The “world wide web” hosts millions of datasets, on nearly any topic you can think of. Google’s Dataset Search has indexed almost 25 million of these datasets, giving you a single entry point to search for datasets online. After a year of testing, Dataset Search is now officially out of beta.
After alpha testing, Dataset Search now includes filter based on the types of dataset that you want (e.g., tables, images, text), on whether the dataset is open source/access. For dataset on geographic area’s, you can see the map. The quality of dataset’s descriptions has improved greatly, and the tool now has a mobile version.
Norm Matloff is a professor of Computer Science at University College Davis. He recently updated his viewpoint on whether R or Python is the best language for Data Science. While I normally hate those opinionated comparisons, Norm’s outline of the two languages’ (dis)advantages is actually quite balanced and well-versed.
I can mostly agree with Norm, although the blog reads as if he has a (slight) bias in favor of R. In his original blog, Norm discusses many different programming topics and provides detailed information on why he considers certain topics big wins, slight edges, or ties between the two programming languages.
In the table below, I’ve tried to summarize Norm’s opinions by converting his words to 0-100 scores per topic for a quicker overview. I’ve converted Norm’s words to scores: his huge win became 100-0, a big win 80-20, a win 70-30, an edge 60-40, and a tie 50-50.
Python
R
Elegance
100
Learning curve
100
Data Science libraries
40
60
Machine Learning
60
40
Statistical correctness
20
80
Parallel computing
50
50
C/C++ interface
40
60
Object orientation, metaprogramming
40
60
Language unity
100
Linked data structures
70
30
Online help
20
80
I personally started my career with R, so that’s definitely my favorite programming language. However, I think that Python is more convenient and faster on certain topics, and closer to more mainstream programming languages, which I why I’m currently learning it next to using R.
PS. This tweet by John summarizes the whole discussion quite well.
Someone asked me "R vs. Python", so: 1. It depends what you're trying to do 2. If you're trying to capitalise the letter r, I'd go with R, but if you're trying to strangle a woodland animal, I'd say python 3. Java is better than either. It's a huge island! Tropical rainforests!
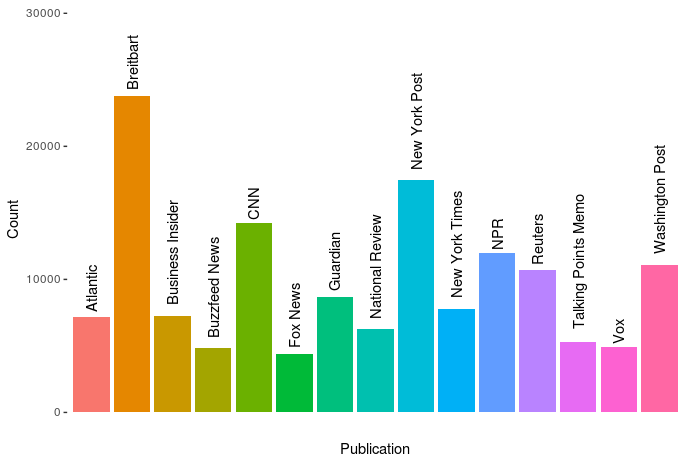
Andrew Thompson was interested in what 10 topics a computer would identify in our daily news. He gathered over 140.000 new articles from the archives of 10 different sources, as you can see in the figure below.
The sources of the news articles used in the analysis.
In Python, Andrew converted the text of all these articles into a manageable form (tf-idf document term matrix (see also Harry Plotter: Part 2)), reduced these data to 100 dimensions using latent semantic analysis (singular value decomposition), and ran a k-means clustering to retrieve the 10 main clusters. I included his main results below, but I highly suggest you visit the original article on Medium as Andrew used Plotly to generate interactive plots!
Most important words per topic (interactive visual in original article)
The topics structure seems quite nice! Topic 0 involves legal issues, such as immigration, whereas topic 1 seems to be more about politics. Topic 8 is clearly sports whereas 9 is education. Next, Andres inspected which media outlet covers which topics most. Again, visit the original article for interactive plots!
Media outlets and the topics they cover (interactive version in original article)
In light of the fake news crisis and the developments in (internet) media, I believe Andrew’s conclusions on these data are quite interesting.
I suppose different people could interpret this data and these graphs differently, but I interpret them as the following: when forced into groups, the publications sort into Reuters and everything else.
[…]
Every publication in this dataset except Reuters shares some common denominators. They’re entirely funded on ads and/or subscriptions (Vox and BuzzFeed also have VC funding, but they’re ad-based models), and their existence relies on clicks. By contrast, Reuters’s news product is merely the public face of a massive information conglomerate. Perhaps more importantly, it’s a news wire whose coverage includes deep reporting on the affairs of our financial universe, and therefore is charged with a different mandate than the others — arguably more than the New York Times, it must cover all the news, without getting trapped in the character driven reality-TV spectacle that every other citizen of the dataset appears to so heavily relish in doing. Of them all, its voice tends to maintain the most moderate indoor volume, and no single global event provokes larger-than-life outrage, if outrage can be provoked from Reuters at all. Perhaps this is the product of belonging to the financial press and analyzing the world macroscopically; the narrative of the non-financial press fails to accord equal weight to a change in the LIBOR rate and to the policy proposals of a madman, even though it arguably should. Every other publication here seems to bear intimations of utopia, and the subtext of their content is often that a perfect world would materialize if we mixed the right ingredients in the recipe book, and that the thing you’re outraged about is actually the thing standing between us and paradise. In my experience as a reader, I’ve never felt anything of the sort emanate from Reuters.
This should not be interpreted as asserting that the New York Times and Breitbart are therefore identical cauldrons of apoplexy. I read a beautifully designed piece today in the Times about just how common bioluminescence is among deep sea creatures. It goes without saying that the prospect of finding a piece like that in Breitbart is nonexistent, which is one of the things I find so god damned sad about that territory of the political spectrum, as well as in its diametrical opponents a la Talking Points Memo. But this is the whole point: show an algorithm the number of stories you write about deep sea creatures and it’ll show you who you are. At a finer resolution, we would probably find a chasm between the Times and Fox News, or between NPR and the New York Post. See that third cluster up there, where all the words are kind of compressed with lower TfIdf values and nothing sticks out? It’s actually a whole jungle of other topics, and you can run the algorithm on just that cluster and get new groups and distinctions — and one of those clusters will also be a compression of different kinds of stories, and you can do this over and over in a fractal of machine learning. The distinction here is not the only one, but it is, from the aerial perspective of data, the first.
It would be really interesting to see whether more high-quality media outlets, like the New York Times, could be easily distinguished from more sensational outlets, such as Buzzfeed, when more clusters were used, or potentially other text analytics methodology, like latent Dirichlet allocation.






{kind=link}