I’m not necessarily good at it, but most days I get to solve the puzzle.
The experience is completely different with Semantle — a Wordle-inspired puzzle in which you also need to guess the word of the day.
Unlike in Wordle, Semantle gives you unlimited guesses though. And, boy, you will need many!
Like Wordle, Semantle gives you hints as to how close your guesses were to the secret word of the day.
However, where Wordle shows you how good your guesses were in terms of the letters used, Semantle evaluates the semantic similarity of your guesses to the secret word. For the 1000 most similar words to the secret word, it will show you its closeness like in the picture above.
This semantic similarity comes from the domain of Natural Language Processing — NLP — and this basically reflects how often words are used in similar contexts in natural language.
For instance, the words “love” and “hate” may seem like opposites, but they will often score similarly in grammatical sentences. According to the semantle FAQ the actual opposite of “love” is probably something like “Arizona Diamondbacks”, or “carburetor”.
Another example is last day’s solution (15 March 2022), when the secret word was circle. The ten closest words you could have guessed include circles and semicircle, but more distinctive words such as corner and clockwise.
Further downfield you could have guessed relatively close words like saucer, dot, parabola, but I would not have expected words like outwaited, weaved, and zipped.
The creator of Semantle scored the semantic similarity for almost all words used in the English language, by training a so-called word2vec model based on a very large dataset of news articles (GoogleNews-vectors-negative300.bin from late 2021).
Now, every day, one word is randomly selected as the secret word, and you can try to guess which one it is. I usually give up after 300 to 400 guesses, but my record was 76 guesses for uncovering the secret word world.
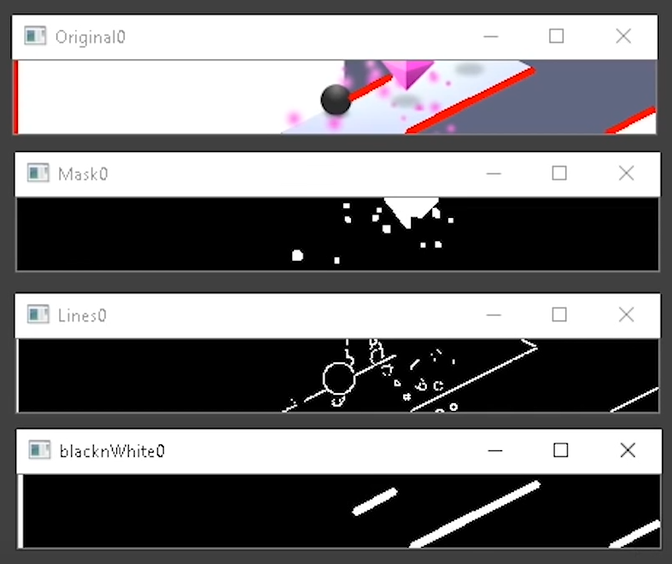
OpenCV is open-source library with tools and functionalities that support computer vision. It allows your computer to use complex mathematics to detect lines, shapes, colors, text and what not.
OpenCV was originally developed by Intel in 2000 and sometime later someone had the bright idea to build a Python module on top of it.
Using a simple…
pip install opencv-python
…you can now use OpenCV in Python to build advanced computer vision programs.
And this is exactly what many professional and hobby programmers are doing. Specifically, to get their computer to play (and win) mobile app games.
ZigZag
In ZigZag, you are a ball speeding down a narrow pathway and your only mission is to avoid falling off.
Using OpenCV, you can get your computer to detect objects, shapes, and lines.
This guy set up an emulator on his computer, so the computer can pretend to be a mobile device. Then he build a program using Python’s OpenCV module to get a top score
You can find the associated code here, but note that will need to set up an emulator yourself before being able to run this code.
Kick Ya Chop
In Kick Ya Chop, you need to stomp away parts of a tree as fast as you can, without hitting any of the branches.
This guy uses OpenCV to perform image pattern matching to allow his computer to identify and avoid the trees braches. Find the code here.
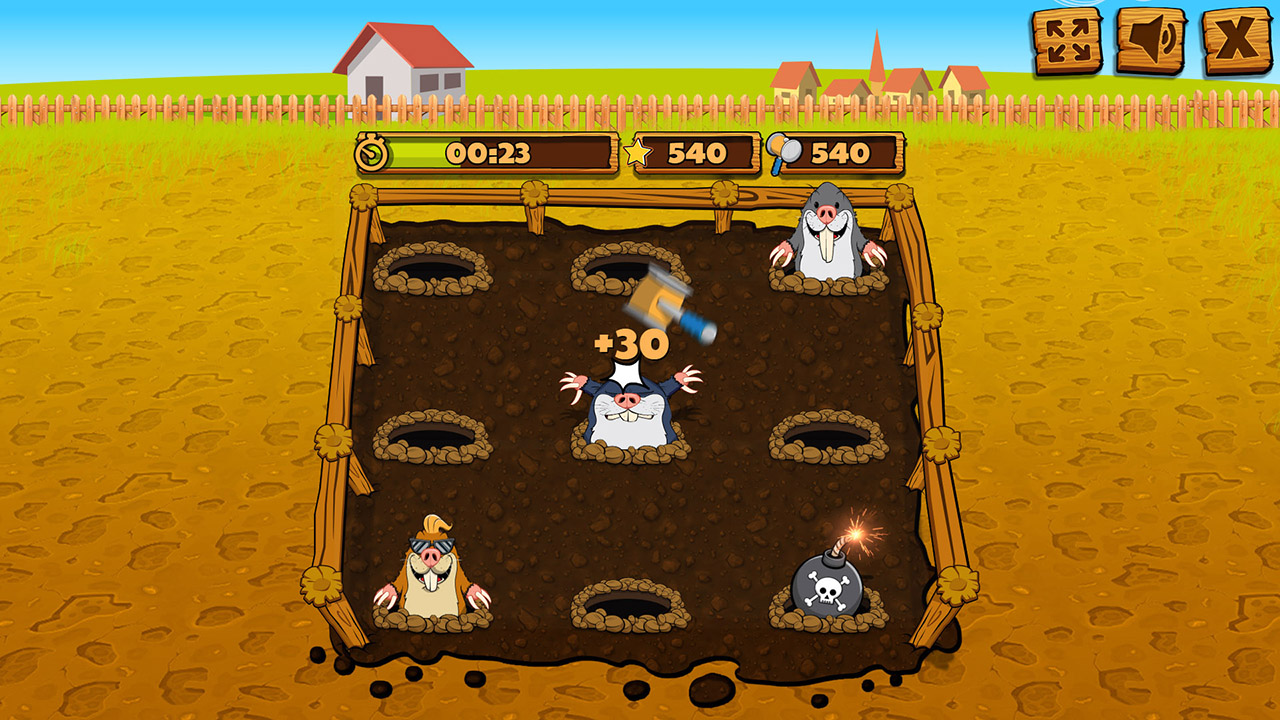
Whack ‘Em All
We all know how to play Whack a Mole, and now this computer knows how to too. Code here.
Pong
This last game also doesn’t need an introduction, and you can find the code here.
Is this machine learning or AI?
If you’d ask me, the videos above provide nice examples of advanced automation. But there’s no real machine learning or AI involved.
Yes, sure, the OpenCV package uses pre-trained neural networks under the hood, and you can definitely call those machine learning. But the programmers who now use the opencv library just leverage the knowledge stored in those network to create very basal decision rules.
IF pixel pattern of mole
THEN whack!
ELSE no whack.
To me, it’s only machine learning when there’s really some learning going on. A feedback loop with performance improvement. And you may call it AI, IMO, when the feedback loop is more or less autonomous.
Fortunately, programmers have also been taking a machine learning/AI approach to beating games. Specifically using reinforcement learning. Think of famous applications like AlphaGo and AlphaStar. But there are also hobby programmers who use similar techniques. For example, to get their computer to obtain highscores on Trackmania.
In a later post, I’ll dive into those in more detail.
While looking for laptops, it struck me that they can be so expensive for the hardware you get. I actually don’t need to my computer to be mobile, as most of the time it just sits in my study.
Hence, I opted for buying a desktop. And even better, I decided to build one myself!
I thought building a PC was going to be all complex and technical, but it’s actually really easy! I hope I can inspire you to try out for yourself as well.
Basically, you need only need 6 parts to build a computer:
Casing
Power supply
Motherboard
Processor (CPU)
Hard drive (SSD)
Memory (RAM)
Optional: Graphics card (GPU)
Optional: (extra) Fans
Via Pinterest (look at that old school case & speakers)
So I did some research into what hardware to buy. Specifically, I wanted a PC that could handle some deep learning and some of the newer video games. Hence, I decided on this setup:
Note: these are affiliate links. If you buy a similar setup, it will generate a few bucks used to keep my website live!
My new setup put together
My setup totalled to about €1100 or $1200, but it may depend on the vendors you pick. Nonetheless, the CPU and the GPU are definitely the most expensive (and important).
I did not buy any additional fans, as the Be Quiet base already had some pre-installed. However, I think it might be better to install extra’s.
Actually, it’s very easy to upgrade (or downgrade) your system. You can easily switch out modules to decrease or increase the performance (and cost). For instance, you can install another two memory cards on your motherboard, or simply spend more on a GPU.
After everything was delivered to my house, I thought the hard part started: building the desktop and putting everything together. But actually, this only took me about an hour or two, with the help of some great tutorials on Youtube:
I hope this convinces and helps you to build your own system at home!
I recently visited a data science meetup where one of the speakers — Harm Bodewes — spoke about playing out the Monty Hall problem with his kids.
TheMonty Hall problemis probability puzzle. Based on the American television game show Let’s Make a Deal and its host, named Monty Hall:
You’re given the choice of three doors.
Behind one door sits a prize: a shiny sports car.
Behind the others doors, something shitty, like goats.
You pick a door — say, door 1.
Now, the host, who knows what’s behind the doors, opens one of the other doors — say, door 2 — which reveals a goat.
The host then asks you: Do you want to stay with door 1, or would you like to switch to door 3?
The probability puzzle here is:
Is switching doors the smart thing to do?
Back to my meetup.
Harm — the presenter — had ran the Monty Hall experiment with his kids.
Twenty-five times, he had hidden candy under one of three plastic cups. His kids could then pick a cup, he’d remove one of the non-candy cups they had not picked, and then he’d proposed them to make the switch.
The results he had tracked, and visualized in a simple Excel graph. And here he was presenting these results to us, his Meetup audience.
People (also statisticans) had been arguing whether it is best to stay or switch doors for years. Yet, here, this random guy ran a play-experiment and provided very visual proof removing any doubts you might have yourself.
You really need to switch doors!
At about the same time, I came across this Github repo by Saghir, who had made some vectorised simulations of the problem in R. I thought it was a fun excercise to simulate and visualize matters in two different data science programming languages — Python & R — and see what I’d run in to.
So I’ll cut to the chase.
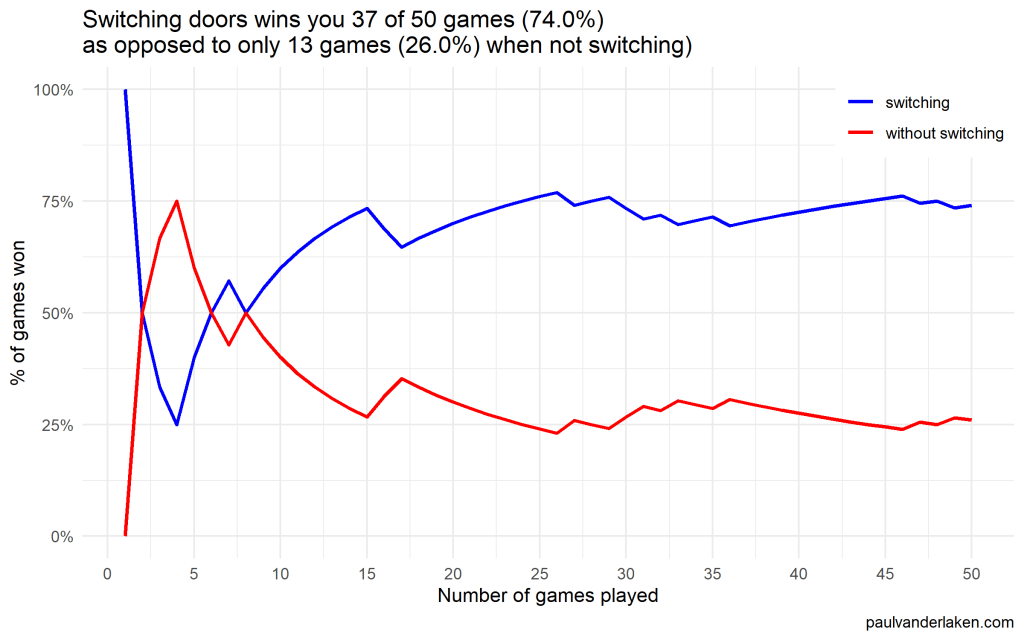
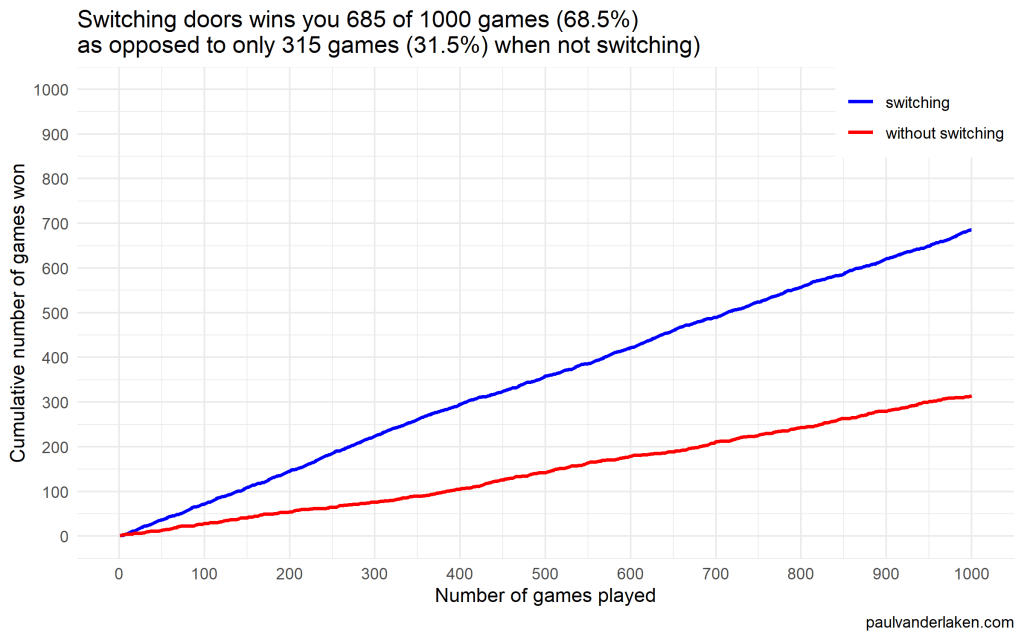
As we play more and more games against Monty Hall, it becomes very clear that you really, really, really need to switch doors in order to maximize the probability of winning a car.
Actually, the more games we play, the closer the probability of winning in our sample gets to the actual probability.
Even after 1000 games, the probabilities are still not at their actual values. But, ultimately…
If you stick to your door, you end up with the car in only 33% of the cases.
If you switch to the other door, you end up with the car 66% of the time!
Simulation Code
In both Python and R, I wrote two scripts. You can find the most recent version of the code on my Github. However, I pasted the versions of March 4th 2020 below.
The first script contains a function simulating a single game of Monty Hall. A second script runs this function an X amount of times, and visualizes the outcomes as we play more and more games.
Python
simulate_game.py
import random
def simulate_game(make_switch=False, n_doors=3, seed=None):
'''
Simulate a game of Monty Hall
For detailed information: https://en.wikipedia.org/wiki/Monty_Hall_problem
Basically, there are several closed doors and behind only one of them is a prize.
The player can choose one door at the start.
Next, the game master (Monty Hall) opens all the other doors, but one.
Now, the player can stick to his/her initial choice or switch to the remaining closed door.
If the prize is behind the player's final choice he/she wins.
Keyword arguments:
make_switch -- a boolean value whether the player switches after its initial choice and Monty Hall opening all other non-prize doors but one (default False)
n_doors -- an integer value > 2, for the number of doors behind which one prize and (n-1) non-prizes (e.g., goats) are hidden (default 3)
seed -- a seed to set (default None)
'''
# check the arguments
if type(make_switch) is not bool:
raise TypeError("`make_switch` must be boolean")
if type(n_doors) is float:
n_doors = int(n_doors)
raise Warning("float value provided for `n_doors`: forced to integer value of", n_doors)
if type(n_doors) is not int:
raise TypeError("`n_doors` needs to be a positive integer > 2")
if n_doors < 2:
raise ValueError("`n_doors` needs to be a positive integer > 2")
# if a seed was provided, set it
if seed is not None:
random.seed(seed)
# sample one index for the door to hide the car behind
prize_index = random.randint(0, n_doors - 1)
# sample one index for the door initially chosen by the player
choice_index = random.randint(0, n_doors - 1)
# we can test for the current result
current_result = prize_index == choice_index
# now Monty Hall opens all doors the player did not choose, except for one door
# next, he asks the player if he/she wants to make a switch
if (make_switch):
# if we do, we change to the one remaining door, which inverts our current choice
# if we had already picked the prize door, the one remaining closed door has a nonprize
# if we had not already picked the prize door, the one remaining closed door has the prize
return not current_result
else:
# the player sticks with his/her original door,
# which may or may not be the prize door
return current_result
visualize_game_results.py
from simulate_game import simulate_game
from random import seed
from numpy import mean, cumsum
from matplotlib import pyplot as plt
import os
# set the seed here
# do not set the `seed` parameter in `simulate_game()`,
# as this will make the function retun `n_games` times the same results
seed(1)
# pick number of games you want to simulate
n_games = 1000
# simulate the games and store the boolean results
results_with_switching = [simulate_game(make_switch=True) for _ in range(n_games)]
results_without_switching = [simulate_game(make_switch=False) for _ in range(n_games)]
# make a equal-length list showing, for each element in the results, the game to which it belongs
games = [i + 1 for i in range(n_games)]
# generate a title based on the results of the simulations
title = f'Switching doors wins you {sum(results_with_switching)} of {n_games} games ({mean(results_with_switching) * 100:.1f}%)' + \
'\n' + \
f'as opposed to only {sum(results_without_switching)} games ({mean(results_without_switching) * 100:.1f}%) when not switching'
# set some basic plotting parameters
w = 8
h = 5
# make a line plot of the cumulative wins with and without switching
plt.figure(figsize=(w, h))
plt.plot(games, cumsum(results_with_switching), color='blue', label='switching')
plt.plot(games, cumsum(results_without_switching), color='red', label='no switching')
plt.axis([0, n_games, 0, n_games])
plt.title(title)
plt.legend()
plt.xlabel('Number of games played')
plt.ylabel('Cumulative number of games won')
plt.figtext(0.95, 0.03, 'paulvanderlaken.com', wrap=True, horizontalalignment='right', fontsize=6)
# you can uncomment this to see the results directly,
# but then python will not save the result to your directory
# plt.show()
# plt.close()
# create a directory to store the plots in
# if this directory does not yet exist
try:
os.makedirs('output')
except OSError:
None
plt.savefig('output/monty-hall_' + str(n_games) + '_python.png')
Visualizations (matplotlib)
R
simulate-game.R
Note that I wrote a second function, simulate_n_games, which just runs simulate_game an N number of times.
#' Simulate a game of Monty Hall
#' For detailed information: https://en.wikipedia.org/wiki/Monty_Hall_problem
#' Basically, there are several closed doors and behind only one of them is a prize.
#' The player can choose one door at the start.
#' Next, the game master (Monty Hall) opens all the other doors, but one.
#' Now, the player can stick to his/her initial choice or switch to the remaining closed door.
#' If the prize is behind the player's final choice he/she wins.
#'
#' @param make_switch A boolean value whether the player switches after its initial choice and Monty Hall opening all other non-prize doors but one. Defaults to `FALSE`
#' @param n_doors An integer value > 2, for the number of doors behind which one prize and (n-1) non-prizes (e.g., goats) are hidden. Defaults to `3L`
#' @param seed A seed to set. Defaults to `NULL`
#'
#' @return A boolean value indicating whether the player won the prize
#'
#' @examples
#' simulate_game()
#' simulate_game(make_switch = TRUE)
#' simulate_game(make_switch = TRUE, n_doors = 5L, seed = 1)
simulate_game = function(make_switch = FALSE, n_doors = 3L, seed = NULL) {
# check the arguments
if (!is.logical(make_switch) | is.na(make_switch)) stop("`make_switch` needs to be TRUE or FALSE")
if (is.double(n_doors)) {
n_doors = as.integer(n_doors)
warning(paste("double value provided for `n_doors`: forced to integer value of", n_doors))
}
if (!is.integer(n_doors) | n_doors < 2) stop("`n_doors` needs to be a positive integer > 2")
# if a seed was provided, set it
if (!is.null(seed)) set.seed(seed)
# create a integer vector for the door indices
doors = seq_len(n_doors)
# create a boolean vector showing which doors are opened
# all doors are closed at the start of the game
isClosed = rep(TRUE, length = n_doors)
# sample one index for the door to hide the car behind
prize_index = sample(doors, size = 1)
# sample one index for the door initially chosen by the player
# this can be the same door as the prize door
choice_index = sample(doors, size = 1)
# now Monty Hall opens all doors the player did not choose
# except for one door
# if we have already picked the prize door, the one remaining closed door has a nonprize
# if we have not picked the prize door, the one remaining closed door has the prize
if (prize_index == choice_index) {
# if we have the prize, Monty Hall can open all but two doors:
# ours, which we remove from the options to sample from and open
# and one goat-conceiling door, which we do not open
isClosed[sample(doors[-prize_index], size = n_doors - 2)] = FALSE
} else {
# else, Monty Hall can also open all but two doors:
# ours
# and the prize-conceiling door
isClosed[-c(prize_index, choice_index)] = FALSE
}
# now Monty Hall asks us whether we want to make a switch
if (make_switch) {
# if we decide to make a switch, we can pick the closed door that is not our door
choice_index = doors[isClosed][doors[isClosed] != choice_index]
}
# we return a boolean value showing whether the player choice is the prize door
return(choice_index == prize_index)
}
#' Simulate N games of Monty Hall
#' Calls the `simulate_game()` function `n` times and returns a boolean vector representing the games won
#'
#' @param n An integer value for the number of times to call the `simulate_game()` function
#' @param seed A seed to set in the outer loop. Defaults to `NULL`
#' @param ... Any parameters to be passed to the `simulate_game()` function.
#' No seed can be passed to the simulate_game function as that would result in `n` times the same result
#'
#' @return A boolean vector indicating for each of the games whether the player won the prize
#'
#' @examples
#' simulate_n_games(n = 100)
#' simulate_n_games(n = 500, make_switch = TRUE)
#' simulate_n_games(n = 1000, seed = 123, make_switch = TRUE, n_doors = 5L)
simulate_n_games = function(n, seed = NULL, make_switch = FALSE, ...) {
# round the number of iterations to an integer value
if (is.double(n)) {
n = as.integer(n)
}
if (!is.integer(n) | n < 1) stop("`n_games` needs to be a positive integer > 1")
# if a seed was provided, set it
if (!is.null(seed)) set.seed(seed)
return(vapply(rep(make_switch, n), simulate_game, logical(1), ...))
}
visualize-game-results.R
Note that we source in the simulate-game.R file to get access to the simulate_game and simulate_n_games functions.
Also note that I make a second plot here, to show the probabilities of winning converging to their real-world probability as we play more and more games.
source('R/simulate-game.R')
# install.packages('ggplot2')
library(ggplot2)
# set the seed here
# do not set the `seed` parameter in `simulate_game()`,
# as this will make the function return `n_games` times the same results
seed = 1
# pick number of games you want to simulate
n_games = 1000
# simulate the games and store the boolean results
results_without_switching = simulate_n_games(n = n_games, seed = seed, make_switch = FALSE)
results_with_switching = simulate_n_games(n = n_games, seed = seed, make_switch = TRUE)
# store the cumulative wins in a dataframe
results = data.frame(
game = seq_len(n_games),
cumulative_wins_without_switching = cumsum(results_without_switching),
cumulative_wins_with_switching = cumsum(results_with_switching)
)
# function that turns values into nice percentages
format_percentage = function(values, digits = 1) {
return(paste0(formatC(values * 100, digits = digits, format = 'f'), '%'))
}
# generate a title based on the results of the simulations
title = paste(
paste0('Switching doors wins you ', sum(results_with_switching), ' of ', n_games, ' games (', format_percentage(mean(results_with_switching)), ')'),
paste0('as opposed to only ', sum(results_without_switching), ' games (', format_percentage(mean(results_without_switching)), ') when not switching)'),
sep = '\n'
)
# set some basic plotting parameters
linesize = 1 # size of the plotted lines
x_breaks = y_breaks = seq(from = 0, to = n_games, length.out = 10 + 1) # breaks of the axes
y_limits = c(0, n_games) # limits of the y axis - makes y limits match x limits
w = 8 # width for saving plot
h = 5 # height for saving plot
palette = setNames(c('blue', 'red'), nm = c('switching', 'without switching')) # make a named color scheme
# make a line plot of the cumulative wins with and without switching
ggplot(data = results) +
geom_line(aes(x = game, y = cumulative_wins_with_switching, col = names(palette[1])), size = linesize) +
geom_line(aes(x = game, y = cumulative_wins_without_switching, col = names(palette[2])), size = linesize) +
scale_x_continuous(breaks = x_breaks) +
scale_y_continuous(breaks = y_breaks, limits = y_limits) +
scale_color_manual(values = palette) +
theme_minimal() +
theme(legend.position = c(1, 1), legend.justification = c(1, 1), legend.background = element_rect(fill = 'white', color = 'transparent')) +
labs(x = 'Number of games played') +
labs(y = 'Cumulative number of games won') +
labs(col = NULL) +
labs(caption = 'paulvanderlaken.com') +
labs(title = title)
# save the plot in the output folder
# create the output folder if it does not exist yet
if (!file.exists('output')) dir.create('output', showWarnings = FALSE)
ggsave(paste0('output/monty-hall_', n_games, '_r.png'), width = w, height = h)
# make a line plot of the rolling % win chance with and without switching
ggplot(data = results) +
geom_line(aes(x = game, y = cumulative_wins_with_switching / game, col = names(palette[1])), size = linesize) +
geom_line(aes(x = game, y = cumulative_wins_without_switching / game, col = names(palette[2])), size = linesize) +
scale_x_continuous(breaks = x_breaks) +
scale_y_continuous(labels = function(x) format_percentage(x, digits = 0)) +
scale_color_manual(values = palette) +
theme_minimal() +
theme(legend.position = c(1, 1), legend.justification = c(1, 1), legend.background = element_rect(fill = 'white', color = 'transparent')) +
labs(x = 'Number of games played') +
labs(y = '% of games won') +
labs(col = NULL) +
labs(caption = 'paulvanderlaken.com') +
labs(title = title)
# save the plot in the output folder
# create the output folder if it does not exist yet
if (!file.exists('output')) dir.create('output', showWarnings = FALSE)
ggsave(paste0('output/monty-hall_perc_', n_games, '_r.png'), width = w, height = h)
Visualizations (ggplot2)
I specifically picked a seed (the second one I tried) in which not switching looked like it was better during the first few games played.
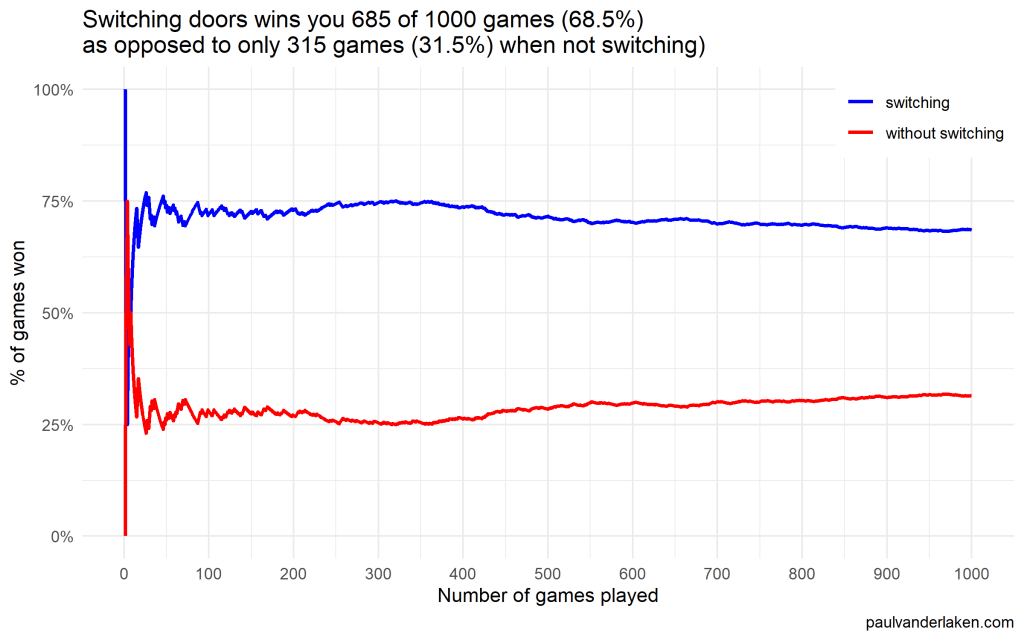
In R, I made an additional plot that shows the probabilities converging.
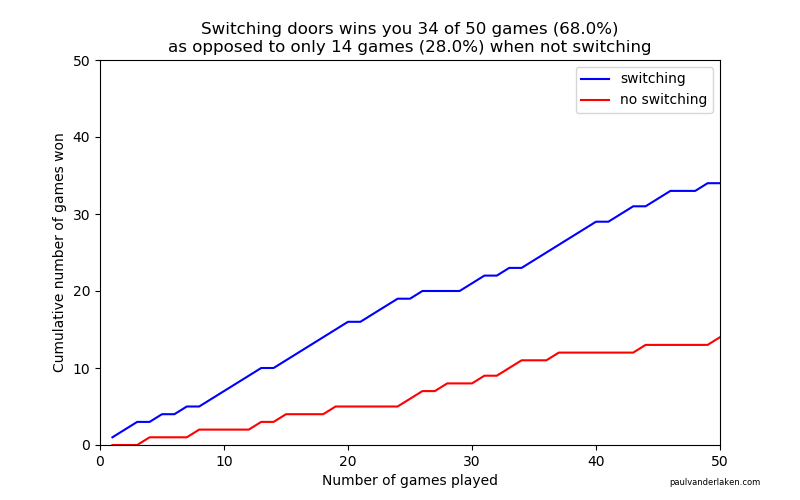
As we play more and more games, our results move to the actual probabilities of winning:
After the first four games, you could have erroneously concluded that not switching would result in better chances of you winning a sports car. However, in the long run, that is definitely not true.
I was actually suprised to see that these lines look to be mirroring each other. But actually, that’s quite logical maybe… We already had the car with our initial door guess in those games. If we would have sticked to that initial choice of a door, we would have won, whereas all the cases where we switched, we lost.
Keep me posted!
I hope you enjoyed these simulations and visualizations, and am curious to see what you come up with yourself!
For instance, you could increase the number of doors in the game, or the number of goat-doors Monty Hall opens. When does it become a disadvantage to switch?
After several years of proscrastinating, the inevitable finally happened: Three months ago, I committed to learning Python!
I must say that getting started was not easy. One afternoon three months ago, I sat down, motivated to get started. Obviously, the first step was to download and install Python as well as something to write actual Python code. Coming from R, I had expected to be coding in a handy IDE within an hour or so. Oh boy, what was I wrong.
Apparently, there were already a couple of versions of Python present on my computer. And apparently, they were in grave conflict. I had one for the R reticulate package; one had come with Anaconda; another one from messing around with Tensorflow; and some more even. I was getting all kinds of error, warning, and conflict messages already, only 10 minutes in. Nothing I couldn’t handle in the end, but my good spirits had dropped slightly.
With Python installed, the obvious next step was to find the RStudio among the Python IDE’s and get working in that new environment. As an rational consumer, I went online to read about what people recommend as a good IDE. PyCharm seemed to be quite fancy for Data Science. However, what’s this Spyder alternative other people keep talking about? Come again, there are also Rodeo, Thonny, PyDev, and Wing? What about those then? A whole other group of Pythonista’s said that, as I work in Data Science, I should get Anaconda and work solely in Jupyter Notebooks! Okay…? But I want to learn Python to broaden my skills and do more regular software development as well. Maybe I start simple, in a (code) editor? However, here we have Atom, Sublime Text, Vim, and Eclipse? All these decisions. And I personally really dislike making regrettable decisions or committing to something suboptimal. This was already taking much, much longer than the few hours I had planned for setup.
This whole process demotivated so much that I reverted back to programming in R and RStudio the week after. However, I had not given up. Over the course of the week, I brought the selection back to Anaconda Jupyter Notebooks, PyCharm, and Atom, and I was ready to pick one. But wait… What’s this Visual Studio Code (VSC) thing by Microsoft. This looks fancy. And it’s still being developed and expanded. I had already been working in Visual Studio learning C++, and my experiences had been good so far. Moreover, Microsoft seems a reliable software development company, they must be able to build a good IDE? I decided to do one last deepdive.
The more I read about VSC and its features for Python, the more excited I got. Hey, VSC’s Python extension automatically detects Python interpreters, so it solves my conflicts-problem. Linting you say? Never heard of it, but I’ll have it. Okay, able to run notebooks, nice! Easy debugging, testing, and handy snippets… Okay! Machine learning-based IntelliSense autocompletes your Python code – that sounds like something I’d like. A shit-ton of extensions? Yes please! Multi-language support – even tools for R programming? Say no more! I’ll take it. I’ll take it all!
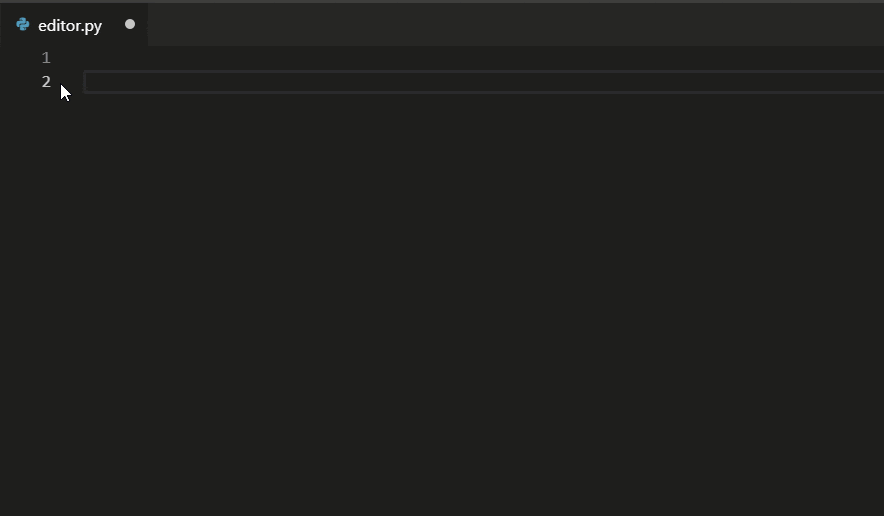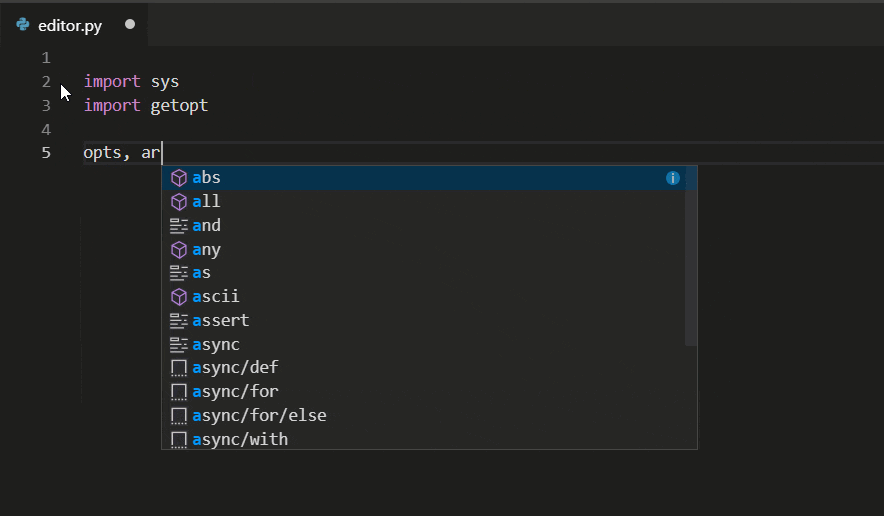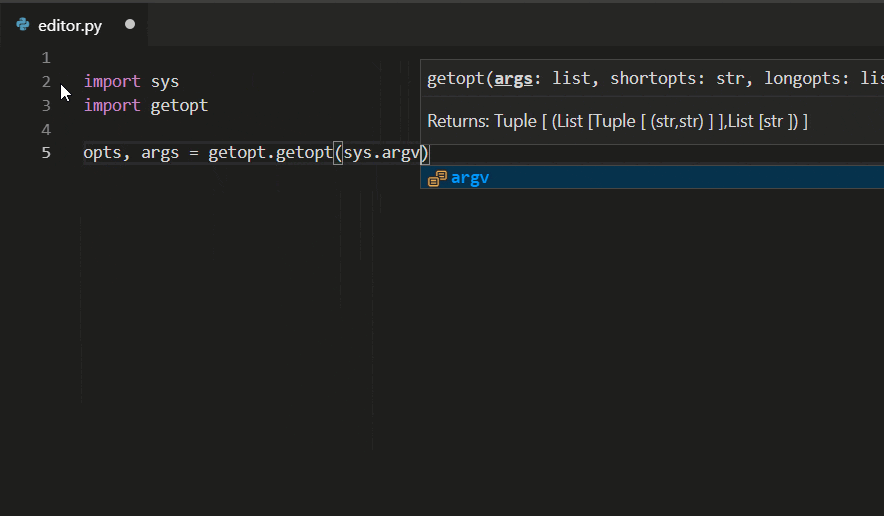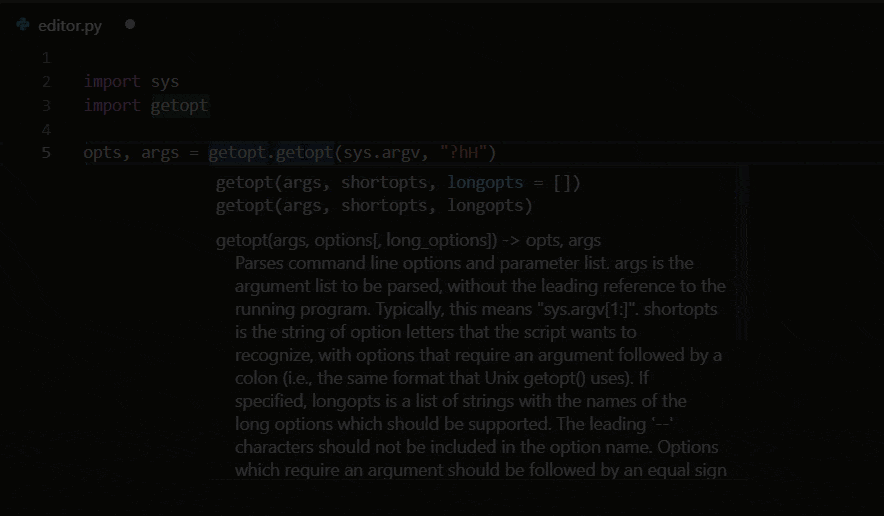
Linting in VSC provides code suggestions
My goods friends at Microsoft were not done yet though. To top it all of, they have documented everything so well. It’s super easy to get started! There are numerous ordered pages dedicated to helping you set up and discover your new Python environment in VSC:
The Microsoft VSC pages also link to some more specific resources:
Editing Python in VS Code: Learn more about how to take advantage of VS Code’s autocomplete and IntelliSense support for Python, including how to customize their behvior… or just turn them off.
Linting Python: Linting is the process of running a program that will analyse code for potential errors. Learn about the different forms of linting support VS Code provides for Python and how to set it up.
Debugging Python: Debugging is the process of identifying and removing errors from a computer program. This article covers how to initialize and configure debugging for Python with VS Code, how to set and validate breakpoints, attach a local script, perform debugging for different app types or on a remote computer, and some basic troubleshooting.
Unit testing Python: Covers some background explaining what unit testing means, an example walkthrough, enabling a test framework, creating and running your tests, debugging tests, and test configuration settings.
Python IntelliSense in VSC makes real-time code autocomplete suggestions
My Own Python Journey
So three months in I am completely blown away at how easy, fun, and versatile the language is. Nearly anything is possible, most of the language is intuitive and straightforward, and there’s a package for anything you can think of. Although I have spent many hours, I am very happy with the results. I did not get this far, this quickly, in any other language. Let me share some of the stuff I’ve done the past three months.
I’ve mainly been building stuff. Some things from scratch, others by tweaking and recycling other people’s code. In my opinion, reusing other people’s code is not necessarily bad, as long as you understand what the code does. Moreover, I’ve combed through lists and lists of build-it-yourself projects to get inspiration for projects and used stuff from my daily work and personal life as further reasons to code. I ended up building:
solutions to the first 31 problems of Project Euler, which I highly recommend you try to solve yourself!
solutions to the first dozen problems posed in Automate the Boring Stuff with Python. This book and online tutorial forces you to get your hands dirty right from the start. Simply amazing content and the learning curve is precisely good
"Programming today is a race between software engineers striving to build bigger and better idiot-proof programs, and the universe trying to build bigger and better idiots. So far, the universe is winning." – Rick Cook#programming#coding#ArtificialStupidity no.20 pic.twitter.com/cBiR1HQszn
all Socratica Python Youtube videos. They are simply a fantastic introduction to the language and amazingly amusing. You can sponsor them here
hours and hours of Corey Shafer’s Youtube channel. Seriously good quality content, and more in-depth than Socratica. Corey covers the versatile functionalities included in the standard Python libraries and then some more
Although it is no longer maintained, you might find some more, interesting links on my Python resources page or here, for those transitioning from R. If only the links to the more up-to-date resources pages. Anyway, hope this current blog helps you on your Python journey or to get Python and Visual Studio Code working on your computer. Please feel free to share any of the stories, struggles, or successes you experience!
Last week, this interesting reddit thread was filled with overviews for cool projects that may help you learn a programming language. The top entries are: