
A/B testing is a method of comparing two versions of some thing against each other to determine which is better. A/B tests are often mentioned in e-commerce contexts, where the things we are comparing are web pages.
Business leaders and data scientists alike face a difficult trade-off when running A/B tests: How big should the A/B test be? Or in other words, After collecting how many data points, or running for how many days, should we make a decision whether A or B is the best way to go?
This is a tradeoff because the sample size of an A/B test determines its statistical power. This statistical power, in simple terms, determines the probability of a A/B test showing an effect if there is actually really an effect. In general, the more data you collect, the higher the odds of you finding the real effect and making the right decision.
By default, researchers often aim for 80% power, with a 5% significance cutoff. But is this general guideline really optimal for the tradeoff between costs and benefits in your specific business context? Chris thinks not.
Chris said wrote a great three-piece blog in which he explains how you can mathematically determine the optimal duration of A/B-testing in your own company setting:
Part I: General Overview. Starts with a mostly non-technical overview and ends with a section called “Three lessons for practitioners”.
Part II: Expected lift. A more technical section that quantifies the benefits of experimentation as a function of sample size.
Part III: Aggregate time-discounted lift. A more technical section that quantifies the costs of experimentation as a function of sample size. It then combines costs and benefits into a closed-form expression that can be optimized. Ends with an FAQ.
Chris Said (via)
Moreover, Chris provides three practical advices that show underline 80% statistical power is not always the best option:
- You should run “underpowered” experiments if you have a very high discount rate
- You should run “underpowered” experiments if you have a small user base
- Neverheless, it’s far better to run your experiment too long than too short
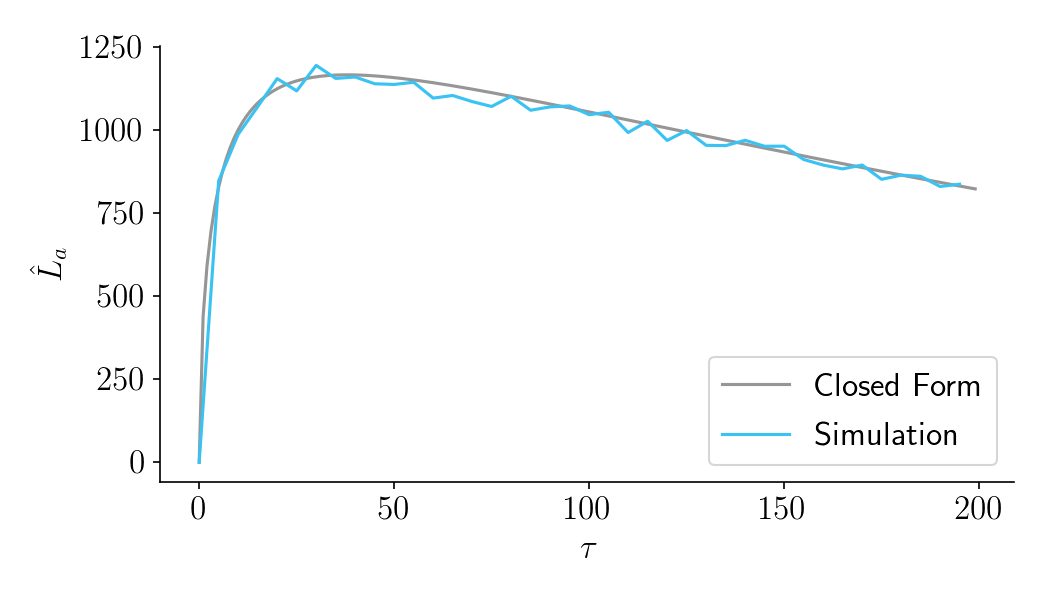
via chris-said.io/2020/01/10/optimizing-sample-sizes-in-ab-testing-part-I/
Chris ran all his simulations in Python and shared the notebooks.


 time to sort
time to sort  . Moreover, some algorithms are stable — in the sense that they always take the same amount of time to process
. Moreover, some algorithms are stable — in the sense that they always take the same amount of time to process 

