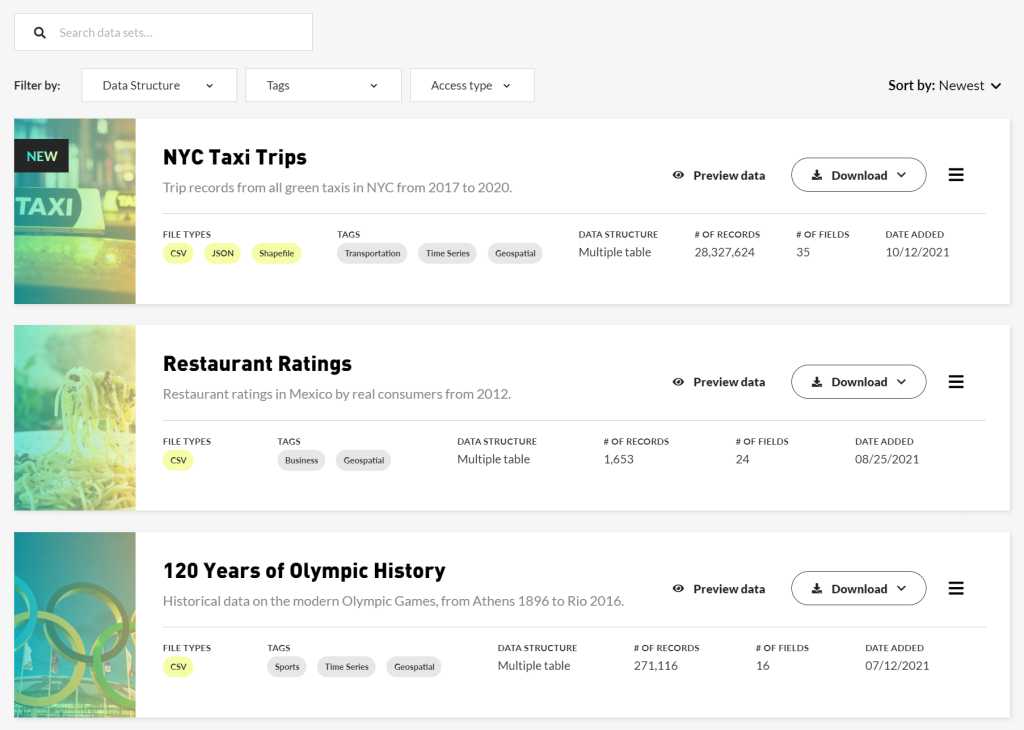
They offer 21 datasets including a range of different data (time series, geospatial, user preferences) on a variety of topics like business, sports, wine, financial stocks, transportation and whatnot.
This is a great starting point if you want to practice your data science, machine learning and analysis skills on real life data!
Maven Analytics provides e-learnings in analysis and programming software. To provide a practical learning experience, their courses are often accompanied by real-life datasets for students to analyze.
Case.law seems like a very interesting data source for a machine learning or text mining project:
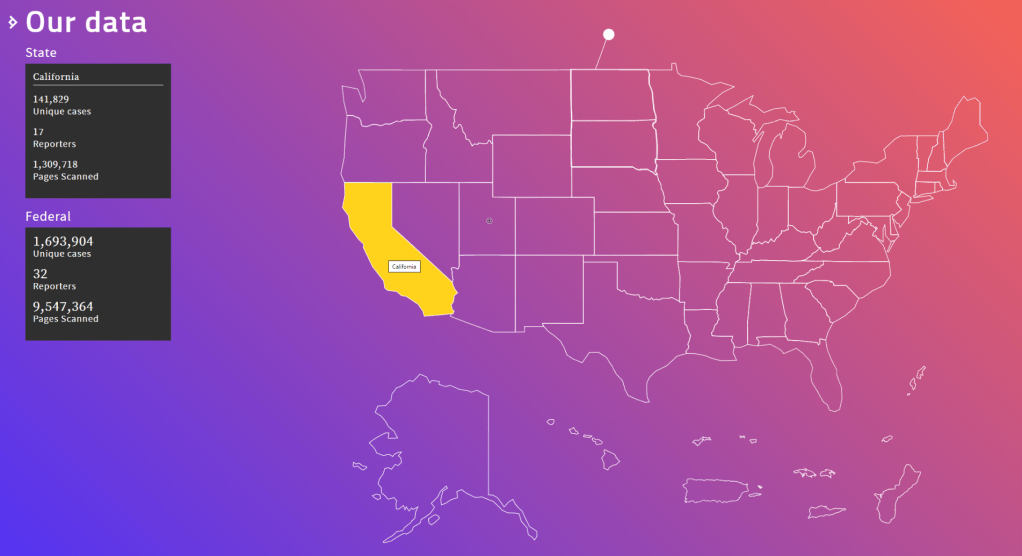
The Caselaw Access Project (“CAP”) expands public access to U.S. law. Our goal is to make all published U.S. court decisions freely available to the public online, in a consistent format, digitized from the collection of the Harvard Law Library.
The capstone of the Caselaw Access Project is a robust set of tools which facilitate access to the cases and their associated metadata. We currently offer five ways to access the data: API, bulk downloads, search, browse, and a historical trends viewer.
Our open-source API is the best option for anybody interested in programmatically accessing our metadata, full-text search, or individual cases.
If you need a large collection of cases, you will probably be best served by our bulk data downloads. Bulk downloads for Illinois and Arkansas are available without a login, and unlimited bulk files are available to research scholars.
Case metadata, such as the case name, citation, court, date, etc., is freely and openly accessible without limitation. Full case text can be freely viewed or downloaded but you must register for an account to do so, and currently you may view or download no more than 500 cases per day. In addition, research scholars can qualify for bulk data access by agreeing to certain use and redistribution restrictions. You can request a bulk access agreement by creating an account and then visiting your account page.
Access limitations on full text and bulk data are a component of Harvard’s collaboration agreement with Ravel Law, Inc. (now part of Lexis-Nexis). These limitations will end, at the latest, in March of 2024. In addition, these limitations apply only to cases from jurisdictions that continue to publish their official case law in print form. Once a jurisdiction transitions from print-first publishing to digital-first publishing, these limitations cease. Thus far, Illinois and Arkansas have made this important and positive shift and, as a result, all historical cases from these jurisdictions are freely available to the public without restriction. We hope many other jurisdictions will follow their example soon.
A different project altogether is helping the team behind Caselaw improve its data quality:
Our data inevitably includes countless errors as part of the digitization process. The public launch of this project is only the start of discovering errors, and we hope you will help us in finding and fixing them.
Some parts of our data are higher quality than others. Case metadata, such as the party names, docket number, citation, and date, has received human review. Case text and general head matter has been generated by machine OCR and has not received human review.
You can report errors of all kinds at our Github issue tracker, where you can also see currently known issues. We particularly welcome metadata corrections, feature requests, and suggestions for large-scale algorithmic changes. We are not currently able to process individual OCR corrections, but welcome general suggestions on the OCR correction process.
Many requests have come in regarding “training datasets” – to practice programming. Fortunately, the internet is full of open-source datasets! I compiled a selected list of datasets and repositories below. If you have any additions, please comment or contact me! For information on programming languages or algorithms, visit the overviews for R, Python, SQL, or Data Science, Machine Learning, & Statistics resources.
This list is no longer being maintained. There are other, more frequently updated repositories of useful datasets included in bold below: