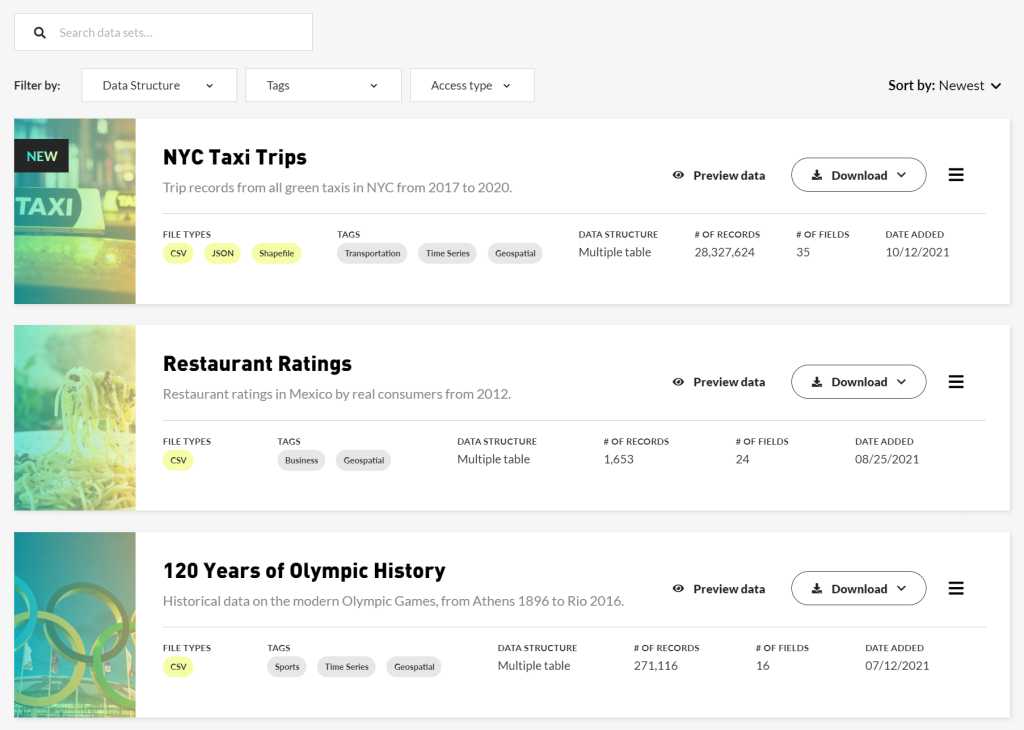
They offer 21 datasets including a range of different data (time series, geospatial, user preferences) on a variety of topics like business, sports, wine, financial stocks, transportation and whatnot.
This is a great starting point if you want to practice your data science, machine learning and analysis skills on real life data!
Maven Analytics provides e-learnings in analysis and programming software. To provide a practical learning experience, their courses are often accompanied by real-life datasets for students to analyze.
The “world wide web” hosts millions of datasets, on nearly any topic you can think of. Google’s Dataset Search has indexed almost 25 million of these datasets, giving you a single entry point to search for datasets online. After a year of testing, Dataset Search is now officially out of beta.
After alpha testing, Dataset Search now includes filter based on the types of dataset that you want (e.g., tables, images, text), on whether the dataset is open source/access. For dataset on geographic area’s, you can see the map. The quality of dataset’s descriptions has improved greatly, and the tool now has a mobile version.
Case.law seems like a very interesting data source for a machine learning or text mining project:
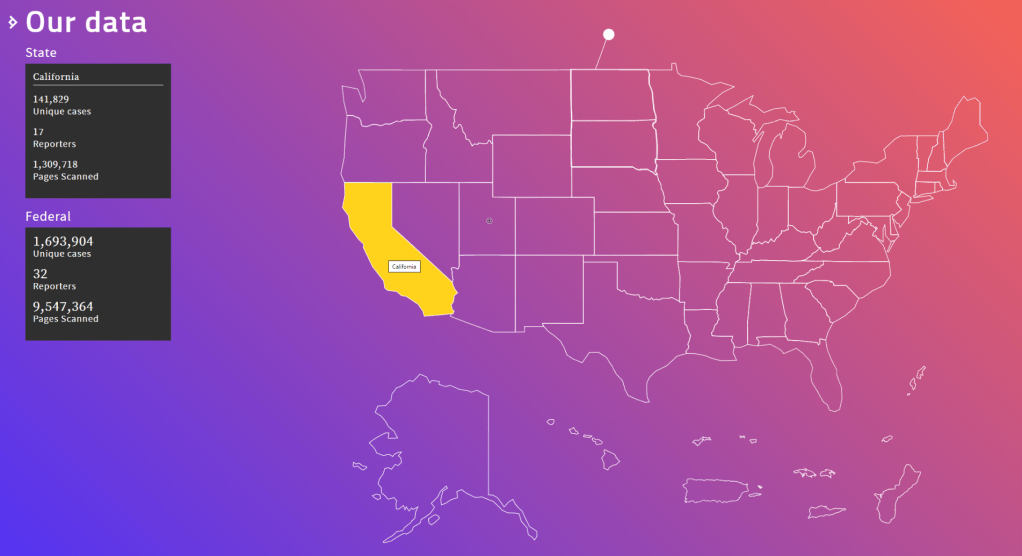
The Caselaw Access Project (“CAP”) expands public access to U.S. law. Our goal is to make all published U.S. court decisions freely available to the public online, in a consistent format, digitized from the collection of the Harvard Law Library.
The capstone of the Caselaw Access Project is a robust set of tools which facilitate access to the cases and their associated metadata. We currently offer five ways to access the data: API, bulk downloads, search, browse, and a historical trends viewer.
Our open-source API is the best option for anybody interested in programmatically accessing our metadata, full-text search, or individual cases.
If you need a large collection of cases, you will probably be best served by our bulk data downloads. Bulk downloads for Illinois and Arkansas are available without a login, and unlimited bulk files are available to research scholars.
Case metadata, such as the case name, citation, court, date, etc., is freely and openly accessible without limitation. Full case text can be freely viewed or downloaded but you must register for an account to do so, and currently you may view or download no more than 500 cases per day. In addition, research scholars can qualify for bulk data access by agreeing to certain use and redistribution restrictions. You can request a bulk access agreement by creating an account and then visiting your account page.
Access limitations on full text and bulk data are a component of Harvard’s collaboration agreement with Ravel Law, Inc. (now part of Lexis-Nexis). These limitations will end, at the latest, in March of 2024. In addition, these limitations apply only to cases from jurisdictions that continue to publish their official case law in print form. Once a jurisdiction transitions from print-first publishing to digital-first publishing, these limitations cease. Thus far, Illinois and Arkansas have made this important and positive shift and, as a result, all historical cases from these jurisdictions are freely available to the public without restriction. We hope many other jurisdictions will follow their example soon.
A different project altogether is helping the team behind Caselaw improve its data quality:
Our data inevitably includes countless errors as part of the digitization process. The public launch of this project is only the start of discovering errors, and we hope you will help us in finding and fixing them.
Some parts of our data are higher quality than others. Case metadata, such as the party names, docket number, citation, and date, has received human review. Case text and general head matter has been generated by machine OCR and has not received human review.
You can report errors of all kinds at our Github issue tracker, where you can also see currently known issues. We particularly welcome metadata corrections, feature requests, and suggestions for large-scale algorithmic changes. We are not currently able to process individual OCR corrections, but welcome general suggestions on the OCR correction process.
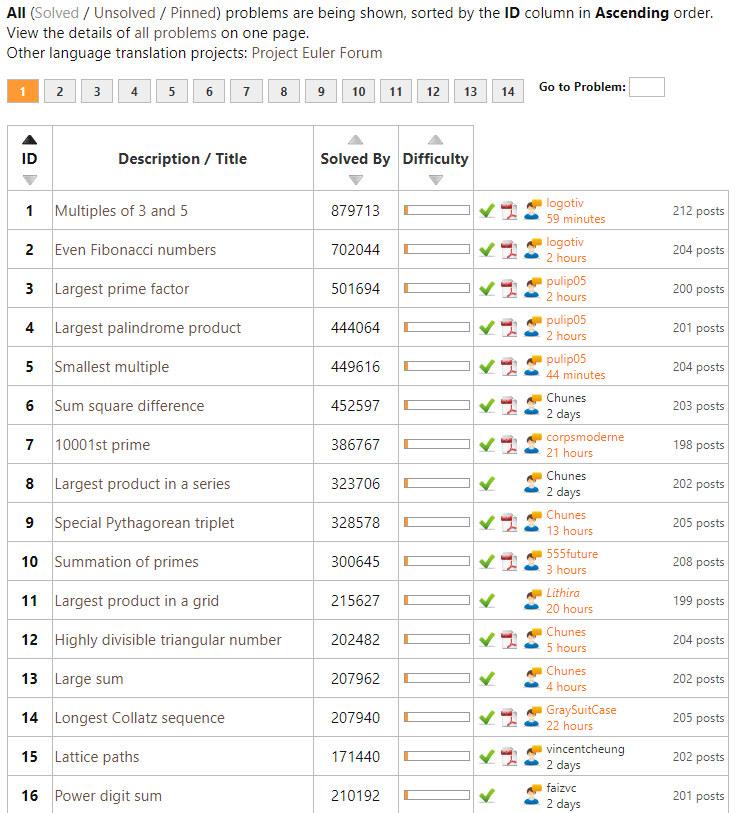
Over the last months I’ve been working my way through Project Euler in my spare time. I wanted to learn Python programming, and what better way than solving mini-problems and -projects?!
Well, Project Euler got a ton of these, listed in increasing order of difficulty. It starts out simple: to solve the first problem you need to write a program to identify multiples of 3 and 5. Next, in problem two, you are asked to sum the first thousand even Fibonacci numbers. Each problem, the task at hand gets slighly more difficult…
For me, Project Euler combines math, programming, and stats in a way that really keeps me motivated to continue and learn new concepts and programming / problem-solving approaches.
However, at problem 31, I really got stuck. For several hours, I struggled to solve it in a satisfactory fashion, even though most other problems only take 5-90 minutes.
After hours of struggling, I pretty much gave up, and googled some potential solutions. Aparently, the way to solve problem 31, is to take a so-called dynamic programming approach.
Dynamic programming is both a mathematical optimization method and a computer programming method. The method was developed by Richard Bellman in the 1950s and has found applications in numerous fields, from aerospace engineering to economics. In both contexts it refers to simplifying a complicated problem by breaking it down into simpler sub-problems in a recursive manner. While some decision problems cannot be taken apart this way, decisions that span several points in time do often break apart recursively. Likewise, in computer science, if a problem can be solved optimally by breaking it into sub-problems and then recursively finding the optimal solutions to the sub-problems, then it is said to have optimal substructure.
Now, this sounded like something I’d like to learn more about! I was already quite familiar with recursive problems and solutions, but this dynamic programming sounded next-level.
So I googled and googled for tutorials and other resources, and I finally came across this free 2011 MIT course that I intend to view over the coming weeks.
There’s even a course website with additional materials and assignments (in Python).
For those less interested in (dynamic) programming but mostly in machine learning, there’s this other great MIT OpenCourseWare youtube playlist of their Artificial Intelligence course. I absolutely loved that course and I really powered through it in a matter of weeks (which is why I am already psyched about this new one). I learned so much new concepts, and I strongly recommend it. Unfortunately, the professor recently passed away.
Looking for a custom typeface to use in your data visualizations? Google Fonts is an awesome databank of nearly a thousands font families you can access, download, and use for free.