Google Brain researchers published this amazing paper, with accompanying GIF where they show the true power of AutoML.
AutoML stands for automated machine learning, and basically refers to an algorithm autonomously building the best machine learning model for a given problem.
This task of selecting the best ML model is difficult as it is. There are many different ML algorithms to choose from, and each of these has many different settings ([hyper]parameters) you can change to optimalize the model’s predictions.
For instance, let’s look at one specific ML algorithm: the neural network. Not only can we try out millions of different neural network architectures (ways in which the nodes and lyers of a network are connected), but each of these we can test with different loss functions, learning rates, dropout rates, et cetera. And this is only one algorithm!
In their new paper, the Google Brain scholars display how they managed to automatically discover complete machine learning algorithms just using basic mathematical operations as building blocks. Using evolutionary principles, they have developed an AutoML framework that tailors its own algorithms and architectures to best fit the data and problem at hand.
This is AI research at its finest, and the results are truly remarkable!
Sometimes I find these AI / programming hobby projects that I just wished I had thought of…
Will Stedden combined OpenAI’s GPT-2 deep learning text generation model with another deep-learning language model by Google called BERT (Bidirectional Encoder Representations from Transformers) and created an elaborate architecture that had one purpose: posting the best replies on Reddit.
The architecture is shown at the end of this post — copied from Will’s original bloghere. Moreover, you can read this post for details regarding the construction of the system. But let me see whether I can explain you what it does in simple language.
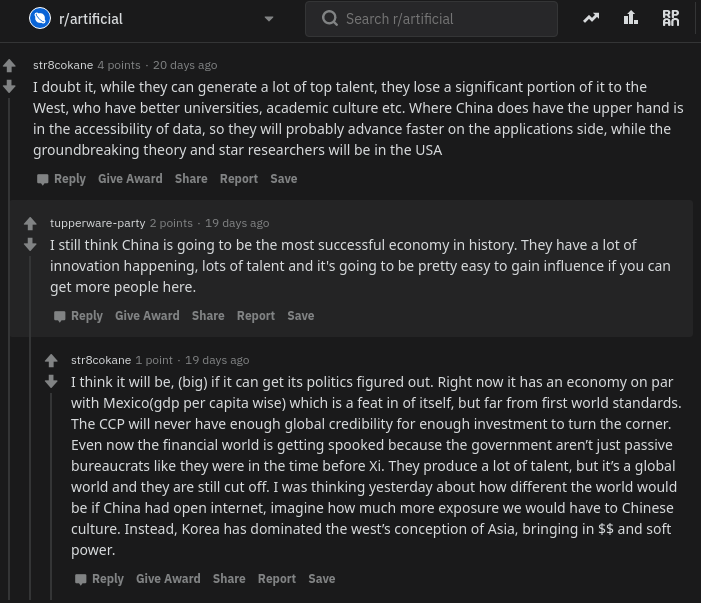
The below is what a Reddit comment and reply thread looks like. We have str8cokane making a comment to an original post (not in the picture), and then tupperware-party making a reply to that comment, followed by another reply by str8cokane. Basically, Will wanted to create an AI/bot that could write replies like tupperware-party that real people like str8cokane would not be able to distinguish from “real-people” replies.
Note that with 4 points, str8cokane‘s original comments was “liked” more than tupperware-party‘s reply and str8cokane‘s next reply, which were only upvoted 2 and 1 times respectively.
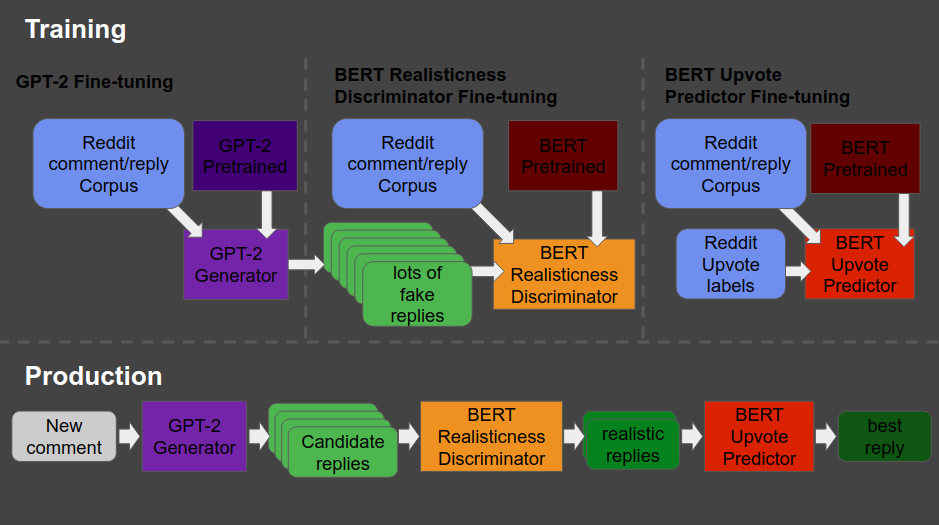
So here’s what the final architecture looks like, and my attempt to explain it to you.
Basically, we start in the upper left corner, where Will uses a database (i.e. corpus) of Reddit comments and replies to fine-tune a standard, pretrained GPT-2 model to get it to be good at generating (red: “fake”) realistic Reddit replies.
Next, in the upper middle section, these fake replies are piped into a standard, pretrained BERT model, along with the original, real Reddit comments and replies. This way the BERT model sees both real and fake comments and replies. Now, our goal is to make replies that are undistinguishable from real replies. Hence, this is the task the BERT model gets. And we keep fine-tuning the original GPT-2 generator until the BERT discriminator that follows is no longer able to distinguish fake from real replies. Then the generator is “fooling” the discriminator, and we know we are generating fake replies that look like real ones! You can find more information about such generative adversarial networks here.
Next, in the top right corner, we fine-tune another BERT model. This time we give it the original Reddit comments and replies along with the amount of times they were upvoted (i.e. sort of like likes on facebook/twitter). Basically, we train a BERT model to predict for a given reply, how much likes it is going to get.
Finally, we can go to production in the lower lane. We give a real-life comment to the GPT-2 generator we trained in the upper left corner, which produces several fake replies for us. These candidates we run through the BERT discriminator we trained in the upper middle section, which determined which of the fake replies we generated look most real. Those fake but realistic replies are then input into our trained BERT model of the top right corner, which predicts for every fake but realistic reply the amount of likes/upvotes it is going to get. Finally, we pick and reply with the fake but realistic reply that is predicted to get the most upvotes!
What Will’s final architecture, combining GPT-2 and BERT, looked like (via bonkerfield.org)
The results are astonishing! Will’s bot sounds like a real youngster internet troll! Do have a look at the original blog, but here are some examples. Note that tupperware-party — the Reddit user from the above example — is actually Will’s AI.
Will ends his blog with a link to the tutorial if you want to build such a bot yourself. Have a try!
Moreover, he also notes the ethical concerns:
I know there are definitely some ethical considerations when creating something like this. The reason I’m presenting it is because I actually think it is better for more people to know about and be able to grapple with this kind of technology. If just a few people know about the capacity of these machines, then it is more likely that those small groups of people can abuse their advantage.
I also think that this technology is going to change the way we think about what’s important about being human. After all, if a computer can effectively automate the paper-pushing jobs we’ve constructed and all the bullshit we create on the internet to distract us, then maybe it’ll be time for us to move on to something more meaningful.
If you think what I’ve done is a problem feel free to email me , or publically shame me on Twitter.
Xander Steenbrugge shared his latest work on LinkedIn yesterday, and I was completely stunned!
Xander had been working on, what he called, a “fun side-project”, but which was in my eyes, absolutely awesome. He had used two generative adversarial networks (GANs) to teach one another how to respond visually to changing audio cues.
This resulted in the generation of stunning audio-visual fanatasy worlds that are complete brain porn. You just can’t stop staring. So much is happening in these video’s; everything looks familiar, whereas nothing really represent anything realistic. There’s always a sliver of reality before the visual shapes morph to their next form.
Have a look yourself at the video’s on Xander’s new Youtube channel “Neural Synesthesia“ dedicated to this project. The videos are also hosted here on Vimeo, where they are rendered in higher resolution even.
This is my favorite video, but there are more below.
Amazing how the image responds to changes in the music, right? I suspect Xander let’s the algorithm traverse some latent space with spaces that are determined by the bass, trebble, and other audio-cues.
Here’s another one of Xander’s videos, with the same audio track as background:
But Xander didn’t limit his GANs to generating landscapes and still paintings, but he also dared to do some human faces. These also turned out amazing.
Both the left and right face seem to start out in about the same position/seed in the latent space, but traverse in different, though still similar directions, morphing into all kinds of reaslistic and more alien forms. The result is simply out of this world!
Curious to see where this project and others head as we continue to see development in this GAN field. This must turn the world of design and art up side down in the coming decade…
A beautiful machine-generated still from the Neural Synthesia videos (link)
I’ve seen some uses of reinforcement learning and generative algorithms for architectural purposes already, like these evolving blueprints for school floorplans. However, this new application called ArchiGAN blew me away!
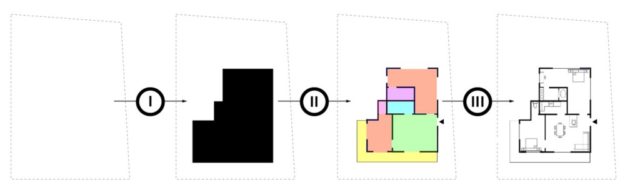
ArchiGAN (try here) was made by Stanislas Chaillou as a Harvard master’s thesis project. The program functions in three steps:
building footprint massing
program repartition
furniture layout
Stanislas’ three generation steps
Each of these three steps uses a TensorFlow Pix2Pix GAN-model (Christopher Hesse’s implementation) in the back-end, and their combination makes for a entire apartment building “generation stack” — according to Stanislas — which also allows for user input at each step.
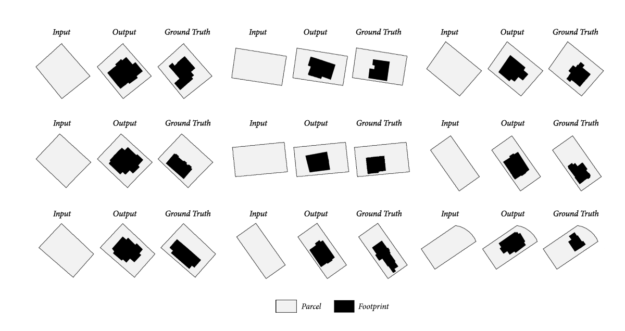
The design of a building can be inferred from the piece of land it stands on. Hence, Stanislas fed his first model using GIS-data (Geographic Information System) from the city of Boston in order to generate typical footprints based on parcel shapes.
The inputs and outputs of model I
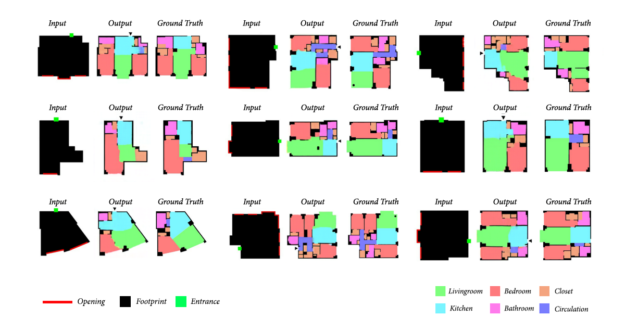
Stanislas’ second model was responsible for repartition and fenestration (the placement of windows and doors). This GAN took the footprint of the building (the output of model I) as input, along with the position of the entrance door (green square), and the positions of the user-specified windows.
Stanislas used a database of 800+ plans of apartments for training. To visualize the output, rooms are color-coded and walls and fenestration are blackened.
The inputs and outputs of model II
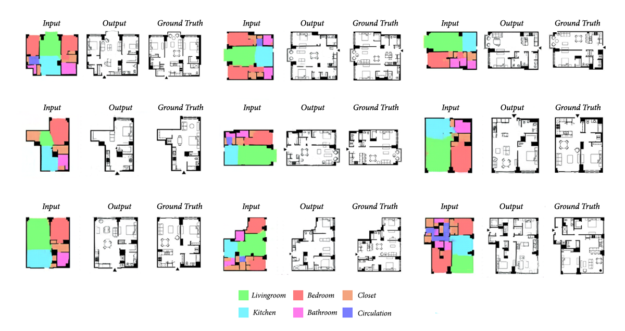
Finally, in the third model, the rooms are filled with appropriate furniture. What training data Stanislas has used here, he did not specify in the original blog.
The inputs and outputs of model III
Now, to put all things together, Stanislas created a great interactive tool you can play with yourself. The original NVIDEA blog contains some great GIFs of the tool being used:
Stanislas’ GAN-models progressively learned to design rooms and realistically position doors and windows. It took about 250 iterations to get some realistic floorplans out of the algorithm. Here’s how an example learning sequence looked like:
Visualization of the training process
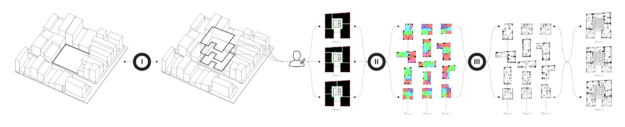
Now, Stanislas was not done yet. He also scaled the utilization of GANs to design whole apartment buildings. Here, he chains the models and processes multiple units as single images at each step.
Generating whole appartment blocks using ArchiGAN
Stanislas did other cool things to improve the flexibility of his ArchiGAN models, about which you can read more in the original blog. Let these visuals entice you to read more:
ArchiGAN scaled to handle whole appartment blocks and neighborhoods.
I believe a statistical approach to design conception will shape AI’s potential for Architecture. This approach is less deterministic and more holistic in character. Rather than using machines to optimize a set of variables, relying on them to extract significant qualities and mimicking them all along the design process represents a paradigm shift.
I am so psyched about these innovative applications of machine learning, so please help me give Stanislas the attention and credit he deserved.
Currently, Stanislas is Data Scientist & Architect at Spacemaker.ai. Read more about him in his NVIDEA developer bio here. He recently published a sequence of articles, laying down the premise of AI’s intersection with Architecture. Read here about the historical background behind this significant evolution, to be followed by AI’s potential for floor plan design, and for architectural style analysis & generation.