Those who have been following me for some time now will know that I am a big fan of generative art: art created through computers, mathematics, and algorithms.
Several years back, my now wife bought me my first piece for my promotion, by Marcus Volz.
Nicholas was hesistant to sell me a piece and insisted that this series was not finished yet.
Yet, I already found it wonderful and lovely to look at and after begging Nicholas to sell us one of his early pieces, I sent it over to ixxi to have it printed and hanged it on our wall above our dinner table.
If you’re interested in Nicholas’ work, have a look at c82.net
I really like generative art, or so-called algorithmic art. Basically, it means you take a pattern or a complex system of rules, and apply it to create something new following those patterns/rules.
When I finished my PhD, I got a beautiful poster of where the k-nearest neighbors algorithms was used to generate a set of connected points.
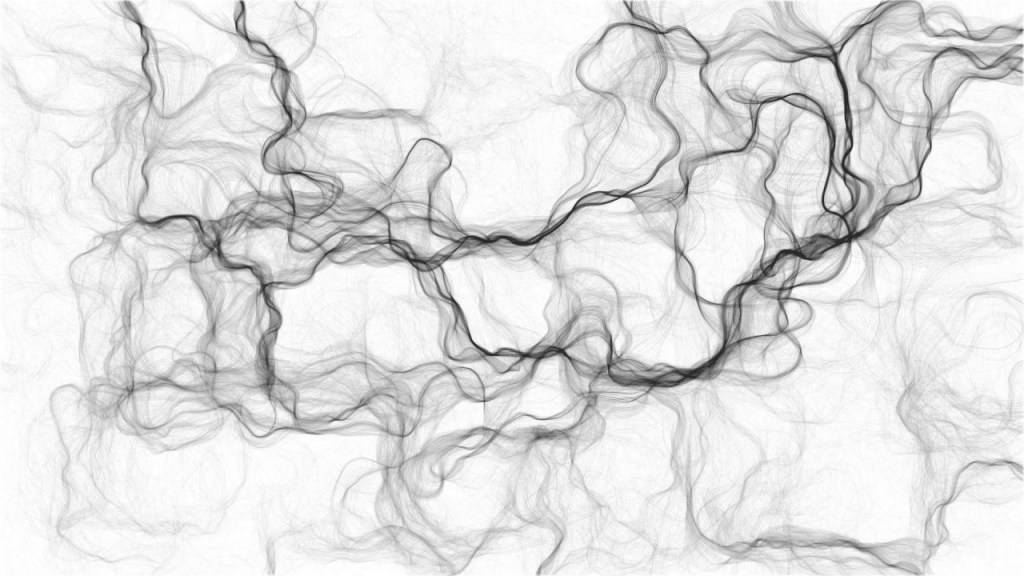
As we recently moved into our new house, I decided I wanted to have a brother for the knn-poster. So I did some research in algorithms I wanted to use to generate a painting. I found some very cool ones, of which I unforunately can’t recollect the artists anymore:
Note: these are NOT mine
However, I preferred to make one myself. So we again turned to the work of the author that made the knn-poster: Marcus Volz.
He has written (in R) many other algorithms. And we found that one specifically nicely matched the knn-poster. His metropolis – or generative city:
However, I wanted to make one myself, so I download Marcus code, and tweaked it a bit. Most importantly, I made it start in the center, made it fill up the whole space, and I made it run more efficient so I could generate a couple dozen large cities quickly, and pick the one I liked most. Here’s the end result:
JS13K Games is a competition where developers are challenged to create an entire game using less than 13 kilobytes of memory. Creative developer Matt Deslaudiers participated and created Bellwoods: an art game for mobile and desktop that you can play in your browser.
The concept of the game is simple: fly your kite through endless fields of colour and sound, trying to discover new worlds. To remain under 13kb, all of the graphics and audio in Bellwoods are procedurally generated. The game was mostly programmed in JavaScript with minimal custom HTML/CSS. Matt’s motivation and the actual development you can read about in his original blog. The source code the game, Matt also shared on GitHub.
Mélissa Hernandez, a French UX and Interaction Designer, helped Matt design this beautiful game. Together, they even versed a haiku that not only evokes the mood of the game, but also provides some subtle gameplay instructions:
over the tall grass following birds, chasing wind in search of color
Zack Nado wrote the best machine learning application I’ve seen so far: a neural network architecture that generates new Pusheen pictures.
This is an orginal Pusheen picture.
In his blog, Zack describes his generative adversarial network (GAN) , a special type of machine learning architecture where two neural networks try to fool each other. Zack first gave the discriminator network some real Pusheen images, so it gets an idea of what Pusheen looks like. Next, the generator network gets a bunch of random numbers so it can generate completely new (fake) images. These generated images are then fed back into the discriminator, so it knows what generated images look like. Zack repeated this process several hundred thousand times, so he obtained a generator network that’s great at making new Pusheen images which the discriminator (nearly) can’t dinstinguish from the original, real ones. Below is the learning process of the generator network visualized:
Samples output by the generator network. It learns distinctive features of “real” Pusheen (e.g., tail, eyes, ears) over time [original]
In the end, the generated images are very much like the real Pusheen. Zack added an interactive module (using Tensorflow.js) to the blog so you can generate some Pusheens yourself. (it didn’t work for me though…) On a final note, Zack wrote the orginal blog both in plain English, for non-experts, and in jargon, for the more experienced data scientists. I highly recommend you read either one of those versions!
Some of the Pusheen’s generated by Zack’s GAN [original]
The field of computer vision tries to replicate our human visual capabilities, allowing computers to perceive their environment in a same way as you and I do. The recent breakthroughs in this field are super exciting and I couldn’t but share them with you.
In the TED talk below by Joseph Redmon (PhD at the University of Washington) showcases the latest progressions in computer vision resulting, among others, from his open-source research on Darknet – neural network applications in C. Most impressive is the insane speed with which contemporary algorithms are able to classify objects. Joseph demonstrates this by detecting all kinds of random stuff practically in real-time on his phone! Moreover, you’ve got to love how well the system works: even the ties worn in the audience are classified correctly!
The second talk, below, is more scientific and maybe even a bit dry at the start. Blaise Aguera y Arcas (engineer at Google) starts with a historic overview brain research but, fortunately, this serves a cause, as ~6 minutes in Blaise provides one of the best explanations I have yet heard of how a neural network processes images and learns to perceive and classify the underlying patterns. Blaise continues with a similarly great explanation of how this process can be reversed to generate weird, Asher-like images, one could consider creative art:
An example of a reversed neural network thus “estimating” an image of a bird [via Youtube]Blaise’s colleagues at Google took this a step further and used t-SNE to visualize the continuous space of animal concepts as perceived by their neural network, here a zoomed in part on the Armadillo part of the map, apparently closely located to fish, salamanders, and monkeys?
A zoomed view of part of a t-SNE map of latent animal concepts generated by reversing a neural network [via Youtube]We’ve seen these latent spaces/continua before. This example Andrej Karpathy shared immediately comes to mind:
If you want to learn more about this process of image synthesis through deep learning, I can recommend the scientific papers discussed by one of my favorite Youtube-channels, Two-Minute Papers. Karoly’s videos, such as the ones below, discuss many of the latest developments:
Let me know if you have any other video’s, papers, or materials you think are worthwhile!
Seth Bling calls himself a video game designer, a hacker and an engineer. You might know him from MarI/O: his neural network that got extremely good to at playing Super Mario Bros. The video below shows the genetic approach Seth used to train this neural network. Seth randomly generated a starting population of neural networks where the inputs – the current frame in the Mario video game – were randomly connected to the outputs – the eight buttons to press (jump, duck, up, down, right, left, etc). By giving the neural nets that made it furthest into the game a larger chance to pass on their genes (their input-output relations) to the next generation with slight mutations, Seth automatically generated neural networks that were more and more proficient in completing the game. In short, by evolution, Seth’s neural network learned the most effective response to the changing video game environment.
After MarI/O, Seth this week posted his newest creation: MariFlow. Here, Seth trained a neural network on 15 hours of training data, consisting of Seth himself playing Super Mario Kart. The neural network thus learned what buttons (output) Seth would most likely push when he encountered a certain Mario Kart parcours piece (input). However, due to random chance, the neural net would often get itself stuck in situations that Seth had not encountered in his training sessions (e.g., reversed, against a wall). The neural net would fail miserably in such situations because it had not learned how to behave. Accordingly, Seth had to generate new training data for these situations and he did so using Human-Computer Interactions in Machine Learning: Seth and the neural net would play alternatively for a while, thus generating training data for situations that Seth would not have encountered on its own. After the neural net was trained with these additional data, it became quite proficient in playing Mario Kart (like Seth) often even winning matches! If you want to know more, you can read the manual here or watch Seth’s video below. If you want to replicate or just play with the data, Seth made everything available here.
Seth has active YouTube, Twitch and Twitter channels and I recommend you check them out!