I love how people are using data and data science to fight fake news these days (see also Identifying Dirty Twitter Bots), and I recently came across another great example.
Conspirador Norteño (real name unkown) is a member of what they call #TheResistance. It’s a group of data scientists discovering and analyzing so-called botnets – networks of artificial accounts on social media websites, like Twitter.
TheResistance uses quantitative analysis to unveil large groups of fake accounts, spreading potential fake news, or fake-endorsing the (fake) news spread by others.
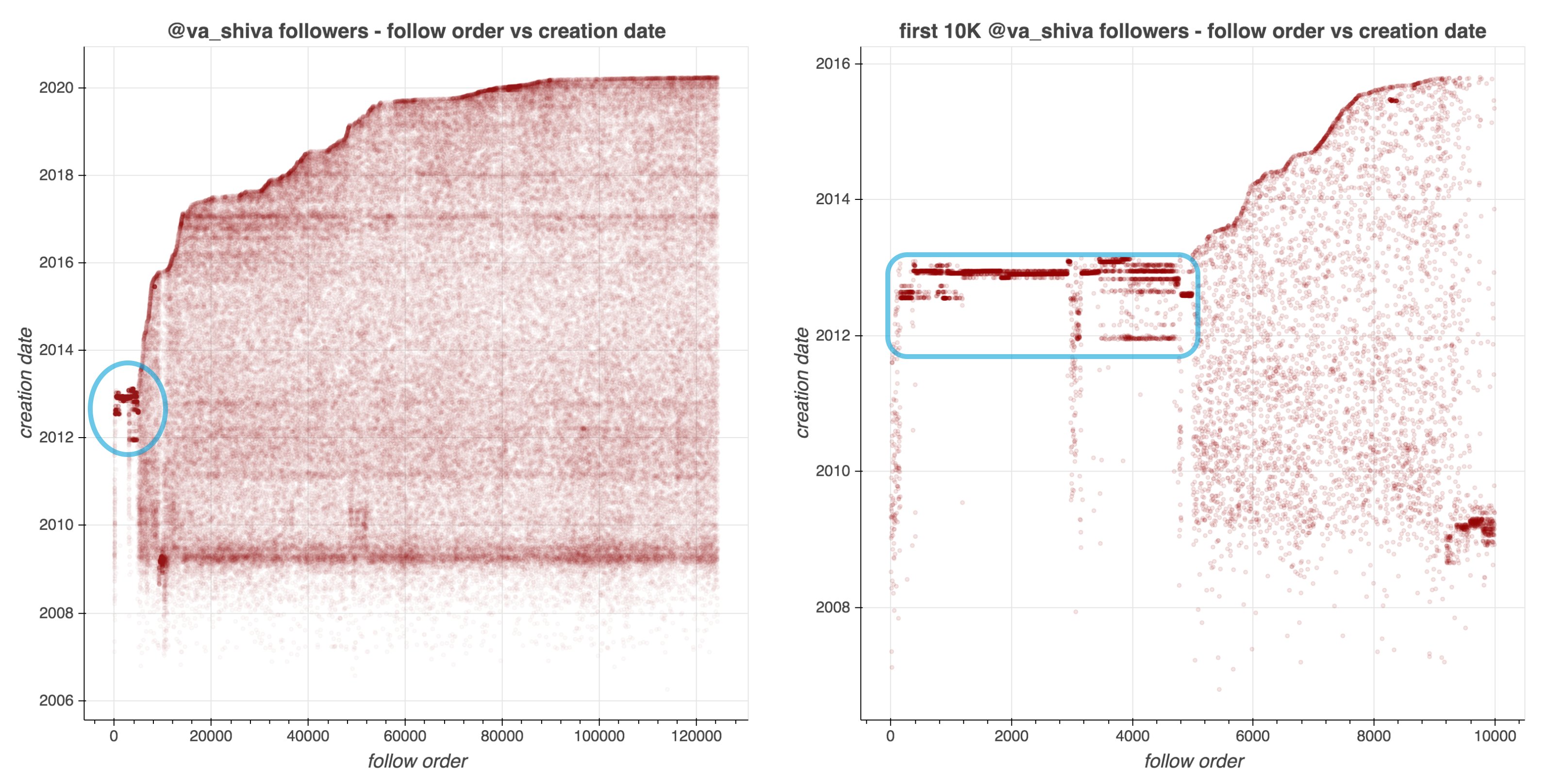
In a recent Twitter thread, Norteno shows how they discovered that many of Dr. Shiva Ayyadurai (self-proclaimed Inventor of Email) his early followers are likely bots.
They looked at the date of these accounts started following Shiva, offset by the date of their accounts’ creation. A remarkeable pattern appeared:
Although @va_shiva‘s recent followers look unremarkable, a significant majority of his first 5000 followers appear to have been created in batches and to have subsequently followed @va_shiva in rapid succession.
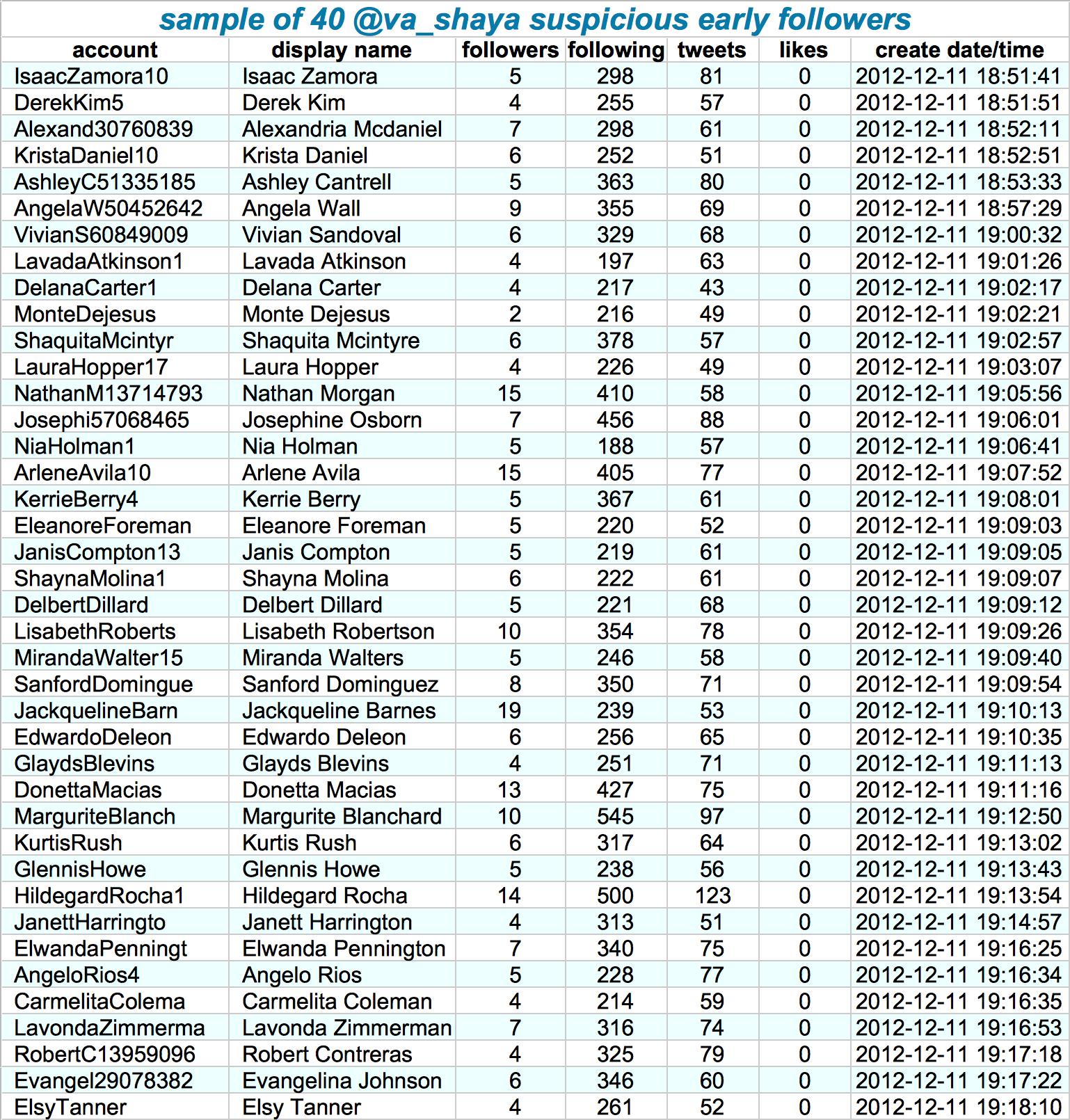
Looking at those followers in more detail, other suspicious patterns emerge. Their names follow a same pattern, they have an about equal amount of followers, followings, tweets, and (no) likes. Moreover, they were created only seconds apart. Many of them seem to follow each other as well.
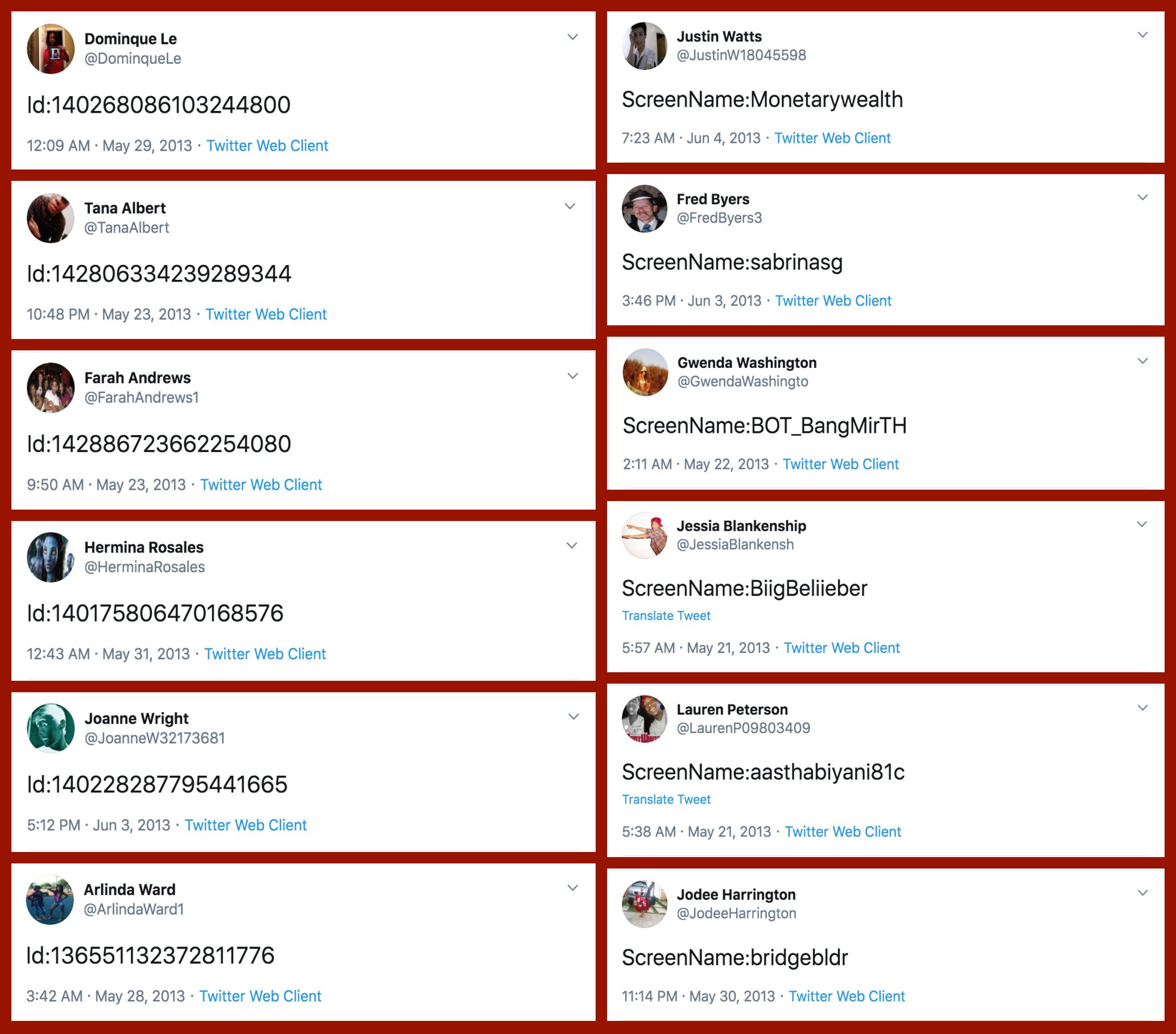
If that wasn’t enough proof of something’s off, here’s a variety of their tweets… Not really what everyday folks would tweet right? Plus similar patterns again across acounts.
At first, I thought, so what? This Shiva guy probably just set up some automated (Python?) scripts to make Twitter account and follow him. Good for him. It worked out, as his most recent 10k followers followed him organically.
However, it becomes more scary if you notice this Shiva guy is (succesfully) promoting the firing of people working for the government:
— Dr.SHIVA Ayyadurai, MIT PhD. Inventor of Email (@va_shiva) April 13, 2020
Anyways, wanted to share this simple though cool approach to finding bots & fake news networks on social media. I hope you liked it, and would love to hear your thoughts in the comments!
Over the course of last week, I built a Python program that scrapes quotes from Goodreads.com in a tidy format. For instance, these are the first three results my program returns when scraping for the tag robot:
Quote
author
source
likes
tags
Goodbye, Hari, my love. Remember always–all you did for me.
Isaac Asimov
Forward the Foundation
33
[‘asimov’, ‘foundation’, ‘human’, ‘robot’]
Unfortunately this Electric Monk had developed a fault, and had started to believe all kinds of things, more or less at random. It was even beginning to believe things they’d have difficulty believing in Salt Lake City.
As it’s bio reads, ArtificialStupidity is a highly sentient AI intelligently matching quotes and comics through state-of-the-art robotics, sophisticated machine learning, and blockchain technology.
Basically, every 15 minutes, a Python script is triggered on my computer (soon on my Raspberry Pi 4). Each time it triggers, this script generates a random number to determine whether it should post something. If so, the script subsequently generates another random number to determine what is should post: a quote, a comic, or both. Behind the scenes, some other functions add hastags and — voila — a tweet is born!
(An upcoming post will elaborate on the inner workings of my ArtificialStupidity Python script)
More often than not, ArtificialStupidity produces some random, boring tweet:
Now, in order to compile these tweets, my computer hosts two databases. One containing data- and tech- related comics; the other a variety of inspirational quotes. Each time the ArtificialStupidity bot posts a tweet, it draws from one or both of these datasets randomly. With, on average, one post every couple hours, I thus need several hundreds of items in these databases in order to prevent repetition — which is definitely not entertaining.
Up until last week, I manually expanded these databases every week or so. Adding new comics and quotes as I encountered them online. However, this proved a tedious task. Particularly for the quotes, as I set up the database in a specific format (“quote” – author). In contrast, websites like Goodreads.com display their quotes in a different format (e.g., “quote” ― author, source \n tags \n likes). Apart from the different format, the apostrophes and long slash also cause UTF-8 issues in my Python script. Hence, weekly reformatting of quotes proved an annoying task.
Up until this week!
While reformatting some bias-related quotes, I decided I’d rather invest 10 times more time developing my Python skills, than mindlessly reformatting quotes for a minute longer. So I started coding.
I am proud to say that, some six hours later, I have compiled the script below.
I’ll walk you through it’s functions.
So first, I import the modules/packages I need. Note that you will probably first have to pip install package-name on your own computer!
argparse for the command-line interface arguments
re for the regular expressions to clean quotes
bs4 for its BeautifulSoup for scraping website content
urllib.request for opening urls
csv to save csv files
os for directory pathing
import argparse
import re
from bs4 import BeautifulSoup
from urllib.request import urlopen, Request
import csv
import os
Next, I set up the argparse.ArgumentParser so that I can use my API using the command line. Now you can call the Python script using the command line (e.g., goodreads-scraper.py -t 'bias' -p 3 -q 80), and provide it with some arguments. No arguments are necessary. Most have sensible defaults. If you forget to provide a tag you will be prompted to provide one as the script runs (see later).
ap = argparse.ArgumentParser(description='Scrape quotes from Goodreads.com')
ap.add_argument("-t", "--tag",
required=False, type=str, default=None,
help="tag (topic/theme) of quotes to scrape")
ap.add_argument("-p", "--max_pages",
required=False, type=int, default=10,
help="maximum number of webpages to scrape")
ap.add_argument("-q", "--max_quotes",
required=False, type=int, default=100,
help="maximum number of quotes to scrape")
args = vars(ap.parse_args())
Now, the main function for this script is download_goodreads_quotes. This function contains many other functions within. You will see I set my functions up in a nested fashion, so that functions which are only used inside a certain scope, are instantiated there. In regular words, I create the functions where I use them.
First, download_goodreads_quotes creates download_quotes_from_page. In turn, download_quotes_from_page creates and calls compile_url — to create the url — get_soup — to download url contents — extract_quotes_elements_from_soup — to do just that — and extract_quote_dict. This latter function is the workhorse, as it takes each scraped quote element block of HTML and extracts the quote, author, source, and number of likes. It cleans each of these data points and returns them as a dictionary. In the end, download_quotes_from_page returns a list of dictionaries for every quote element block on a page.
Second, download_goodreads_quotes creates and calls download_all_pages which calls download_quotes_from_page for all pages up to max_pages, or up to the page that no longer returns quote data, or up to the number of max_quotes has been reached. All gathered quote dictionaries are added to a results list.
Additionally, I use two functions to actually store the scraped quotes: recreate_quote turns a quote dictionary into a quote (I actually do not use the source and likes, but maybe others want to do so); save_quotes calls this recreate quote for the list of quote dictionaires it’s given, and stores them in a csv file in the current directory.
Update 2020/04/05: added UTF-8 encoding based on infoguild‘s comment.
def recreate_quote(dict):
return f'"{dict.get("quote")}" - {dict.get("author")}'
def save_quotes(quote_data, tag):
save_path = os.path.join(os.getcwd(), 'scraped' + '-' + tag + '.txt')
print('saving file')
with open(save_path, 'w', encoding='utf-8') as f:
quotes = [recreate_quote(q) for q in quote_data]
for q in quotes:
f.write(q + '\n')
Finally, I need to call all these functions when the user runs this script via the command line. That’s what the following code does. If looks at the provided (default) arguments, and if no tag is provided, the user is prompted for one. Next Goodreads.com is scraped using the earlier specified download_goodreads_quotes function, and the results are saved to a csv file.
if __name__ == '__main__':
tag = args['tag'] if args['tag'] != None else input('Provide tag to search quotes for: ')
mp = args['max_pages']
mq = args['max_quotes']
result = download_goodreads_quotes(tag, max_pages=mp, max_quotes=mq)
save_quotes(result, tag)
Use
If you paste these script pieces sequentially in a Python script / text file, and save this file as goodreads-scraper.py. You can then run this script using your command line, like so goodreads-scraper.py -t 'bias' -p 3 -q 80 where the text after -t is the tag you are searching for, -p is the number of pages you want to scrape, and -q is the maximum number of quotes you want the program to scrape.
Let me know what your favorite quote is once you get it running!
To-do
So this is definitely still work in progress. Some potential improvements I want to integrate come directly to mind:
Avoid errors for quotes including newlines, or
Write code to extract only the text of the quote, instead of the whole text of the quote element.
Build in concurrency using futures (but take care that quotes are still added the results sequentially. Maybe we can already download the soups of all pages, as this takes the longest.
Write a function to return a random quote
Write a function to return a random quote within a tag
Implement a lower limit for the number of likes of quotes
Refactor the download_all_pages bit.
Add comments and docstrings.
Feedback or tips?
I have been programming in R for quite a while now, but Python and software development in general are still new to me. This will probably be visible in the way I program, my syntax, the functions I use, or other things. Please provide any feedback you may have as I’d love to get better!
Fortunately, so much of the conference is shared on Twitter and media outlets that I still felt included. Here are some things that I liked and learned from, despite the Austin-Tilburg distance.
Garrick Aden-Buie made a fabulous Shiny app that allows you to review all #rstudioconf tweets during and since the conference. It even includes some random statistics about the tweets, and a page with all the shared media.
Data scientists can fail by: ❌not saying no enough ❌not providing anything more than a cursory analysis ❌assuming PM knows enough to ask question in the right way and not collaborating with them ❌caring more about using fancy method than solving business problems#rstudioconf
Did you know that RStudio also posts all the webinars they host? There really are some hidden pearls among them. For instance, this presentation by Nathan Stephens on rendering rmarkdown to powerpoint will save me tons of work, and those new to broom will also be astonished by this webinar by Alex Hayes.
Past week, I came across two programming initiatives to uncover Twitter bots and one attempt to identify fake Instagram accounts.
Mike Kearney developed the R package botornot which applies machine learning to estimate the probability that a Twitter user is a bot. His default model is a gradient boosted model trained using both users-level (bio, location, number of followers and friends, etc.) and tweets-level information (number of hashtags, mentions, capital letters, etc.). This model is 93.53% accurate when classifying bots and 95.32% accurate when classifying non-bots. His faster model uses only the user-level data and is 91.78% accurate when classifying bots and 92.61% accurate when classifying non-bots. Unfortunately, the models did not classify my account correctly (see below), but you should definitely test yourself and your friends via this Shiny application.
Fun fact: botornot can be integrated with Mike’s rtweet package
Scraping Dirty Bots
At around the same time, I read this very interesting blog by Andy Patel. Annoyed by the fake Twitter accounts that kept liking and sharing his tweets, Andy wrote a Python script called pronbot_search. It’s an iterative search algorithm which Andy seeded with the dozen fake Twitter accounts that he identified originally. Subsequently, the program iterated over the friends and followers of each of these fake users, looking for other accounts displaying similar traits (e.g., similar description, including an URL to a sex-website called “Dirty Tinder”).
Whenever a new account was discovered, it was added to the query list, and the process continued. Because of the Twitter API restrictions, the whole crawling process took literal days before Andy manually terminated it. The results are just amazing:
After a day, the results looked like so. Notice the weird clusters of relationships in this network. [original]The full bot network uncovered by Andy included 22.000 fake Twitter accounts:
At the end of the weekend of March 10th, Andy had to stop the scraper after running for several days even though he had only processed 18% of the networks of the 22.000 included Twitter bots [original]The bot network on Twitter is probably enormous! Zooming in on the network, Andy notes that:
Pretty much the same pattern I’d seen after one day of crawling still existed after one week. Just a few of the clusters weren’t “flower” shaped.
Zoomed in to a specific part of the network you can see the separate clusters of bots doing little more than liking each others messages. [original]In his blog, Andy continues to look at all kind of data on these fake accounts. I found most striking that many of these account are years and years old already. Potentially, Twitter can use Mike Kearney’s botornot application to spot and remove them!
Most of the bots in the Dirty Tinder network found by Andy Patel were 3 to 8 years old already. [original]Andy was nice enough to share the data on these bot accounts here, for you to play with. His Python code is stored in the same github repo and more details around this project you can read in his original blog.
Fake Instagram Accounts
Finally, SRFdata (Timo Grossenbacher) attempted to uncover fake Instagram followers among the 7 million followers in the network of 115 important Swiss Instagram influencers in R. Magi Metrics was used to retrieve information for public Instagram accounts and rvest for private accounts. Next, clear fake accounts (e.g., little followers, following many, no posts, no profile picture, numbers in name) were labelled manually, and approximately 10% of the inspected 1000 accounts appeared fake. Finally, they trained a random forest model to classify fake accounts with a sensitivity (true negative) rate of 77.4% and an overall accuracy of around 94%.
The field of computer vision tries to replicate our human visual capabilities, allowing computers to perceive their environment in a same way as you and I do. The recent breakthroughs in this field are super exciting and I couldn’t but share them with you.
In the TED talk below by Joseph Redmon (PhD at the University of Washington) showcases the latest progressions in computer vision resulting, among others, from his open-source research on Darknet – neural network applications in C. Most impressive is the insane speed with which contemporary algorithms are able to classify objects. Joseph demonstrates this by detecting all kinds of random stuff practically in real-time on his phone! Moreover, you’ve got to love how well the system works: even the ties worn in the audience are classified correctly!
The second talk, below, is more scientific and maybe even a bit dry at the start. Blaise Aguera y Arcas (engineer at Google) starts with a historic overview brain research but, fortunately, this serves a cause, as ~6 minutes in Blaise provides one of the best explanations I have yet heard of how a neural network processes images and learns to perceive and classify the underlying patterns. Blaise continues with a similarly great explanation of how this process can be reversed to generate weird, Asher-like images, one could consider creative art:
An example of a reversed neural network thus “estimating” an image of a bird [via Youtube]Blaise’s colleagues at Google took this a step further and used t-SNE to visualize the continuous space of animal concepts as perceived by their neural network, here a zoomed in part on the Armadillo part of the map, apparently closely located to fish, salamanders, and monkeys?
A zoomed view of part of a t-SNE map of latent animal concepts generated by reversing a neural network [via Youtube]We’ve seen these latent spaces/continua before. This example Andrej Karpathy shared immediately comes to mind:
If you want to learn more about this process of image synthesis through deep learning, I can recommend the scientific papers discussed by one of my favorite Youtube-channels, Two-Minute Papers. Karoly’s videos, such as the ones below, discuss many of the latest developments:
Let me know if you have any other video’s, papers, or materials you think are worthwhile!
rstudio::conf is theyearly conference when it comes to R programming and RStudio. In 2017, nearly 500 people attended and, last week, 1100 people went to the 2018 edition. Regretfully, I was on holiday in Cardiff and missed out on meeting all my #rstats hero’s. Just browsing through the #rstudioconf Twitter-feed, I already learned so many new things that I decided to dedicate a page to it!
Fortunately, you can watch the live streams taped during the conference:
One of the workshops deserves an honorable mention. Jenny Bryan presented on What they forgot to teach you about R, providing some excellent advice on reproducible workflows. It elaborates on her earlier blog on project-oriented workflows, which you should read if you haven’t yet. Some best pRactices Jenny suggests:
Restart R often. This ensures your code is still working as intended. Use Shift-CMD-F10 to do so quickly in RStudio.
Use stable instead of absolute paths. This allows you to (1) better manage your imports/exports and folders, and (2) allows you to move/share your folders without the code breaking. For instance, here::here("data","raw-data.csv") loads the raw-data.csv-file from the data folder in your project directory. If you are not using the here package yet, you are honestly missing out! Alternatively you can use fs::path_home(). normalizePath() will make paths work on both windows and mac. You can usebasename instead of strsplit to get name of file from a path.
To upload an existing git directory to GitHub easily, you can usethis::use_github().
If you include the below YAML header in your .R file, you can easily generate .md files for you github repo.
#' ---
#' output: github_document
#' ---
Moreover, Jenny proposed these useful default settings for knitr:
Another of Jenny Bryan‘s talks was named Data Rectangling and although you might not get much out of her slides without her presenting them, you should definitely try the associated repurrrsivetutorial if you haven’t done so yet. It’s a poweR up for any useR!
I can’t remember who shared it, but a very cool trick is to name the viewing tab of any dataframe you pipe into View() using df %>% View("enter_view_tab_name").
These probably only present a minimal portion of the thousands of tips and tricks you could have learned by simply attending rstudio::conf. I will definitely try to attend next year’s edition. Nevertheless, I hope the above has been useful. If I missed out on any tips, presentations, tweets, or other materials, please reply below, tweet me or pop me a message!