena. This process is what business people usually mean when they say “analytics“. Mostly, it involves descriptive, causal or inferential analyses in order to gain insights into some process or phenomenon. Taking the lower path, supervised learning may be applied build a predictive model and retrieve predictions for a dependent variable. These predictions may also be evaluated using further analysis to retrieve insights. For instance, to gain understanding about what’s driving the predictions or how the predictions may be leveraged in practice.
Finally, both predictions and insights may form the basis of actions, which can be taken by a human agent or by a computer agent. In the latter case, we would deal with AI by some definitions.
There is one more route in the diagram, going directly from the raw data to the predictions: deep learning. Here, a neural network may take in complex data (e.g., text, images, sound) and engineer relevant features autonomously to base predictions on.
Disclaimer: The diagram is a major oversimplification! Particularly the placement of and overlap between the domains in this diagram is a simplification and not very good by purist, academic standards. For instance, despite being a extremely important field of innovation, I excluded reinforcement learning as I was unable to place it without making the figure considerably more complex. Similarly, the others domains do not have as clear demarcations as this figure suggests and their placement is by my definition of them. Data science, in my opinion, reflects the diffusion of insights or knowledge from data, particularly the (human) decisions and actions made in that process. Much of data science relies on machine learning, which involves how algorithms learn a model of reality from data, observations, or experiences. This learning can occur in different forms (e.g., supervised, unsupervised, deep, and reinforcement learning) and, unlike David’s definition, thus not always output predictions (e.g., also dimensions, clusters). Finally, machine learning is a specific branch of artificial intelligence, a label that has had many definitions. In my eyes, it includes any (partially) automated process where seemingly intelligent actions are automatically executed based on decision rules. An action can be as simple as a single if-then statement or as complex as a smart fridge ordering new milk. Whether AI is or should be considered a part of data science is food for a different discussion. For much more straightforward definitions of the fields, please consult this slide shared by u/mmcmtl:
If you have any thoughts on how the above diagram and/or blog could or should be improved, feel free to comment below, reach out, or share your own attempts!
The first programs for (scientific) text mining are already over 50 years old. More recent efforts, such as the Linguistic Inquiry Word Count (LIWC; Tausczik & Pennebaker, 2010), have greatly improved our text analytical capabilities. Moreover, several single-purpose programs have been developed, which also consider syntactic text structures (e.g., Syntactic Complexity Analyzer [Lu, 2010], TAALES [Kyle & Crossley, 2015]).However, the widespread use of many of these programs has been hampered by two major barriers.
First, considerable technical expertise is required, which obstructs researchers without statistical backgrounds. For example, packages such as tm in R (Meyer et al., 2015) have been developed to conduct natural-language processing, but the steep learning curve forms a challenge. Additionally, the constant increase of computational processing power and the proliferation of new algorithms makes it difficult for researchers to maintain working knowledge of state-of-the-art methods.
Alternatively, most of the existing user-friendly NLP programs (and packages), such as RapidMiner (Akthar & Hahne, 2012), SAS Text Miner (Abell, 2014), or SPSS Modeler (IBM Corp., 2011), charge either a large software fee up front or a subscription fee. The cost of these programs can be prohibitively expensive for junior researchers and researchers looking to integrate new techniques into their research toolbox.
In the attached article, TACIT is introduced: Text Analysis, Crawling and Investigation Tool. TACIT is an open-source architecture that establishes a pipeline between the various stages of text-based research by integrating tools for text mining, data cleaning, and analysis under a single user-friendly architecture. In addition to being prepackaged with a range of easily applied, cutting-edge methods, TACIT’s design also allows other researchers to write their own plugins.
The authors’ hope is that TACIT can facilitate the integration and use of advancements in computational linguistics in psychological research, and by doing so can help researchers make use of the ever-growing documents of our social discourse in ways that have previously not been possible.
Yesterday, I read the most interesting article on how Uber uses academic research from the field of behavioral psychology to persuade their drivers to display desired behaviors. The tone of the article is quite negative and I most definitely agree there are several ethical issues at hand here. However, as a data scientist, I was fascinated by the way in which Uber has translated academic insights and statistical methodology into applications within their own organization that actually seem to pay off. Well, at least in the short term, as this does not seem a viable long-term strategy.
The full article is quite a long read (~20 min), and although I definitely recommend you read it yourself, here are my summary notes, for convenience quoted from the original article:
“Employing hundreds of social scientists and data scientists, Uber has experimented with video game techniques, graphics and noncash rewards of little value that can prod drivers into working longer and harder — and sometimes at hours and locations that are less lucrative for them.”
“To keep drivers on the road, the company has exploited some people’s tendency to set earnings goals — alerting them that they are ever so close to hitting a precious target when they try to log off.”
“Uber exists in a kind of legal and ethical purgatory […] because its drivers are independent contractors, they lack most of the protections associated with employment.”
“[…] much of Uber’s communication with drivers over the years has aimed at combating shortages by advising drivers to move to areas where they exist, or where they might arise. Uber encouraged its local managers to experiment with ways of achieving this.[…] Some local managers who were men went so far as to adopt a female persona for texting drivers, having found that the uptake was higher when they did.”
“[…] Uber was increasingly concerned that many new drivers were leaving the platform before completing the 25 rides that would earn them a signing bonus. To stem that tide, Uber officials in some cities began experimenting with simple encouragement: You’re almost halfway there, congratulations! While the experiment seemed warm and innocuous, it had in fact been exquisitely calibrated. The company’s data scientists had previously discovered that once drivers reached the 25-ride threshold, their rate of attrition fell sharply.”
“For months, when drivers tried to log out, the app would frequently tell them they were only a certain amount away from making a seemingly arbitrary sum for the day, or from matching their earnings from that point one week earlier.The messages were intended to exploit another relatively widespread behavioral tic — people’s preoccupation with goals — to nudge them into driving longer. […] Are you sure you want to go offline?” Below were two prompts: “Go offline” and “Keep driving.” The latter was already highlighted.”
“Sometimes the so-called gamification is quite literal. Like players on video game platforms such as Xbox, PlayStation and Pogo, Uber drivers can earn badges for achievements like Above and Beyond (denoted on the app by a cartoon of a rocket blasting off), Excellent Service (marked by a picture of a sparkling diamond) and Entertaining Drive (a pair of Groucho Marx glasses with nose and eyebrows).”
“More important, some of the psychological levers that Uber pulls to increase the supply of drivers have quite powerful effects. Consider an algorithm called forward dispatch […] that dispatches a new ride to a driver before the current one ends. Forward dispatch shortens waiting times for passengers, who may no longer have to wait for a driver 10 minutes away when a second driver is dropping off a passenger two minutes away. Perhaps no less important, forward dispatch causes drivers to stay on the road substantially longer during busy periods […]
[But] there is another way to think of the logic of forward dispatch: It overrides self-control. Perhaps the most prominent example is that such automatic queuing appears to have fostered the rise of binge-watching on Netflix. “When one program is nearing the end of its running time, Netflix will automatically cue up the next episode in that series for you,” wrote the scholars Matthew Pittman and Kim Sheehan in a 2015 study of the phenomenon. “It requires very little effort to binge on Netflix; in fact, it takes more effort to stop than to keep going.””
“Kevin Werbach, a business professor who has written extensively on the subject, said that while gamification could be a force for good in the gig economy — for example, by creating bonds among workers who do not share a physical space — there was a danger of abuse.”
“There is also the possibility that as the online gig economy matures, companies like Uber may adopt a set of norms that limit their ability to manipulate workers through cleverly designed apps. For example, the company has access to a variety of metrics, like braking and acceleration speed, that indicate whether someone is driving erratically and may need to rest. “The next step may be individualized targeting and nudging in the moment,” Ms. Peters said. “‘Hey, you just got three passengers in a row who said they felt unsafe. Go home.’” Uber has already rolled out efforts in this vein in numerous cities.”
“That moment of maturity does not appear to have arrived yet, however. Consider a prompt that Uber rolled out this year, inviting drivers to press a large box if they want the app to navigate them to an area where they have a “higher chance” of finding passengers. The accompanying graphic resembles the one that indicates that an area’s fares are “surging,” except in this case fares are not necessarily higher.”
Robert Coombs wanted to see whether he could land a new job. He was aware that, these days, organizations often employ applicant tracking systems to progress/fail incoming applications. Hence, Robert concluded that he had two challenges in his search for a new job:
He was up against leaders in their field, so his resume wouldn’t simply jump to the top of the pile.
Robots would read his application, along with those of his competition.
Being a tech enthusiast and having some programming skills, he decided to build his own application robot, capable of sending a customized CV and resume to the thousands of jobs posted online every day, in a matter of seconds. I strongly recommend you read his full story here, but these were his conclusions:
It’s not how you apply, it’s who you know. And if you don’t know someone, don’t bother.
Companies are trying to fill a position with minimal risk, not discover someone who breaks the mold.
The number of jobs you apply to has no correlation to whether you’ll be considered, and you won’t be considered for jobs you don’t get the chance to apply to.
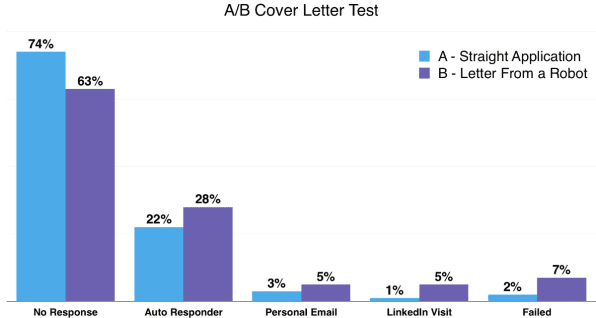
What I found most amusing is that he A/B tested one normal-looking cover letter and a letter in which he that admits right in the second sentence that it was being sent by a robot. “Now, one of those letters should have performed either a lot better or a lot worse than the other. For my purposes, I didn’t care which” he states. But as far as he could tell from the results of this experiment, it seems that nobody even reads cover letters anymore – not even the robots supposedly used in application tracking systems.
Just as humans, computers learn by experience.The purpose of A/B testing is often to collect data to decide whether intervention A or B is better. As such, we provide one group with intervention A whereas another group receives intervention B. With the data of these two groups coming in, the computer can statistically estimate which intervention (A or B) is more effective. The more data the computer has, the more certain the estimate is. Here, a trade-off exists: we need to collect data on both interventions to be certain which is best. But we don’t want to conduct an inefficient intervention, say B, if we are quite sure already that intervention A is better.
In his post, Corné de Ruijt of Endouble writes about multi-armed bandit algorithms, which try to optimize this trade-off: “Multi-armed bandit algorithms try to overcome the high missed opportunity cost involved in learning, by exploiting and exploring at the same time. Therefore, these methods are in particular interesting when there is a high lost opportunity cost involved in the experiment, and when exploring and exploiting must be performed during a limited time interval.“
In the full article, you can read Corné’s comparison of this multi-armed bandit approach to the traditional A/B testing approach using a recruitment and selection example. For those of you who are interested in reading how anyone can apply this algorithm and others to optimize our own daily decisions, I highly recommend the book Algorithms to Live By: The Computer Science of Human Decisions available on Amazon or the Dutch bol.com.






 “[…] much of Uber’s communication with drivers over the years has aimed at combating shortages by advising drivers to move to areas where they exist, or where they might arise. Uber encouraged its local managers to experiment with ways of achieving this.[…] Some local managers who were men went so far as to adopt a female persona for texting drivers, having found that the uptake was higher when they did.”
“[…] much of Uber’s communication with drivers over the years has aimed at combating shortages by advising drivers to move to areas where they exist, or where they might arise. Uber encouraged its local managers to experiment with ways of achieving this.[…] Some local managers who were men went so far as to adopt a female persona for texting drivers, having found that the uptake was higher when they did.” “For months, when drivers tried to log out, the app would frequently tell them they were only a certain amount away from making a seemingly arbitrary sum for the day, or from matching their earnings from that point one week earlier.The messages were intended to exploit another relatively widespread behavioral tic — people’s preoccupation with goals — to nudge them into driving longer. […] Are you sure you want to go offline?” Below were two prompts: “Go offline” and “Keep driving.” The latter was already highlighted.”
“For months, when drivers tried to log out, the app would frequently tell them they were only a certain amount away from making a seemingly arbitrary sum for the day, or from matching their earnings from that point one week earlier.The messages were intended to exploit another relatively widespread behavioral tic — people’s preoccupation with goals — to nudge them into driving longer. […] Are you sure you want to go offline?” Below were two prompts: “Go offline” and “Keep driving.” The latter was already highlighted.”