After several years of proscrastinating, the inevitable finally happened: Three months ago, I committed to learning Python!
I must say that getting started was not easy. One afternoon three months ago, I sat down, motivated to get started. Obviously, the first step was to download and install Python as well as something to write actual Python code. Coming from R, I had expected to be coding in a handy IDE within an hour or so. Oh boy, what was I wrong.
Apparently, there were already a couple of versions of Python present on my computer. And apparently, they were in grave conflict. I had one for the R reticulate package; one had come with Anaconda; another one from messing around with Tensorflow; and some more even. I was getting all kinds of error, warning, and conflict messages already, only 10 minutes in. Nothing I couldn’t handle in the end, but my good spirits had dropped slightly.
With Python installed, the obvious next step was to find the RStudio among the Python IDE’s and get working in that new environment. As an rational consumer, I went online to read about what people recommend as a good IDE. PyCharm seemed to be quite fancy for Data Science. However, what’s this Spyder alternative other people keep talking about? Come again, there are also Rodeo, Thonny, PyDev, and Wing? What about those then? A whole other group of Pythonista’s said that, as I work in Data Science, I should get Anaconda and work solely in Jupyter Notebooks! Okay…? But I want to learn Python to broaden my skills and do more regular software development as well. Maybe I start simple, in a (code) editor? However, here we have Atom, Sublime Text, Vim, and Eclipse? All these decisions. And I personally really dislike making regrettable decisions or committing to something suboptimal. This was already taking much, much longer than the few hours I had planned for setup.
This whole process demotivated so much that I reverted back to programming in R and RStudio the week after. However, I had not given up. Over the course of the week, I brought the selection back to Anaconda Jupyter Notebooks, PyCharm, and Atom, and I was ready to pick one. But wait… What’s this Visual Studio Code (VSC) thing by Microsoft. This looks fancy. And it’s still being developed and expanded. I had already been working in Visual Studio learning C++, and my experiences had been good so far. Moreover, Microsoft seems a reliable software development company, they must be able to build a good IDE? I decided to do one last deepdive.
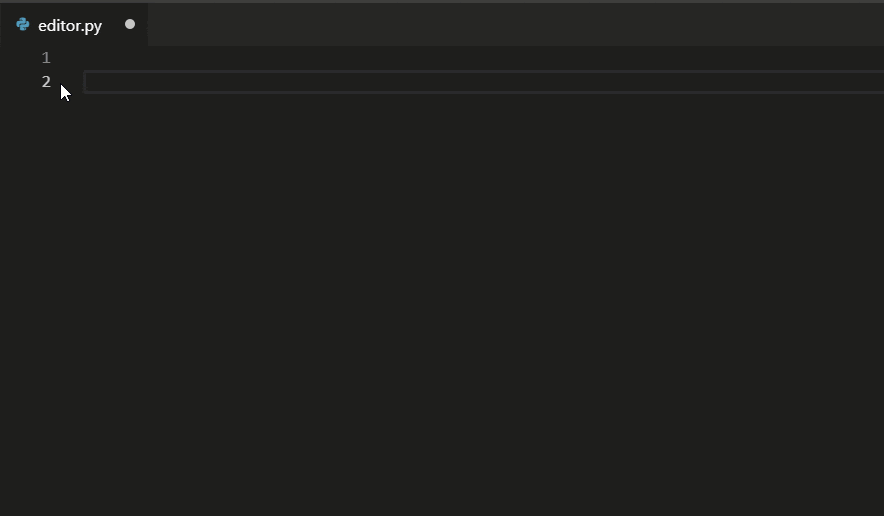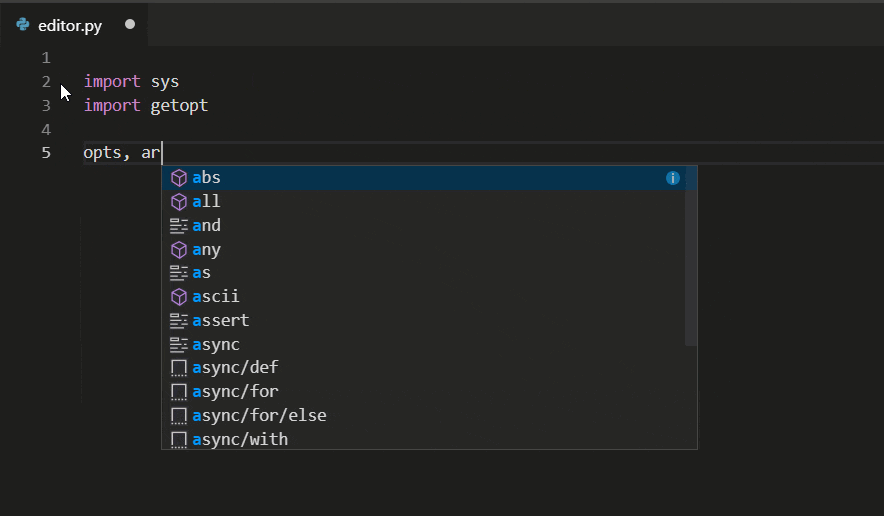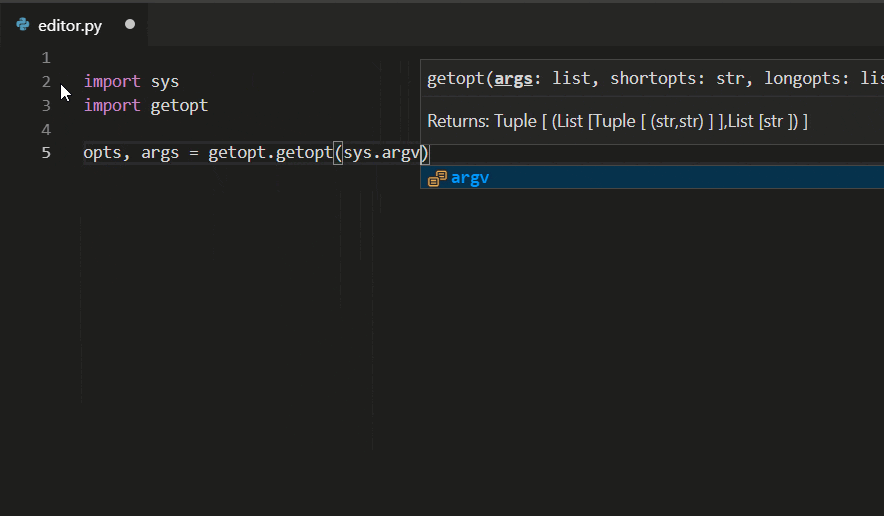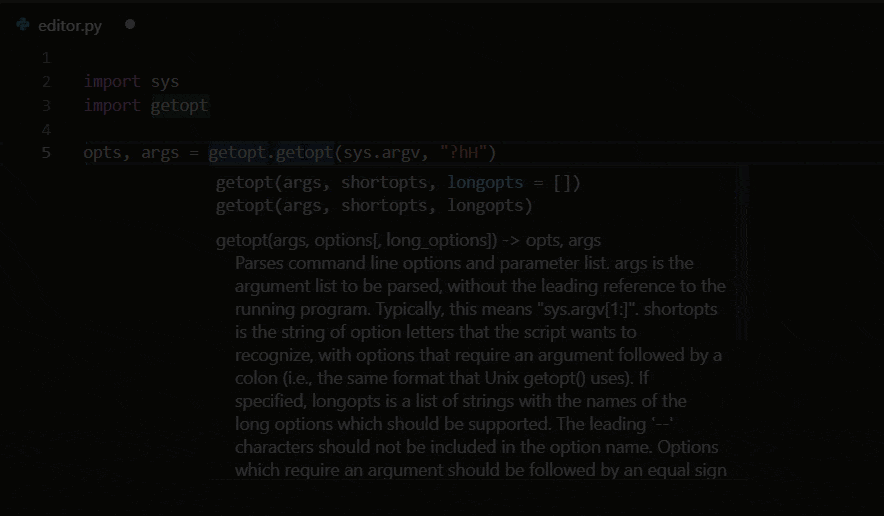
The more I read about VSC and its features for Python, the more excited I got. Hey, VSC’s Python extension automatically detects Python interpreters, so it solves my conflicts-problem. Linting you say? Never heard of it, but I’ll have it. Okay, able to run notebooks, nice! Easy debugging, testing, and handy snippets… Okay! Machine learning-based IntelliSense autocompletes your Python code – that sounds like something I’d like. A shit-ton of extensions? Yes please! Multi-language support – even tools for R programming? Say no more! I’ll take it. I’ll take it all!
Linting in VSC provides code suggestions
My goods friends at Microsoft were not done yet though. To top it all of, they have documented everything so well. It’s super easy to get started! There are numerous ordered pages dedicated to helping you set up and discover your new Python environment in VSC:
The Microsoft VSC pages also link to some more specific resources:
Editing Python in VS Code: Learn more about how to take advantage of VS Code’s autocomplete and IntelliSense support for Python, including how to customize their behvior… or just turn them off.
Linting Python: Linting is the process of running a program that will analyse code for potential errors. Learn about the different forms of linting support VS Code provides for Python and how to set it up.
Debugging Python: Debugging is the process of identifying and removing errors from a computer program. This article covers how to initialize and configure debugging for Python with VS Code, how to set and validate breakpoints, attach a local script, perform debugging for different app types or on a remote computer, and some basic troubleshooting.
Unit testing Python: Covers some background explaining what unit testing means, an example walkthrough, enabling a test framework, creating and running your tests, debugging tests, and test configuration settings.
Python IntelliSense in VSC makes real-time code autocomplete suggestions
My Own Python Journey
So three months in I am completely blown away at how easy, fun, and versatile the language is. Nearly anything is possible, most of the language is intuitive and straightforward, and there’s a package for anything you can think of. Although I have spent many hours, I am very happy with the results. I did not get this far, this quickly, in any other language. Let me share some of the stuff I’ve done the past three months.
I’ve mainly been building stuff. Some things from scratch, others by tweaking and recycling other people’s code. In my opinion, reusing other people’s code is not necessarily bad, as long as you understand what the code does. Moreover, I’ve combed through lists and lists of build-it-yourself projects to get inspiration for projects and used stuff from my daily work and personal life as further reasons to code. I ended up building:
solutions to the first 31 problems of Project Euler, which I highly recommend you try to solve yourself!
solutions to the first dozen problems posed in Automate the Boring Stuff with Python. This book and online tutorial forces you to get your hands dirty right from the start. Simply amazing content and the learning curve is precisely good
"Programming today is a race between software engineers striving to build bigger and better idiot-proof programs, and the universe trying to build bigger and better idiots. So far, the universe is winning." – Rick Cook#programming#coding#ArtificialStupidity no.20 pic.twitter.com/cBiR1HQszn
all Socratica Python Youtube videos. They are simply a fantastic introduction to the language and amazingly amusing. You can sponsor them here
hours and hours of Corey Shafer’s Youtube channel. Seriously good quality content, and more in-depth than Socratica. Corey covers the versatile functionalities included in the standard Python libraries and then some more
Although it is no longer maintained, you might find some more, interesting links on my Python resources page or here, for those transitioning from R. If only the links to the more up-to-date resources pages. Anyway, hope this current blog helps you on your Python journey or to get Python and Visual Studio Code working on your computer. Please feel free to share any of the stories, struggles, or successes you experience!
Last May, Tony Beltramelli of Ulzard Technologies presented his latest algorithm pix2code at the NIPS conference. Put simply, the algorithm looks at a picture of a graphical user interface (i.e., the layout of an app), and determines via an iterative process what the underlying code likely looks like.
Obviously, this is groundbreaking technology. When further developed, pix2code not only increases the speed with which society is automated/robotized but it also further expands the automation to more complex and highly needed tasks, such as programming and web/app development.
The first programs for (scientific) text mining are already over 50 years old. More recent efforts, such as the Linguistic Inquiry Word Count (LIWC; Tausczik & Pennebaker, 2010), have greatly improved our text analytical capabilities. Moreover, several single-purpose programs have been developed, which also consider syntactic text structures (e.g., Syntactic Complexity Analyzer [Lu, 2010], TAALES [Kyle & Crossley, 2015]).However, the widespread use of many of these programs has been hampered by two major barriers.
First, considerable technical expertise is required, which obstructs researchers without statistical backgrounds. For example, packages such as tm in R (Meyer et al., 2015) have been developed to conduct natural-language processing, but the steep learning curve forms a challenge. Additionally, the constant increase of computational processing power and the proliferation of new algorithms makes it difficult for researchers to maintain working knowledge of state-of-the-art methods.
Alternatively, most of the existing user-friendly NLP programs (and packages), such as RapidMiner (Akthar & Hahne, 2012), SAS Text Miner (Abell, 2014), or SPSS Modeler (IBM Corp., 2011), charge either a large software fee up front or a subscription fee. The cost of these programs can be prohibitively expensive for junior researchers and researchers looking to integrate new techniques into their research toolbox.
In the attached article, TACIT is introduced: Text Analysis, Crawling and Investigation Tool. TACIT is an open-source architecture that establishes a pipeline between the various stages of text-based research by integrating tools for text mining, data cleaning, and analysis under a single user-friendly architecture. In addition to being prepackaged with a range of easily applied, cutting-edge methods, TACIT’s design also allows other researchers to write their own plugins.
The authors’ hope is that TACIT can facilitate the integration and use of advancements in computational linguistics in psychological research, and by doing so can help researchers make use of the ever-growing documents of our social discourse in ways that have previously not been possible.