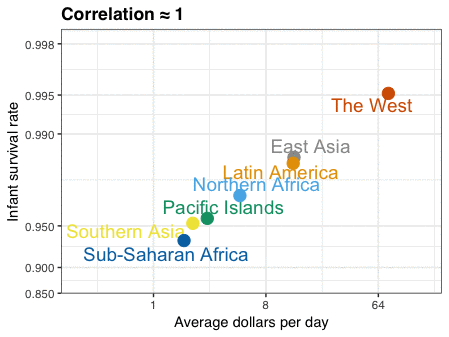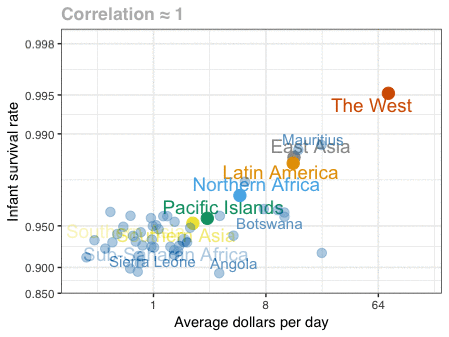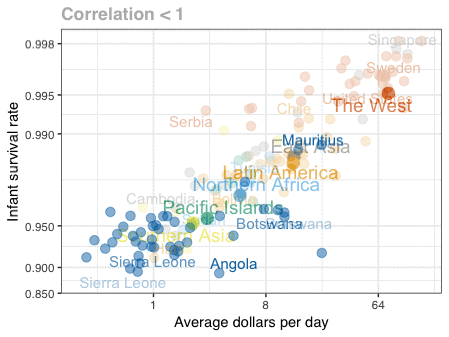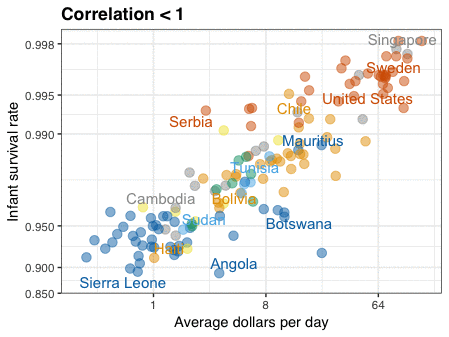
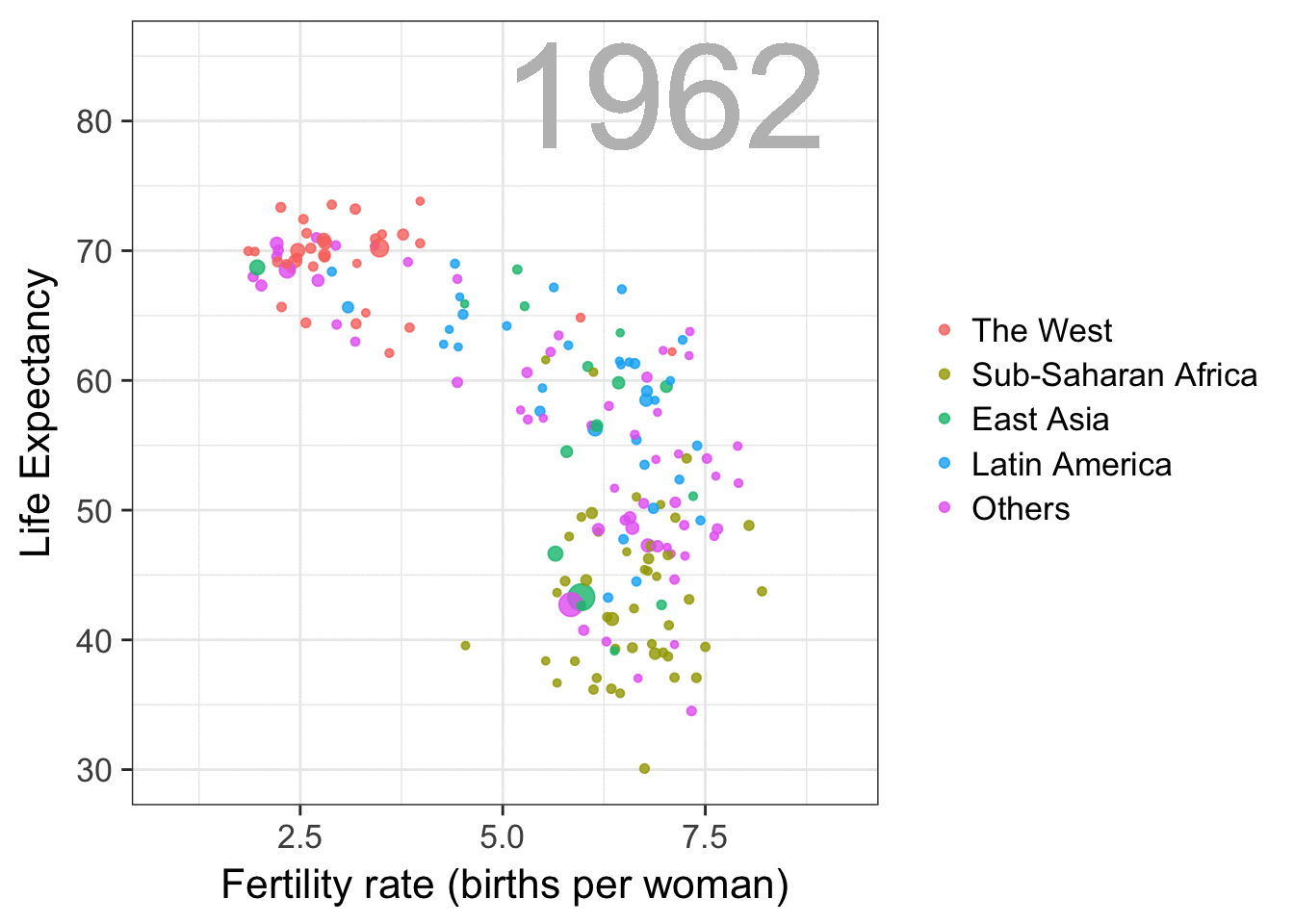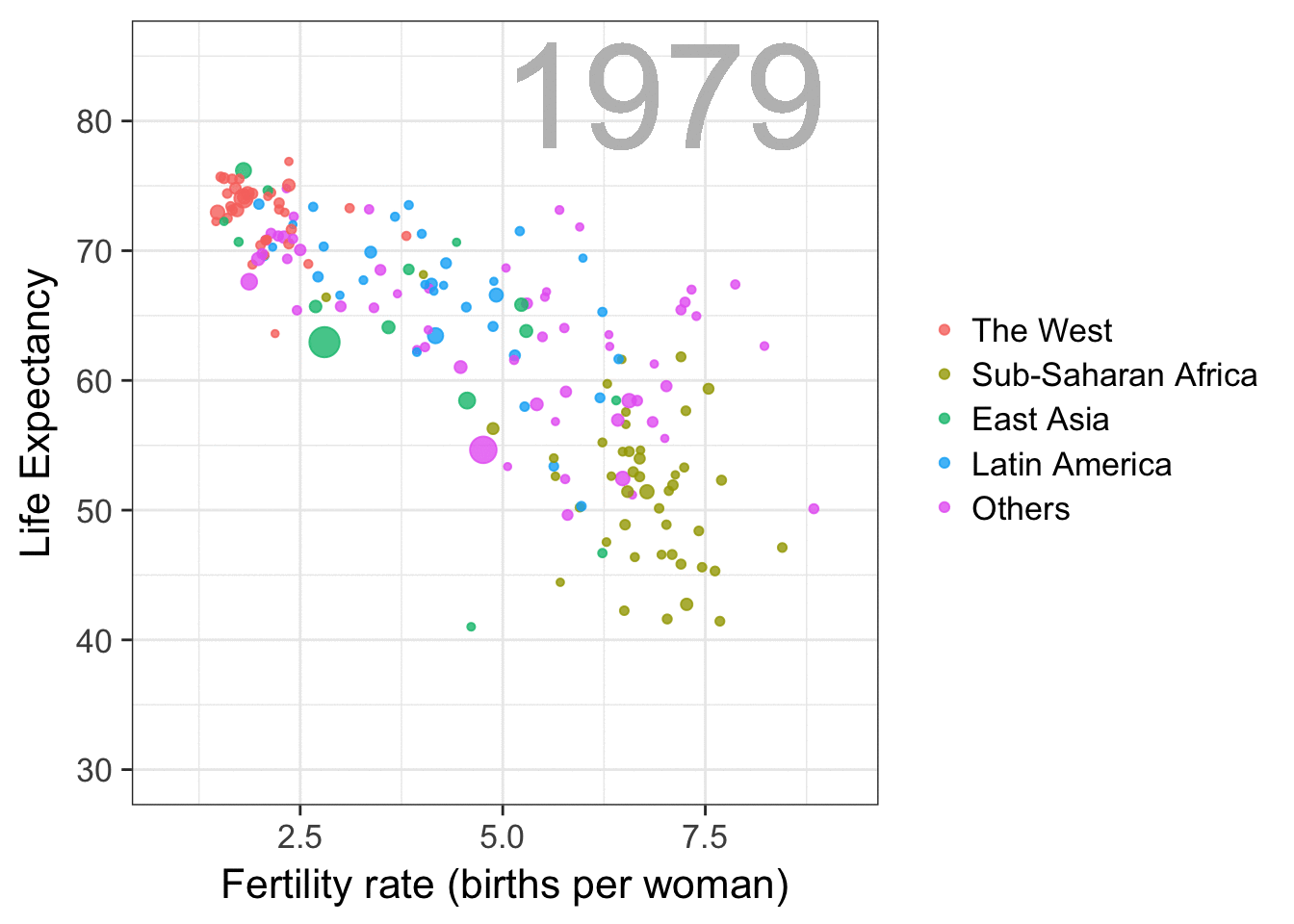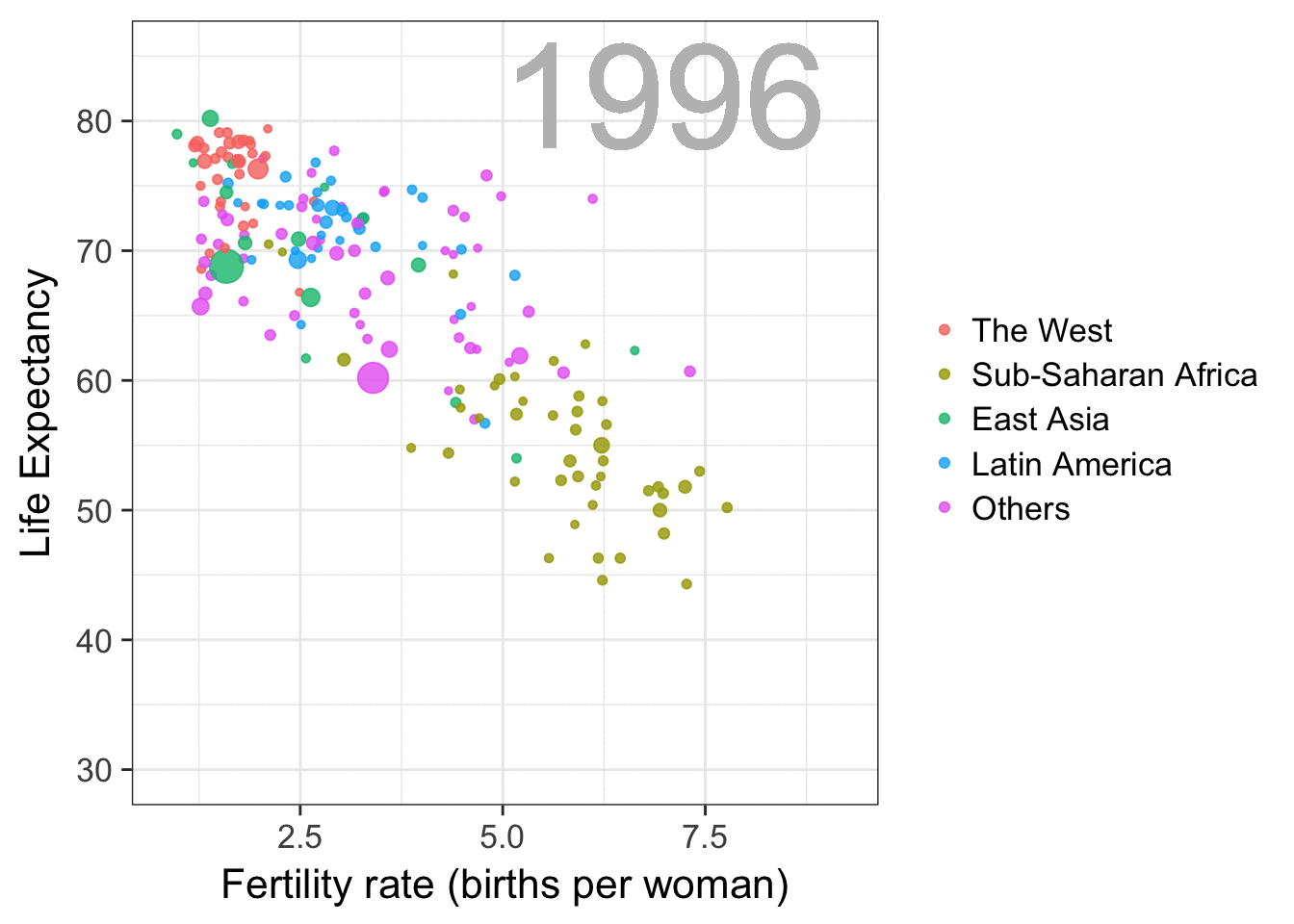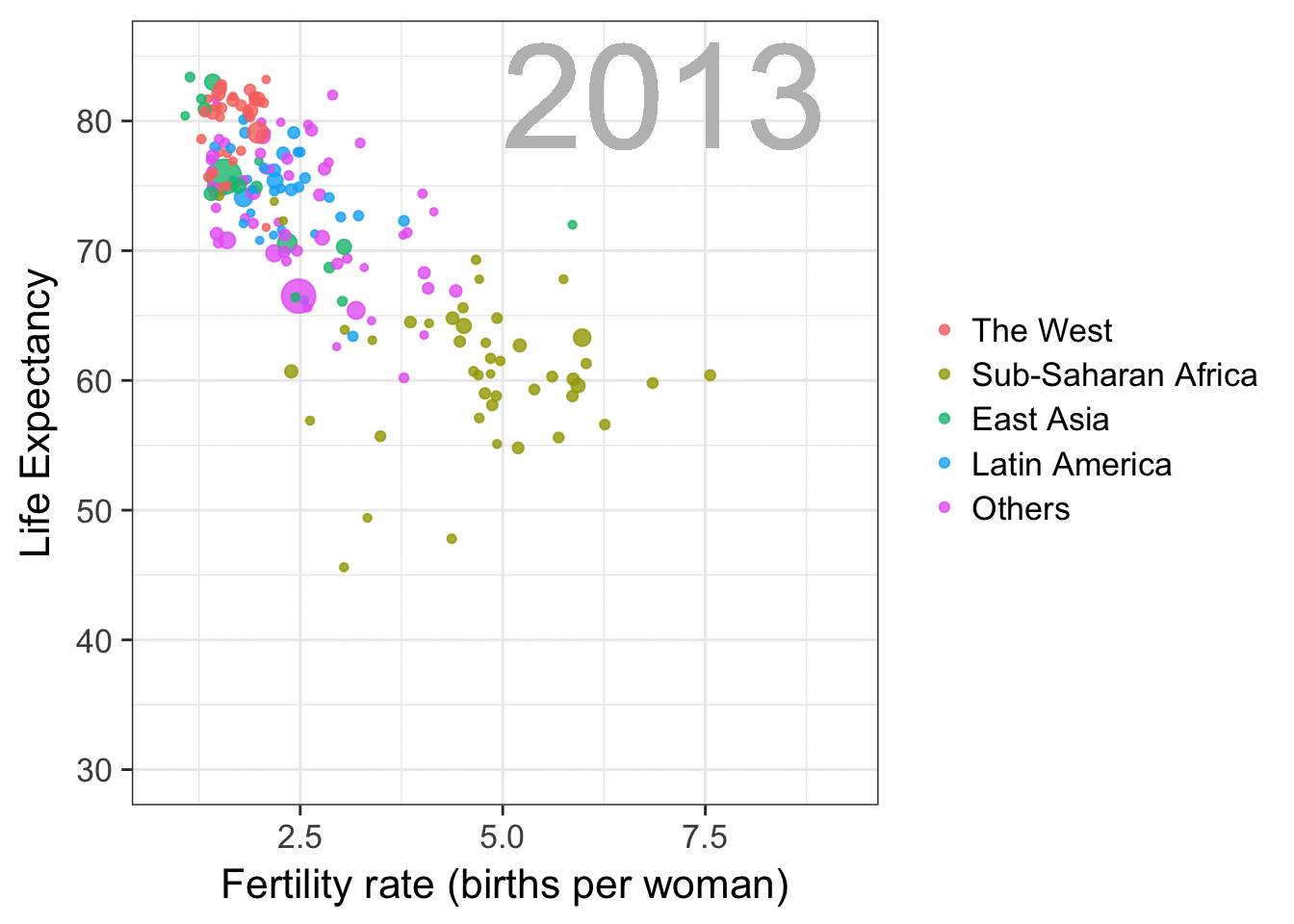
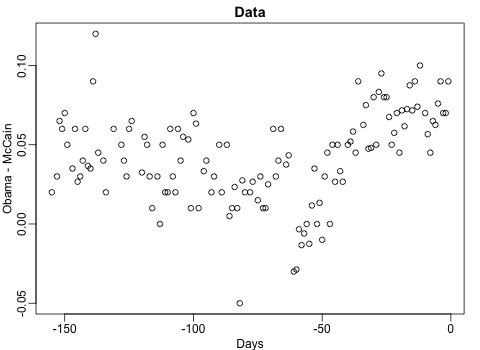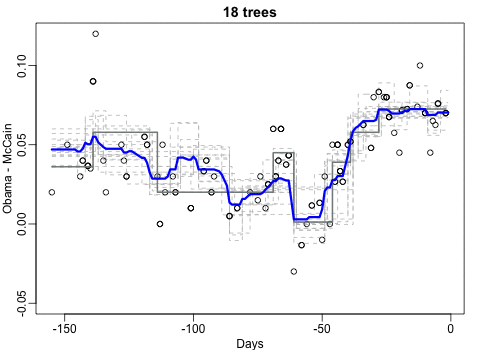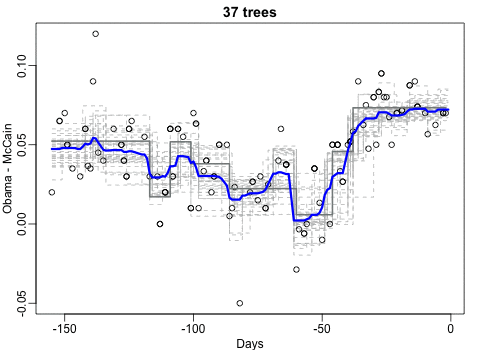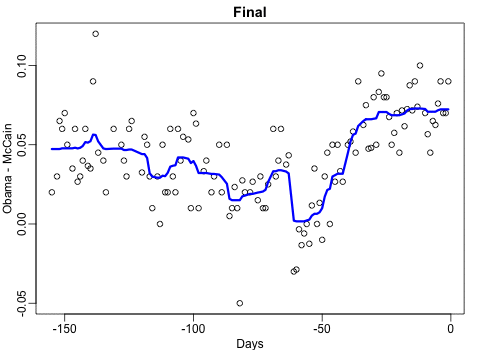
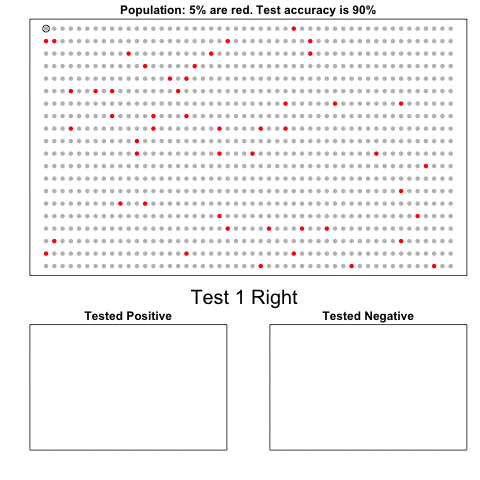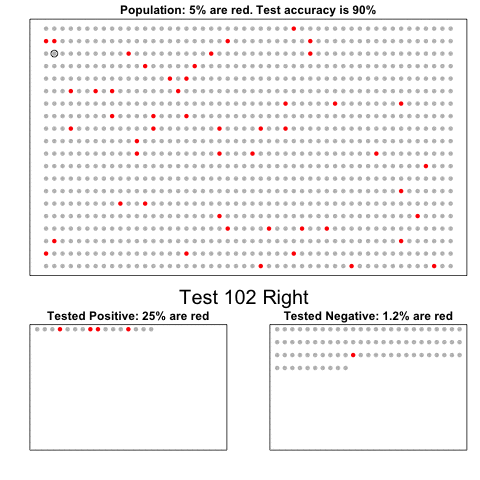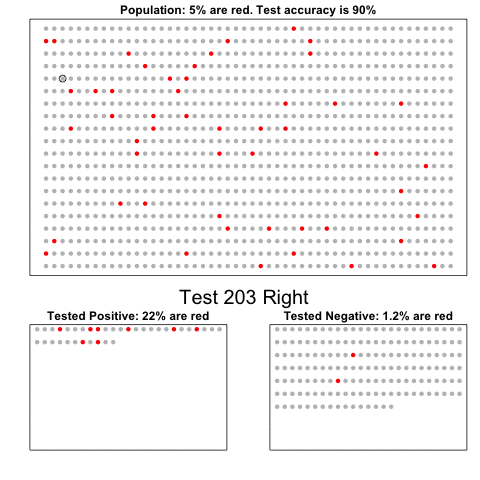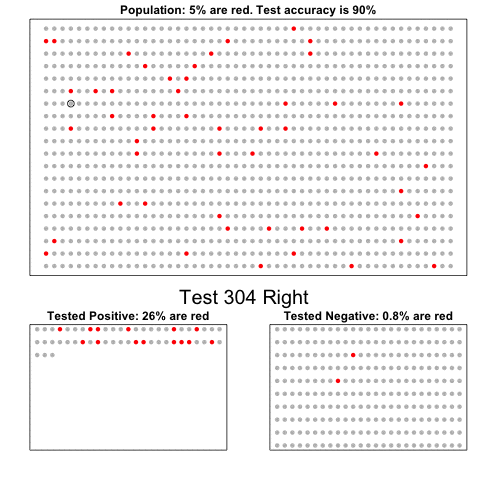
Professor John Kruschke and Torrin Liddell – one of his Ph.D. students at Indiana University – wrote a fantastically useful scientific paper introducing Bayesian data analysis to the masses. Kruschke and Liddell explain the main ideas behind Bayesian statistics, how Bayesians deal with continuous and binary variables, how to use and set meaningful priors, the differences between confidence and credibility intervals, how to perform model comparison tests, and many more. The paper is published open access so you can read it here.
I found it incredibly useful, providing me with a better understanding of how Bayesian analysis works, what kind of questions you can answer with it, and what the resulting insights would comprise of. After reading it, I was honestly asking myself why I don’t use Bayesian methods more often… So what’s next, how to learn more?
- If you are equally convinced and want to really learn Bayesian statistics, you might want to have a look at Kruschke’s book Doing Bayesian Data Analysis: A tutorial with R, JAGS, and Stan.
- If you’re up for the challenge, Kruschke and Liddel also published a more technical paper on Bayesian New Statistics at the same time as this introductory paper, also open-source.
- You can also start doing some simple analysis:
- In R, the
BayesFactorpackage andbrmswill get you started (suggested by u/data_for_everyone). - In Python,
pystanandpymc3are helpful (suggested by u/joefromlondon).
- In R, the
- If you prefer a more visual explanation of the fundamentals of Bayesian statistics, have a look at this YouTube video by Veritasium.