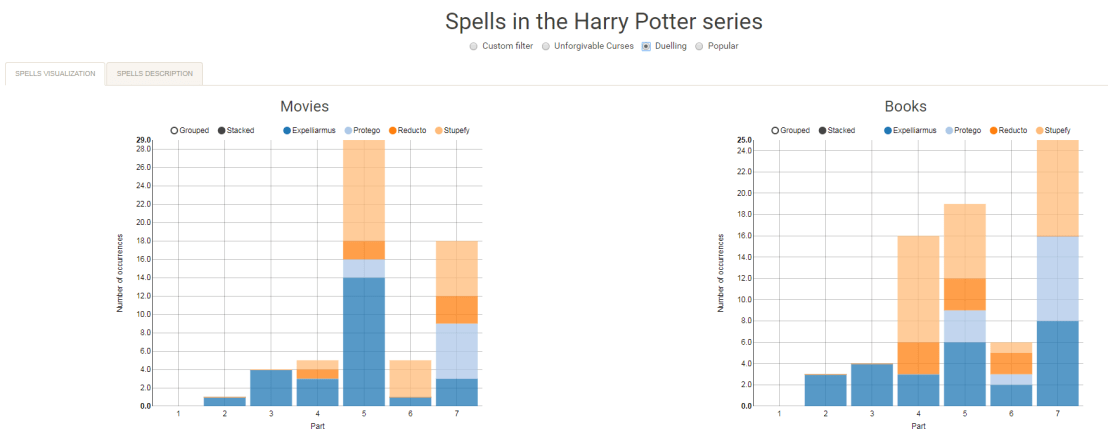
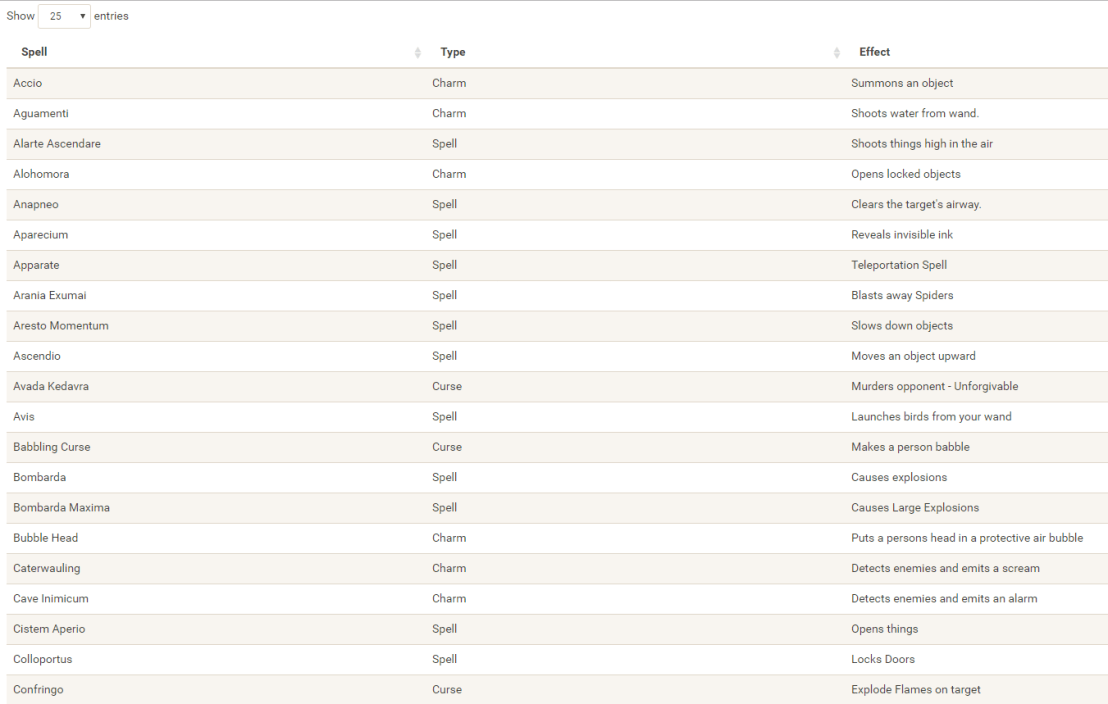
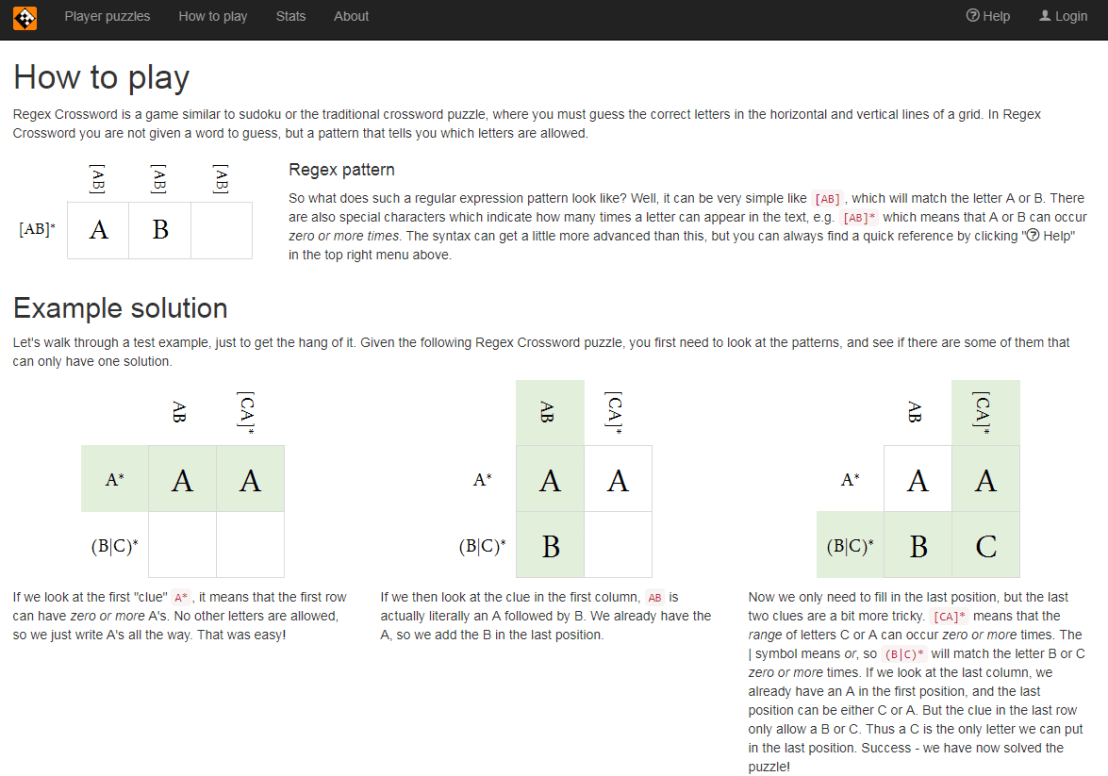
R users have been using the twitter package by Geoff Jentry to mine tweets for several years now. However, a recent blog suggests a novel package provides a better mining tool: rtweet by Michael Kearney (GitHub).
Both packages use a similar setup and require you to do some prep-work by creating a Twitter “app” (see the package instructions). However, rtweet will save you considerable API-time and post-API munging time. This is demonstrated by the examples below, where Twitter is searched for #rstats-tagged tweets, first using twitteR, then using rtweet.
The above operations required only several seconds to completely. The returned data is definitely usable, but not in the most handy format: the package models the Twitter API on to custom R objects. It’s elegant, but also likely overkill for most operations. Here’s the rtweet version:
This operation took equal to less time but provides the data in a tidy, immediately usable structure.
On the rtweet website, you can read about the additional functionalities this new package provides. For instance,ts_plot() provides a quick visual of the frequency of tweets. It’s possible to aggregate by the minute, i.e., by = "mins", or by some value of seconds, e.g.,by = "15 secs".
## Plot time series of all tweets aggregated by second
ts_plot(rt, by = "secs")

ts_filter() creates a time series-like data structure, which consists of “time” (specific interval of time determined via the by argument), “freq” (the number of observations, or tweets, that fall within the corresponding interval of time), and “filter” (a label representing the filtering rule used to subset the data). If no filter is provided, the returned data object includes a “filter” variable, but all of the entries will be blank "", indicating that no filter filter was used. Otherwise, ts_filter() uses the regular expressions supplied to the filter argument as values for the filter variable. To make the filter labels pretty, users may also provide a character vector using the key parameter.
## plot multiple time series by first filtering the data using
## regular expressions on the tweet "text" variable
rt %>%
dplyr::group_by(screen_name) %>%
## The pipe operator allows you to combine this with ts_plot
## without things getting too messy.
ts_plot() +
ggplot2::labs(
title = "Tweets during election day for the 2016 U.S. election",
subtitle = "Tweets collected, parsed, and plotted using `rtweet`"
)
The developer cautions that these plots often resemble frowny faces: the first and last points appear significantly lower than the rest. This is caused by the first and last intervals of time to be artificially shrunken by connection and disconnection processes. To remedy this, users may specify trim = TRUE to drop the first and last observation for each time series.

Give rtweet a try and let me know whether you prefer it over twitter.