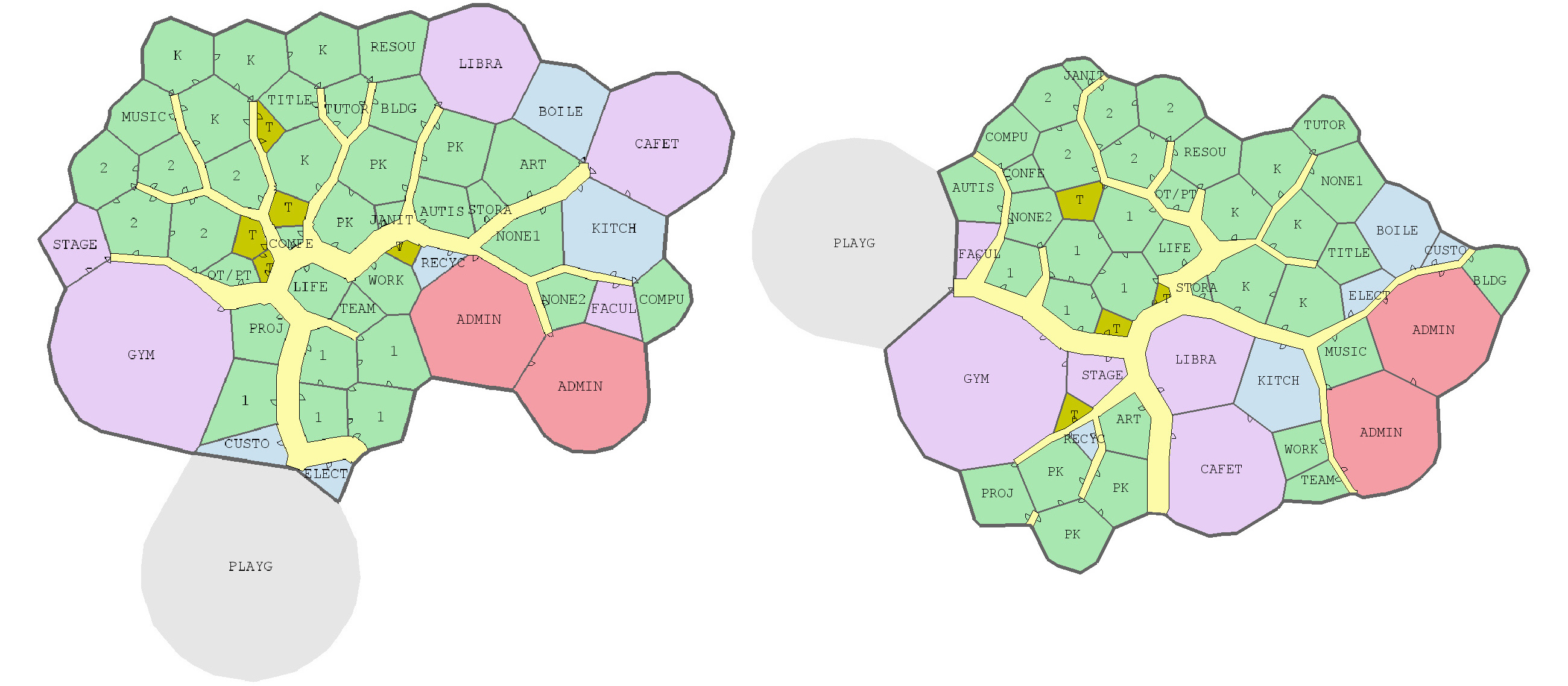
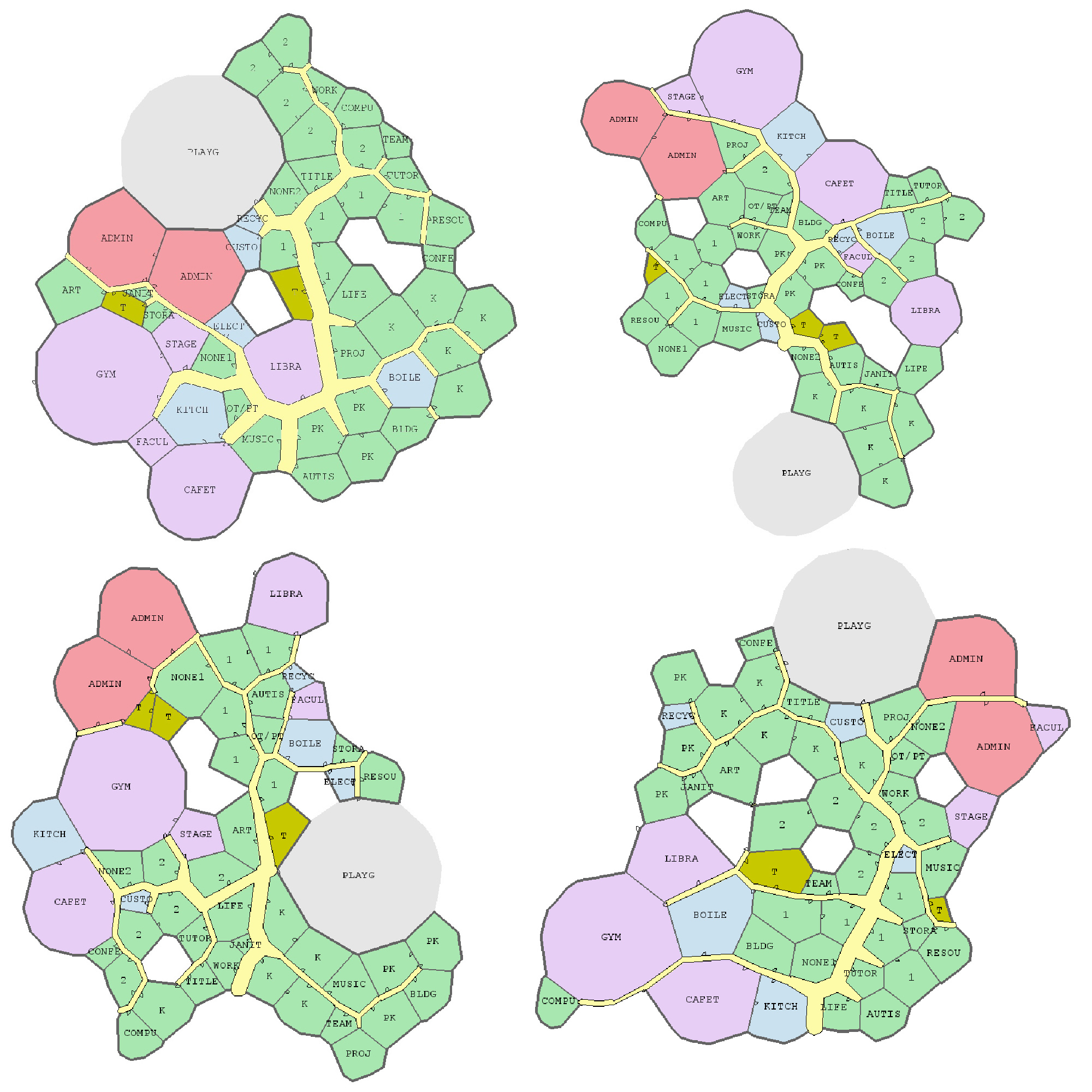
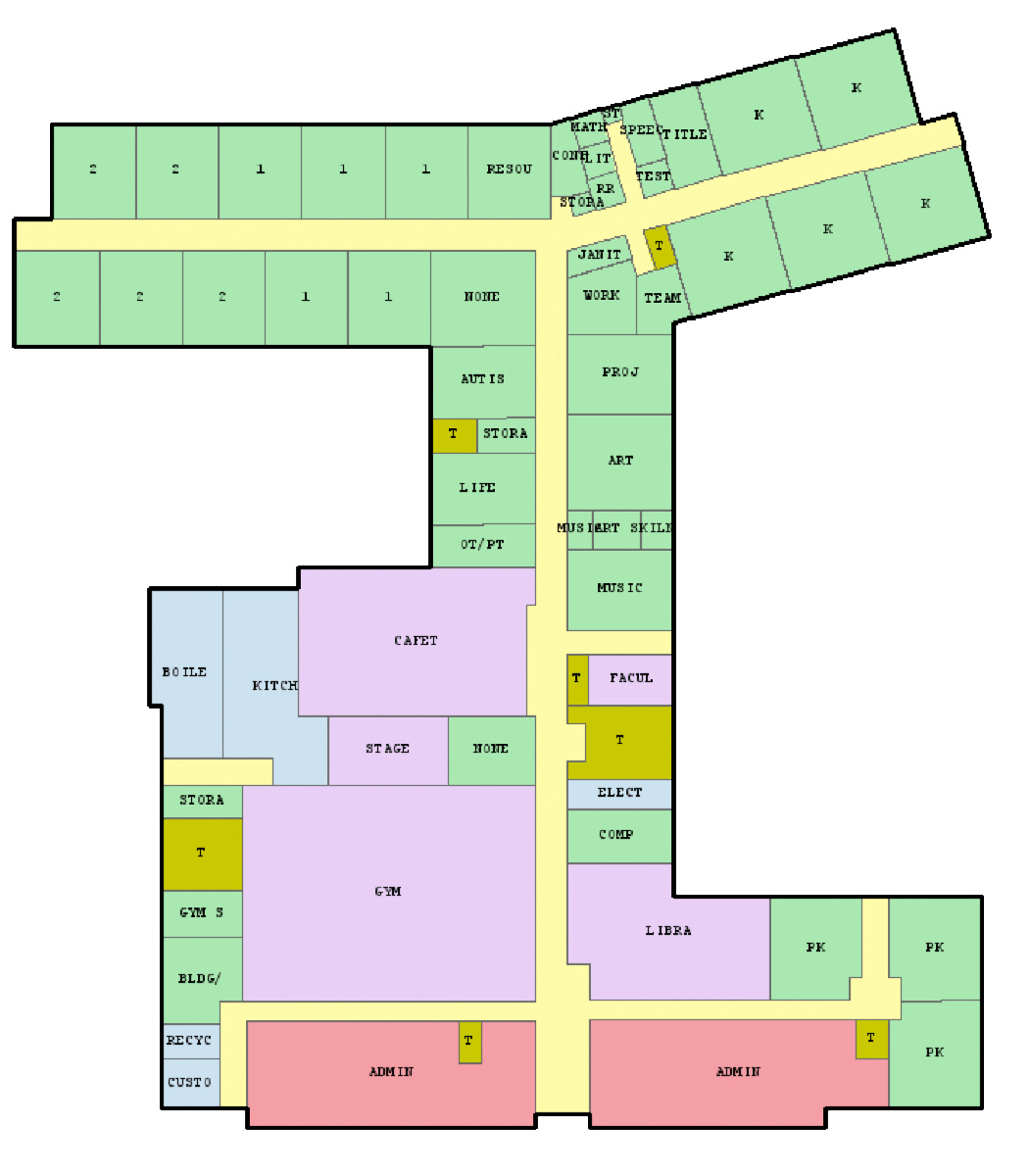
Joel Simon is the genius behind an experimental project exploring optimized school blueprints. Joel used graph-contraction and ant-colony pathing algorithms as growth processes, which could generate elementary school designs optimized for all kinds of characteristics: walking time, hallway usage, outdoor views, and escape routes just to name a few.
Two generated designs, minimizing the traffic flow (left) as well as escape routes (right) [original]Other designs tried to maximize the number of windows, resulting in seemingly random open courtyards [original]
The original floor plan [original]Definitely check out the original write-up if you are interested in the details behind the generation process! Or have a look at some of Joel’s other projects.
In optimizing their transportation services, Uber uses evolutionary strategies and genetic algorithms to train deep neural networks through reinforcement learning. A lot of difficult words in one sentence; you can imagine the complexity of the process.
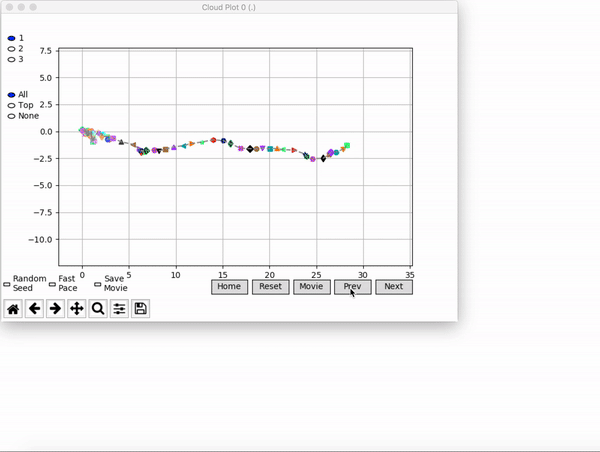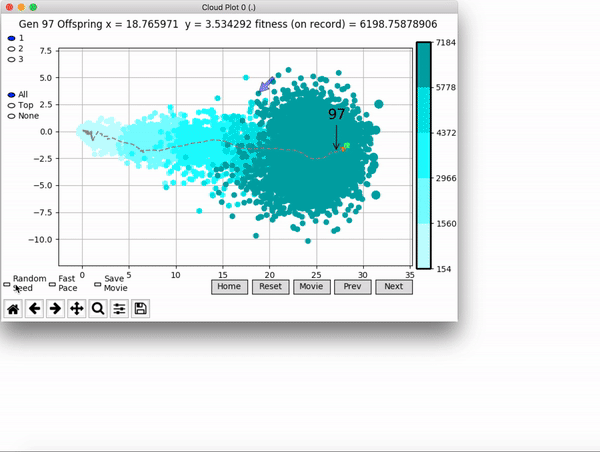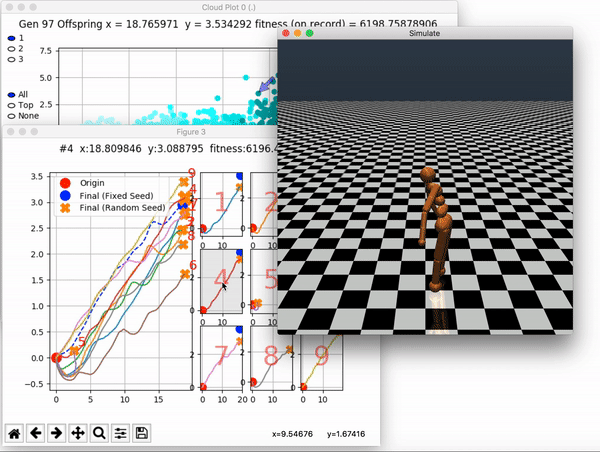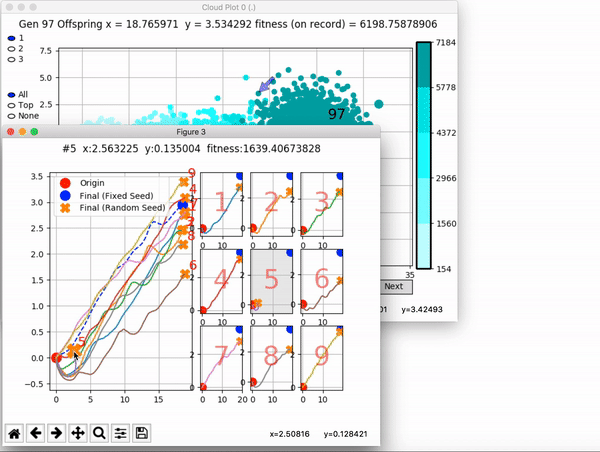
Because it is particularly difficult to observe the underlying dynamics of this learning process in neural network optimization, Uber built VINE – a Visual Inspector for NeuroEvolution. VINE helps to discover how evolutionary strategies and genetic optimizing are performing under the hood. In a recent article, they demonstrate how VINE works on the MujocoHumanoid Locomotion task.
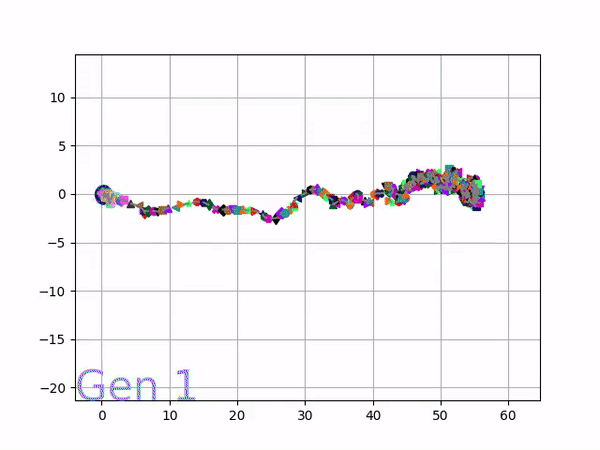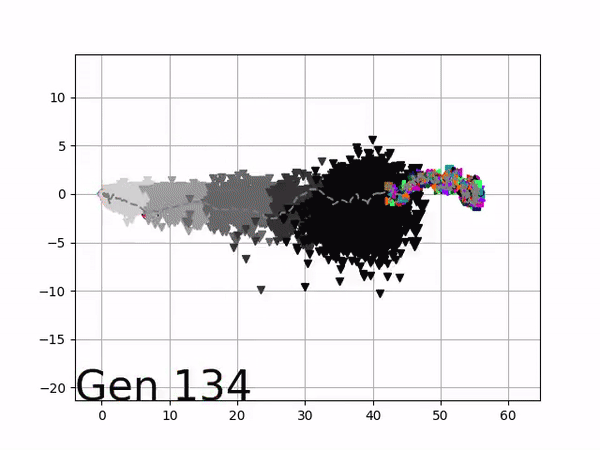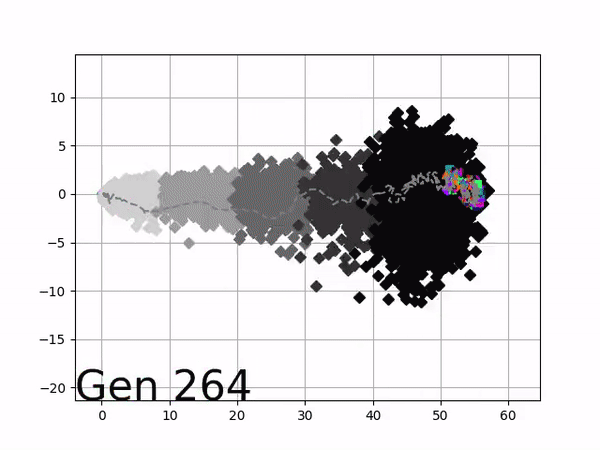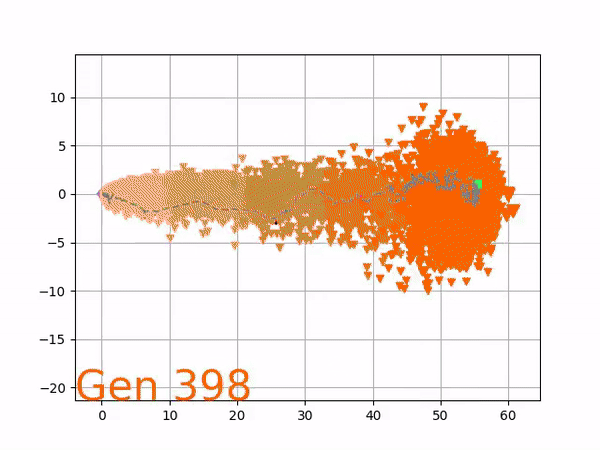
[…] In the Humanoid Locomotion Task, each pseudo-offspring neural network controls the movement of a robot, and earns a score, called its fitness, based on how well it walks. [Evolutionary principles] construct the next parent by aggregating the parameters of pseudo-offspring based on these fitness scores […]. The cycle then repeats.
VINE plots parent neural networks and their pseudo-offspring according to their performance. Users can then interact with these plots to:
visualize parents, top performance, and/or the entire pseudo-offspring cloud of any generation,
compare between and within generation performance,
and zoom in on any pseudo-offspring (points) in the plot to display performance information.
The GIFs below demonstrate what VINE is capable of displaying:
The evolution of performance over generations. The color changes in each generation. Within a generation, the color intensity of each pseudo-offspring is based on the percentile of its fitness score in that generation (aggregated into five bins). [original]Vine allows user to deep dive into each single generation, comparing generations and each pseudo-offspring within them [original]VINE can be found at this link. It is lightweight, portable, and implemented in Python.
Seth Bling calls himself a video game designer, a hacker and an engineer. You might know him from MarI/O: his neural network that got extremely good to at playing Super Mario Bros. The video below shows the genetic approach Seth used to train this neural network. Seth randomly generated a starting population of neural networks where the inputs – the current frame in the Mario video game – were randomly connected to the outputs – the eight buttons to press (jump, duck, up, down, right, left, etc). By giving the neural nets that made it furthest into the game a larger chance to pass on their genes (their input-output relations) to the next generation with slight mutations, Seth automatically generated neural networks that were more and more proficient in completing the game. In short, by evolution, Seth’s neural network learned the most effective response to the changing video game environment.
After MarI/O, Seth this week posted his newest creation: MariFlow. Here, Seth trained a neural network on 15 hours of training data, consisting of Seth himself playing Super Mario Kart. The neural network thus learned what buttons (output) Seth would most likely push when he encountered a certain Mario Kart parcours piece (input). However, due to random chance, the neural net would often get itself stuck in situations that Seth had not encountered in his training sessions (e.g., reversed, against a wall). The neural net would fail miserably in such situations because it had not learned how to behave. Accordingly, Seth had to generate new training data for these situations and he did so using Human-Computer Interactions in Machine Learning: Seth and the neural net would play alternatively for a while, thus generating training data for situations that Seth would not have encountered on its own. After the neural net was trained with these additional data, it became quite proficient in playing Mario Kart (like Seth) often even winning matches! If you want to know more, you can read the manual here or watch Seth’s video below. If you want to replicate or just play with the data, Seth made everything available here.
Seth has active YouTube, Twitch and Twitter channels and I recommend you check them out!