In Glad You Asked, Vox dives deep into timely questions around the impact of systemic racism on our communities and in our daily lives.
In this video, they look into the role of tech in societal discrimination. People assume that tech and data are neutral, and we have turned to tech as a way to replace biased human decision-making. But as data-driven systems become a bigger and bigger part of our lives, we see more and more cases where they fail. And, more importantly, that they don’t fail on everyone equally.
Why do we think tech is neutral? How do algorithms become biased? And how can we fix these algorithms before they cause harm? Find out in this mini-doc:
Those who have been following me for some time now will know that I am a big fan of generative art: art created through computers, mathematics, and algorithms.
Several years back, my now wife bought me my first piece for my promotion, by Marcus Volz.
Nicholas was hesistant to sell me a piece and insisted that this series was not finished yet.
Yet, I already found it wonderful and lovely to look at and after begging Nicholas to sell us one of his early pieces, I sent it over to ixxi to have it printed and hanged it on our wall above our dinner table.
If you’re interested in Nicholas’ work, have a look at c82.net
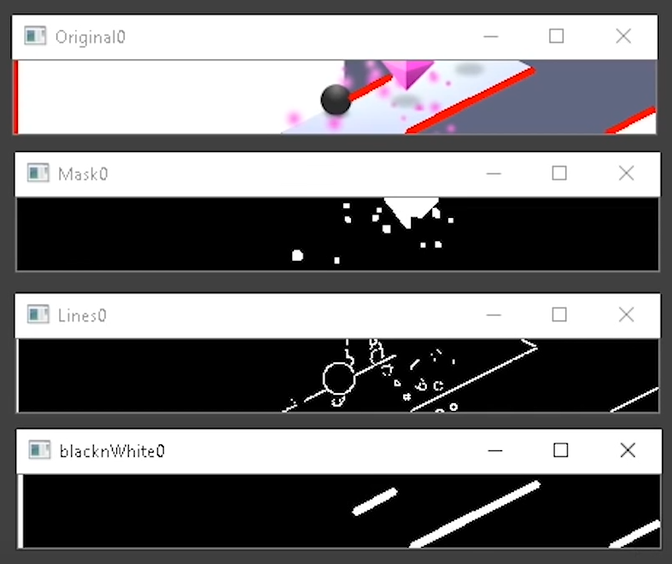
OpenCV is open-source library with tools and functionalities that support computer vision. It allows your computer to use complex mathematics to detect lines, shapes, colors, text and what not.
OpenCV was originally developed by Intel in 2000 and sometime later someone had the bright idea to build a Python module on top of it.
Using a simple…
pip install opencv-python
…you can now use OpenCV in Python to build advanced computer vision programs.
And this is exactly what many professional and hobby programmers are doing. Specifically, to get their computer to play (and win) mobile app games.
ZigZag
In ZigZag, you are a ball speeding down a narrow pathway and your only mission is to avoid falling off.
Using OpenCV, you can get your computer to detect objects, shapes, and lines.
This guy set up an emulator on his computer, so the computer can pretend to be a mobile device. Then he build a program using Python’s OpenCV module to get a top score
You can find the associated code here, but note that will need to set up an emulator yourself before being able to run this code.
Kick Ya Chop
In Kick Ya Chop, you need to stomp away parts of a tree as fast as you can, without hitting any of the branches.
This guy uses OpenCV to perform image pattern matching to allow his computer to identify and avoid the trees braches. Find the code here.
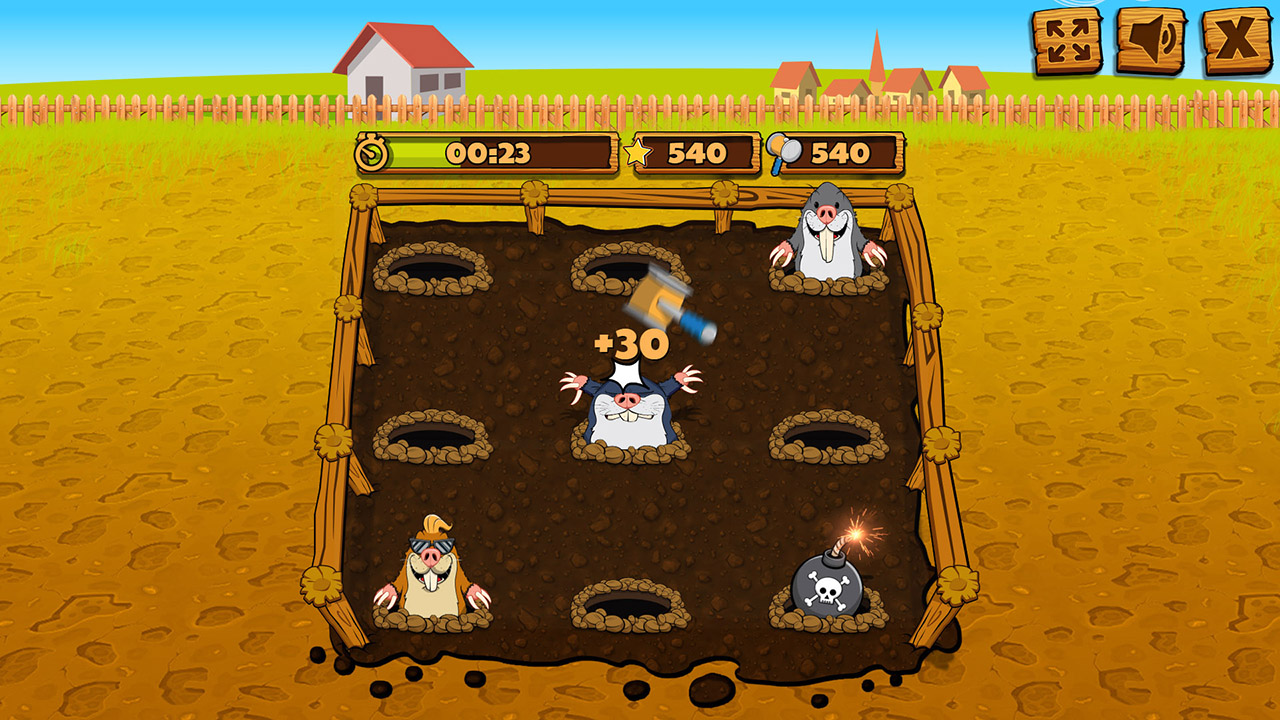
Whack ‘Em All
We all know how to play Whack a Mole, and now this computer knows how to too. Code here.
Pong
This last game also doesn’t need an introduction, and you can find the code here.
Is this machine learning or AI?
If you’d ask me, the videos above provide nice examples of advanced automation. But there’s no real machine learning or AI involved.
Yes, sure, the OpenCV package uses pre-trained neural networks under the hood, and you can definitely call those machine learning. But the programmers who now use the opencv library just leverage the knowledge stored in those network to create very basal decision rules.
IF pixel pattern of mole
THEN whack!
ELSE no whack.
To me, it’s only machine learning when there’s really some learning going on. A feedback loop with performance improvement. And you may call it AI, IMO, when the feedback loop is more or less autonomous.
Fortunately, programmers have also been taking a machine learning/AI approach to beating games. Specifically using reinforcement learning. Think of famous applications like AlphaGo and AlphaStar. But there are also hobby programmers who use similar techniques. For example, to get their computer to obtain highscores on Trackmania.
In a later post, I’ll dive into those in more detail.
Sometimes I just stumble across these random resources that I immediately want to share with fellow geeks. If you like computers and programming, you should definitely have a look at…
TryHackMe started in 2018 by two cyber security enthusiasts, Ashu Savani and Ben Spring, who met at a summer internship. When getting started with in the field, they found learning security to be a fragmented, inaccessable and difficult experience; often being given a vulnerable machine’s IP with no additional resources is not the most efficient way to learn, especially when you don’t have any prior knowledge. When Ben returned back to University he created a way to deploy machines and sent it to Ashu, who suggested uploading all the notes they’d made over the summer onto a centralised platform for others to learn, for free.
To allow users to share their knowledge, TryHackMe allows other users (at no charge) to create a virtual room, which contains a combination of theoretical and practical learning components.. In early 2019, Jon Peters started creating rooms and suggested the platform build up a community, a task he took on and succeeded in.
The platform has never raised any capital and is entirely bootstrapped.
I don’t have any affiliation or whatever with the platform, but I just think it’s a super cool resource if you want to learn more about hands-on computer stuff.
Here’s a nice demo on an advanced programmer taking on one of the first challenges. I definitely still have a long way to go, but it’s fun to watch someone sneak into a (dummy) server and look for clues! Like a proper detective, but then an extra nerdy one!
There are many “hacktivities” you can try on the platform.
And if you’re serious about learning this stuff, there are learning paths set out for you!
If you like their content, do consider taking a paid subscription and share this great initiative!
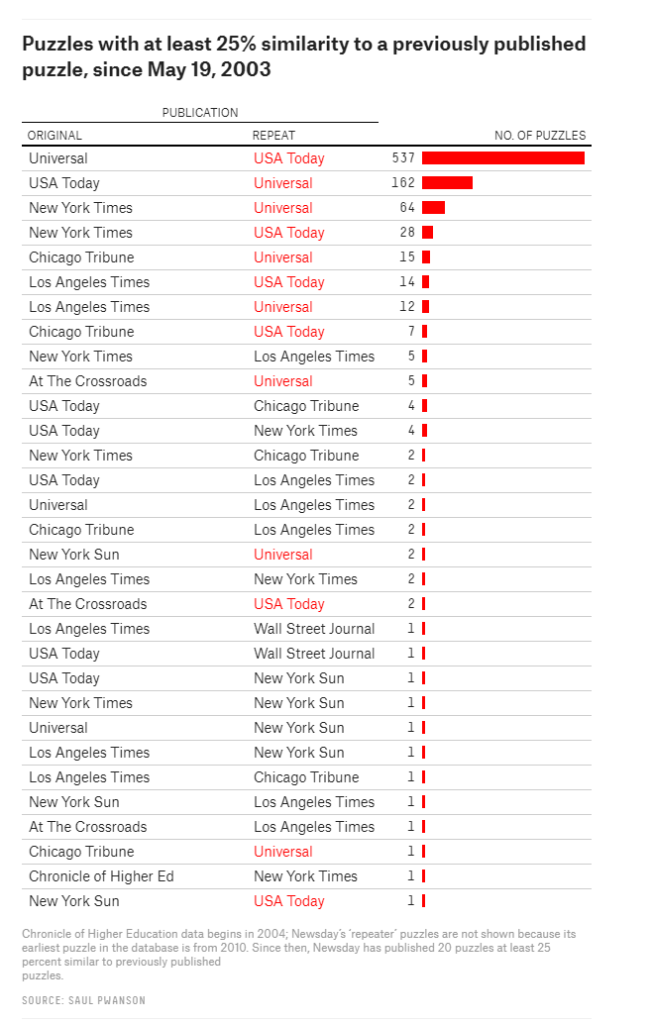
Vincent Warmerdam shared this Youtube video which I thoroughly enjoyed watched. It’s about Saul Pwanson, a software engineer whose hobby project got a little out of hand.
In 2016, Saul Pwanson designed a plain-text file format for crossword puzzle data, and then spent a couple of months building a micro-data-pipeline, scraping tens of thousands of crosswords from various sources.
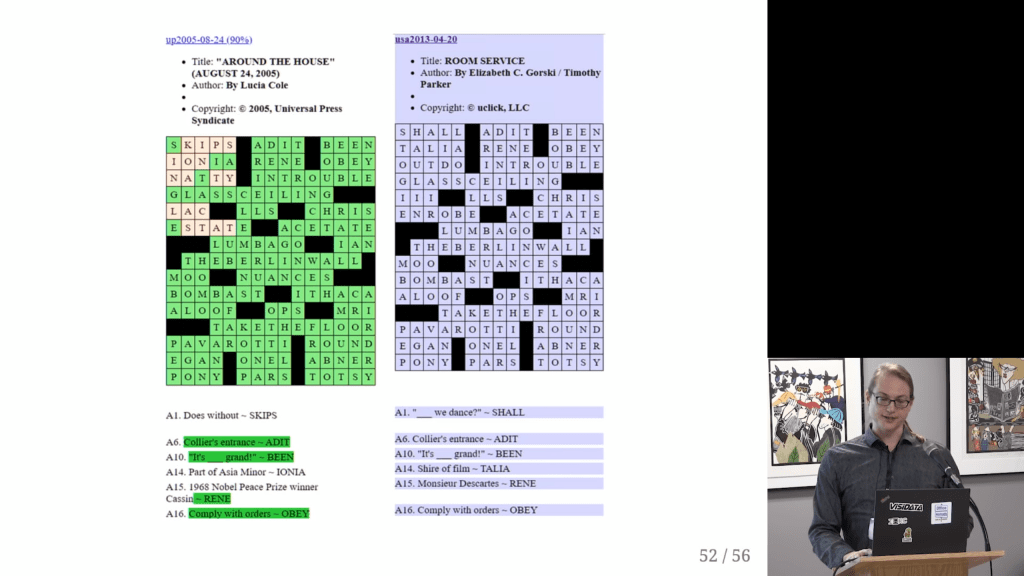
After putting all these crosswords in a simple uniform format, Saul used some simple command line commands to check for common patterns and irregularities.
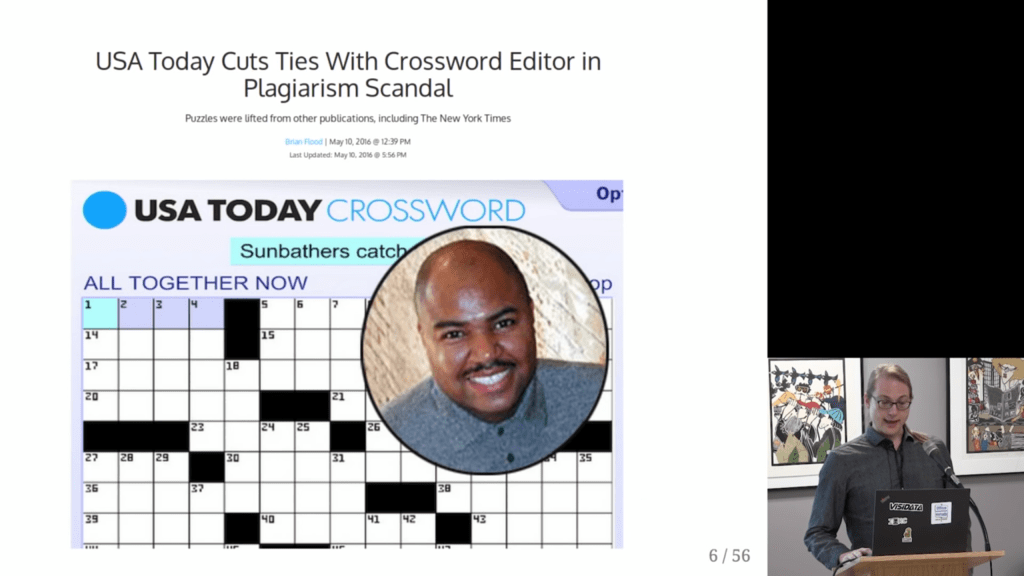
Surprisingly enough, after visualizing the results, Saul discovered egregious plagiarism by a major crossword editor that had gone on for years.
I thoroughly enjoyed watching this talk on Youtube.
Saul covers the file format, data pipeline, and the design choices that aided rapid exploration; the evidence for the scandal, from the initial anomalies to the final damning visualization; and what it’s like for a data project to get 15 minutes of fame.
I tried to localize the dataset online, but it seems Saul’s website has since gone offline. If you do happen to find it, please do share it in the comments!
Google’s guidebook to human-centered AI design refered to the Design Kit, containing numerous helpful tools to help you design products with user experience in mind.
The design kit website contains many practical methods, tools, case studies and much more resources to help you in the design process.
Human-centered design is a practical, repeatable approach to arriving at innovative solutions. Think of these Methods as a step-by-step guide to unleashing your creativity, putting the people you serve at the center of your design process to come up with new answers to difficult problems.
The design kit methods section provides some seriously handy guidelines to help you design your products with the customer in mind. A step-by-step process guideline is offered, as well as neat worksheets to records the information you collect in the process, and a video explanation of the method.