The associated GitHub repository with R code.
Past weekend, I visited the casino with some friends. Of all games, we enjoy North-American-style Baccarat the most. This type of Baccarat is often called Punto Banco. In short, Punto Banco is a card game in which two hands compete: the “player” and the “banker“. During each coup (a round of play), both hands get dealt either 2 or 3 cards, depending on a complex drawing schema, and all cards have a certain value. Put simply, the hand with the highest total value of cards wins the coup, after which a new one starts. Before each coup, gamblers may bet which of the hands will win. Neither hand is in any way associated with the actual house or player/gambler, so bets may be placed on both. All in all, three different bets can be placed in a game of Punto Banco:
- The player hand has the highest total value, in which case the player wins (Punto);
- The banker hand has the highest total value, in which case the banker wins (Banco);
- The player and banker hands have equal total value, in which case there is a tie (Egalité).
If a gambler correctly bets either Punto or Banco, their bets get a 100% payoff. However, a house tax will often be applied to Banco wins. For instance, Banco wins may only pay off 95% or specific Banco wins (e.g., total card value of 5) may pay off less (e.g., 50%). Depending on house rules, a correct bet on a tie (Egalité) will pay off either 800% or 900%. A wrong bet on Punto or Banco stands in case Egalité is dealt. In all other cases of wrong bets, the house takes the money.

My friends and I like Punto Banco because it is completely random but seems “gameable”. Punto Banco is played with six or eight decks so there is no way to know which cards will be next. Moreover, the card-drawing rules are quite complex, so you never really know what’s going to happen. Sometimes both Punto and Banco get only two cards, at other times, the hand you bet on will get its third card, which might just turn things around. Punto Banco’s perceived gameability comes through our human fallacies to see patterns in randomness. Often, casino’s will place a monitor with the last fifty-so results (see below) to tempt gamblers to (erroneously) spot and bet on patterns. Alternatively, you might think it’s smart to bet against the table (play Punto when everybody else goes for Banco) or play on whatever bet won last hand. As the hands are dealt quite quickly in succession, and the minimal bet is often 10+ euro/dollar, Punto Banco is a quick way to find out how lucky you are.

So back to last weekend’s trip to the casino. Unfortunately, my friends and I lost quite some money at the Punto Banco table. We know the house has an edge (though smaller than in other games) but normally we are quite lucky. We often discuss what would be good strategies to minimize this houses’ edge. Obviously, you want to play as few games as possible, but that’s as far as we got in terms of strategy. Normally, we just test our luck and randomly bet Punto or Banco, and sparsely on Egalité.
As a statistical programmer, I thought it might be interesting to simulate the game and its odds from the bottom up. On the one hand, I wanted to get a sense of how favorable the odds are to the house. On the other hand, I was curious as to what extent strategies may be more or less successful in retaining at least some of your hard-earned cash.
In my simulations, I follow the Holland Casino Punto Banco rules, meaning a six-deck shoe and a Banco win with 5 pays out 50%. I did adopt the more lenient 9-1 payoff for Egalité though. Several hours of programming and some million simulated Baccarat hands later, here are the results:
- Do not play Baccarat / Punto Banco if you do not want to lose your money. Obviously, it’s best to not set foot in the casino if you can’t afford to lose some money. However, I eagerly pay for the entertainment value I get from it.
- You lose least if you stick to Banco. Despite having only a 50% payoff when Banco wins with 5, the odds are best for Banco due to the drawing rules. Indeed, according to the Wizard of Odds, the house edge for Banco (1.06%) is slightly lower than that of Punto (1.24%).
- Whatever you do, do not bet on Egalité. Because most casino’s pay out 8 to 1 in case of a correctly predicted tie, betting on one seems about the worst gambling strategy out there. With a house edge of over 14%, you are better off playing most other games (Wizard of Odds). Although casino’s paying out a tie 9 to 1 decrease the house edge to just below 5%, this is still way worse than playing either Punto or Banco.
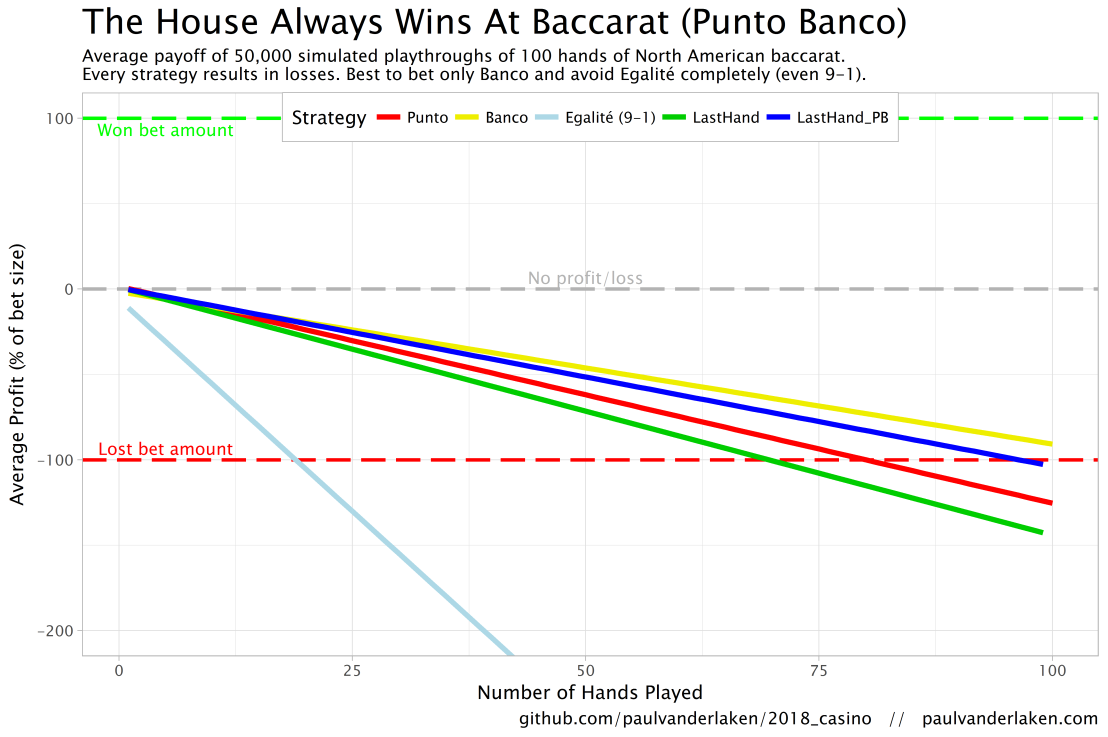
The figure below shows the results of the five strategies I tested using 50,000 simulations of 100 consecutive hands. Based on the results, I was reluctant to develop and test other strategies as results look quite straightforward: play Banco. Additionally, Wikipedia cites Thorp (1984, original reference unknown) who suggested that there are no strategies that will really result in any significant player advantage, except maybe for the endgame of a deck, which presumably requires a lot of card counting. If you nevertheless want to test other strategies, please be my guest, here are my five:
- Punto: Always bet on Punto.
- Banco: Always bet on Banco.
- Egalité: Always bet on Egalité.
- LastHand: Bet on the outcome of the last hand/coup.
- LastHand_PB: Bet on the outcome of the last hand/coup, only if this was Punto or Banco.
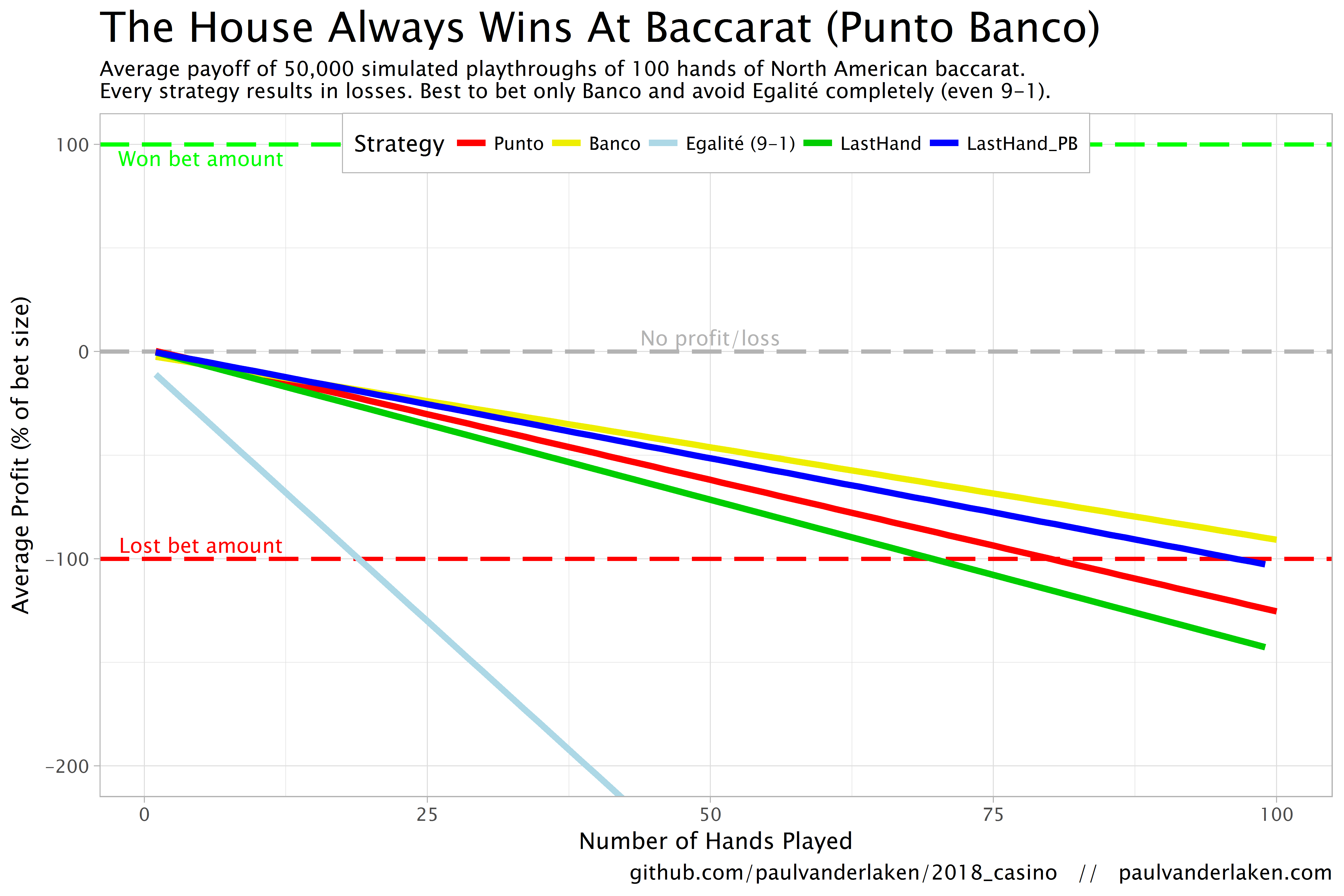
The above figure depicts the expected value of each strategy over a series of consecutive hands played. Clearly, the payoff is quite linear, independent of your strategy. The more hands you play, the more you lose. However, also clear is that some strategies outperform others. After 100 hands of Baccarat, playing only Banco will on average result in a total loss below the amount you wager. For example, if you bet 10 euro every hand, you will have a loss of about 9 euro’s after 100 rounds, on average. This is in line with the ~1% house edge reported by the Wizard of Odds. Similarly, betting only Punto will result in a loss of about 130% of the bet amount, which is also conform the ~1.4% house edge reported by the Wizard of Odds. Betting on Punto or Banco based on whichever won last (LastHand_PB) performs somewhere in between these two strategies, losing just over 100% of the bet amount in 100 hands. Your expected losses increase when you just bet on whichever outcome came last, including Egalité, resulting in around ~-150% after 100 hands. This is mainly because betting on Egalité, which seems about the worst strategy ever, will result in a remarkable 493.9% loss after 100 hands.
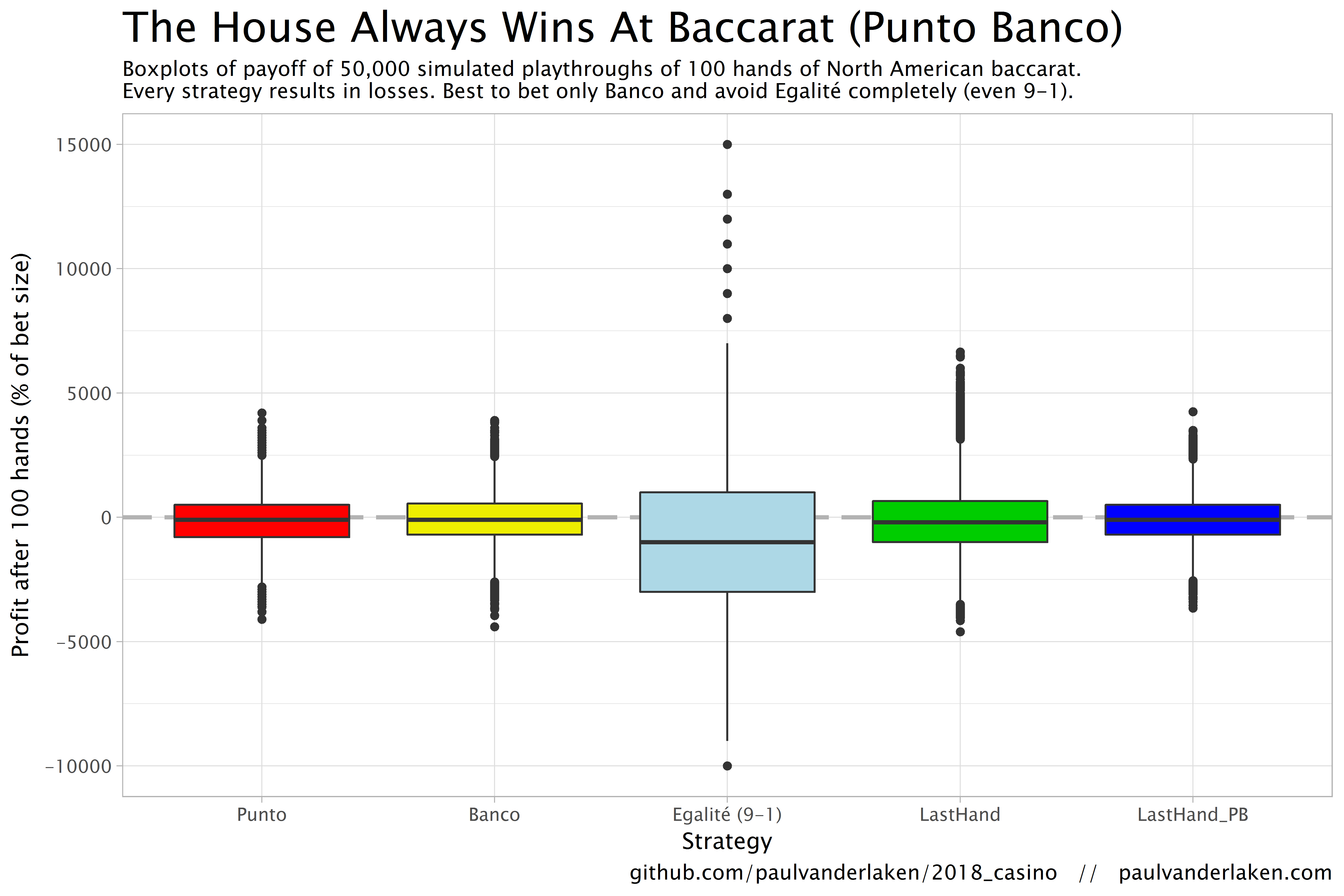
Apart from these average or expected values, I was also interested in the spread of outcomes of our thousands of simulations. Particularly because gamblers on a lucky streak may win much more when betting on Egalité, as the payoff is larger (8-1 or 9-1). The figure below shows that any strategy including Egalité will indeed result in a wider spread of outcomes. Betting on Egalité may thus be a good strategy if you are by some miracle divinely lucky, have information on which cards are coming next, or have an agreement with the dealer (disclaimer: this is a joke, please do not ever bet on Egalité with the intention of making money or try to cheat at the casino).
If you want to know how I programmed these simulations, please visit the associated github repository or reach out. I intend on simulating the payoff for various other casino games in the near future (first up: BlackJack), so if you are interested keep an eye on my website or twitter.