
For a year now, this course on Bayesian statistics has been on my to-do list. So without further ado, I decided to share it with you already.
Richard McElreath is an evolutionary ecologist who is famous in the stats community for his work on Bayesian statistics.
At the Max Planck Institute for Evolutionary Anthropology, Richard teaches Bayesian statistics, and he was kind enough to put his whole course on Statistical Rethinking: Bayesian statistics using R & Stan open access online.
You can find the video lectures here on Youtube, and the slides are linked to here:
Richard also wrote a book that accompanies this course:

For more information abou the book, click here.
For the Python version of the code examples, click here.





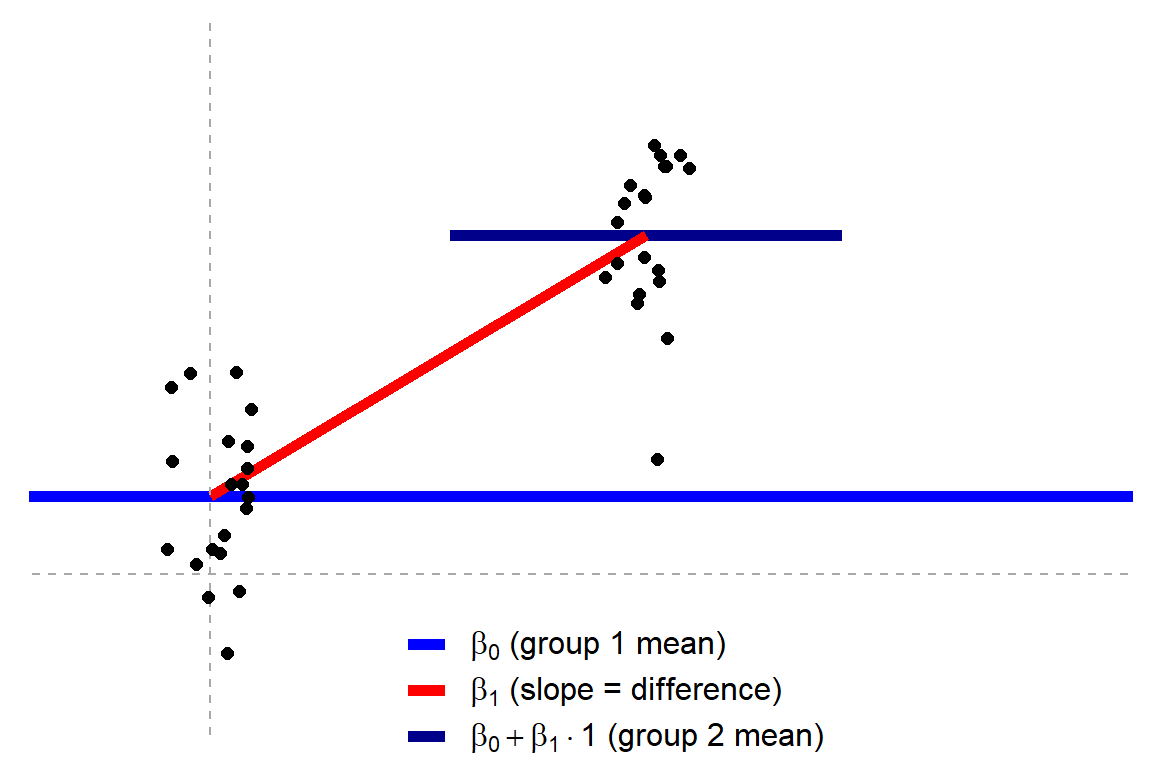
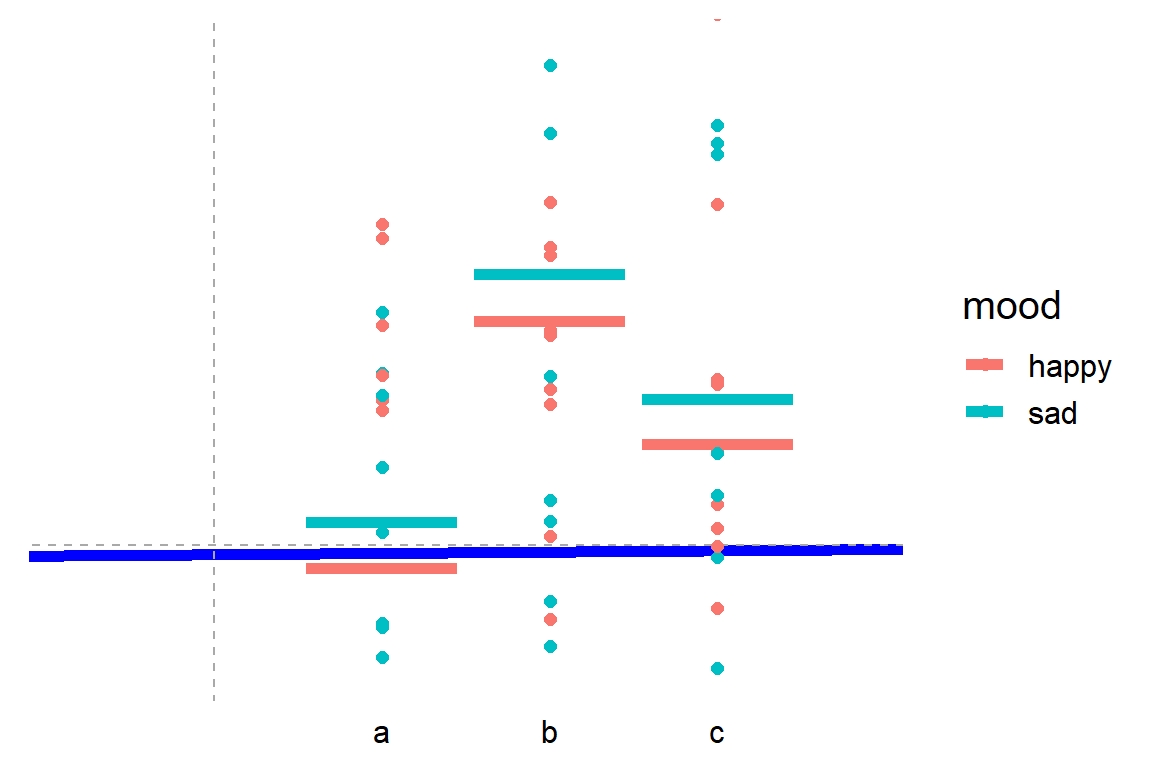






{kind=link}