Apparently, I was not the only geek who decided to celebrate the 20th anniversary of the Harry Potter saga with statistical analysis. Students Moritz Haine and Markus Dienstknecht of the Data Science for Decision Making Master at Maastricht University started their own celebratory project as part of a course Information Retrieval and Text Mining.
Students in previous years looked at for example Lord of the Rings, Star Wars and Game of Thrones. However, to our surprise, Harry Potter was missing. Since the books are about magic, we decided it would be interesting to identify all of the spells and the wizards that cast the most spells
Moritz Haine
From the books, the students extracted 41 different wizards, 64 different spells and 253 spells. Moritz points out that they could only include spoken spells, even though the most powerful wizards can also cast spells without naming them. They expect this might be the reason why Dumbledore and Voldemort are not ranked as high. At the end of their project, Moritz and Markus visualized their results in a spell-character mapping.
A network mapping of the characters and spells casted in the Harry Potter saga [original]This is the latest addition to my collection of Harry Potter analyses, to which a similar, interactive web application of spell usage was added only last week.
I would like to demonstrate how regular expressions can be used to retrieve (sub)strings that follow a specific format. We could use regex to examine, for instance, when, and by whom, which magical spells are cast.
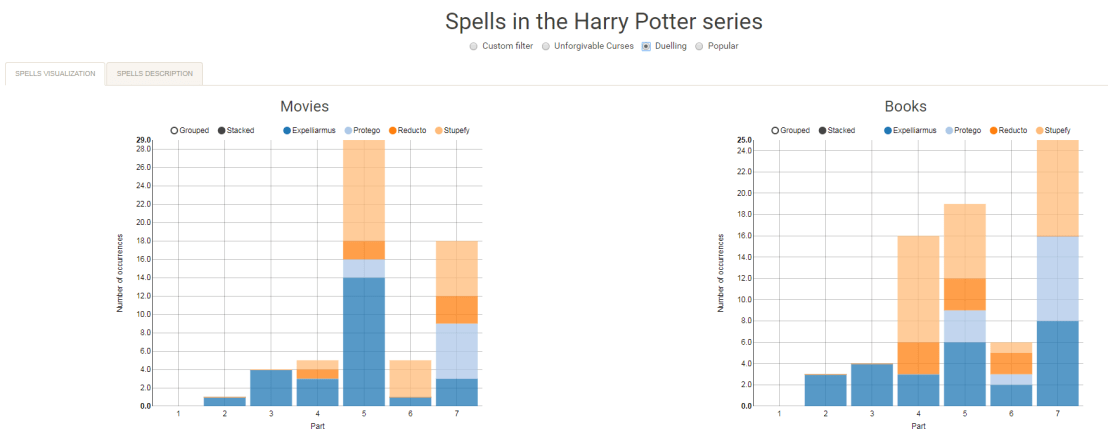
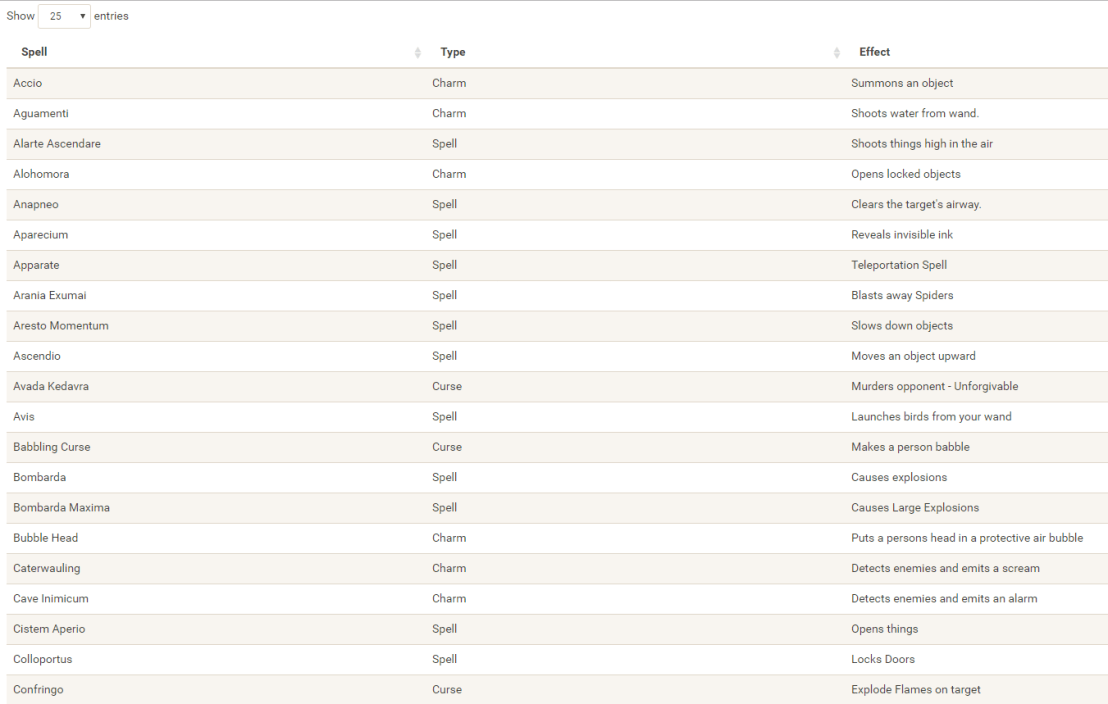
Well, Prusinowskik (real name unknown) beat me to it, and how! S/He formed a comprehensive list of all spells found in the Harry Potter saga (see below), and categorized these into “spells“, “charms“, and “curses“, and into “popular“, “dueling” and “unforgivable” purposes. Next, Prusinowskik built an interactive Shiny application with lovely JavaScript graphs (package: rCharts) for us to discover precisely when during the saga which spells are cast (see also below). Moreover, the analysis was repeated for both the books and the movies.
Truly excellent work Prusinowskik! The Shiny app can be found here.
A few weeks ago, Magic Sudoku was released for iOS11. This app by a company named Hatchlings automatically solves sudoku puzzles using a combination of Computer Vision, Machine Learning, and Augmented Reality. The app works on iPad Pro’s and iPhone 6s or above and can be downloaded from the App Store.
Magic Sudoku gives a magical experience when users point their phone at a Sudoku puzzle: the puzzle is instantaneously solved and displayed on their screen. In several seconds, the following occurs behind the scenes:
“One of the original reasons I chose a Sudoku solver as our first AR app was that I knew classifying digits is basically the “hello world” of Machine Learning. I wanted to dip my toe in the water of Machine Learning while working on a real-world problem. This seemed like a realistic app to tackle.” – Brad Dwyer, Founder at Hatchlings
Particularly the training process of the app interested me. In his blog, Brad explains how they bought out the entire stock of Sudoku books of a specific bookstore and, with the help of his team, ripped each book apart to scan each small square with a number and upload in to a server. In the end, this server contained about 600,000 images, but all were completely unlabeled. Via a simple game, they asked Hatchlings users to classify these images by pressing the number keys on their keyboard. Within 24 hours, all 600,000 images were classified!
Nevertheless, some users had misunderstood the task (or just plainly ignored it) and as a consequence there were still a significant number of misidentified images. So Brad created a second tool that displayed 100 images of a single class to users, who where consequently asked to click the ones that didn’t match. These were subsequently thrown back into the first tool to be reclassified.
Quickly, the developers had enough verified data to add an automatic accuracy checker into both tools for future data runs. Funnily enough, they programmed it in such a way that users were periodically shown already known/classified images in order to check the validity of their inputs and determine how much to trust their answers going forward. This whole process reminds me on a blog I wrote recently, regarding human-computer interactions in reinforcement learning.
For several more weeks, users classified more scanned data so that, by the time the app was launched, it had been trained on over a million images of Sudoku squares. The results were amazing as the application had a 98.6% accuracy on launch (currently above 99% accuracy). One minor deficit was that the app was trained on paper Sudoku’s. However, when it aired, many users wanted to quickly test it and searched for Sudoku images on Google, which the app wouldn’t process that well.
“Problem number one was that our machine learning model was only trained on paper puzzles; it didn’t know what to think about pixels on a screen. I pulled an all nighter that first week and re-trained our model with puzzles on computer screens.
Problem number two was that ARKit only supports horizontal planes like tables and floors (not vertical planes like computer monitors). Solving this was a trickier problem but I did come up with a hacky workaround. I used a combination of some heuristics and FeaturePoint detection to place puzzles on non-horizontal planes.” – Brad Dwyer, Founder at Hatchlings