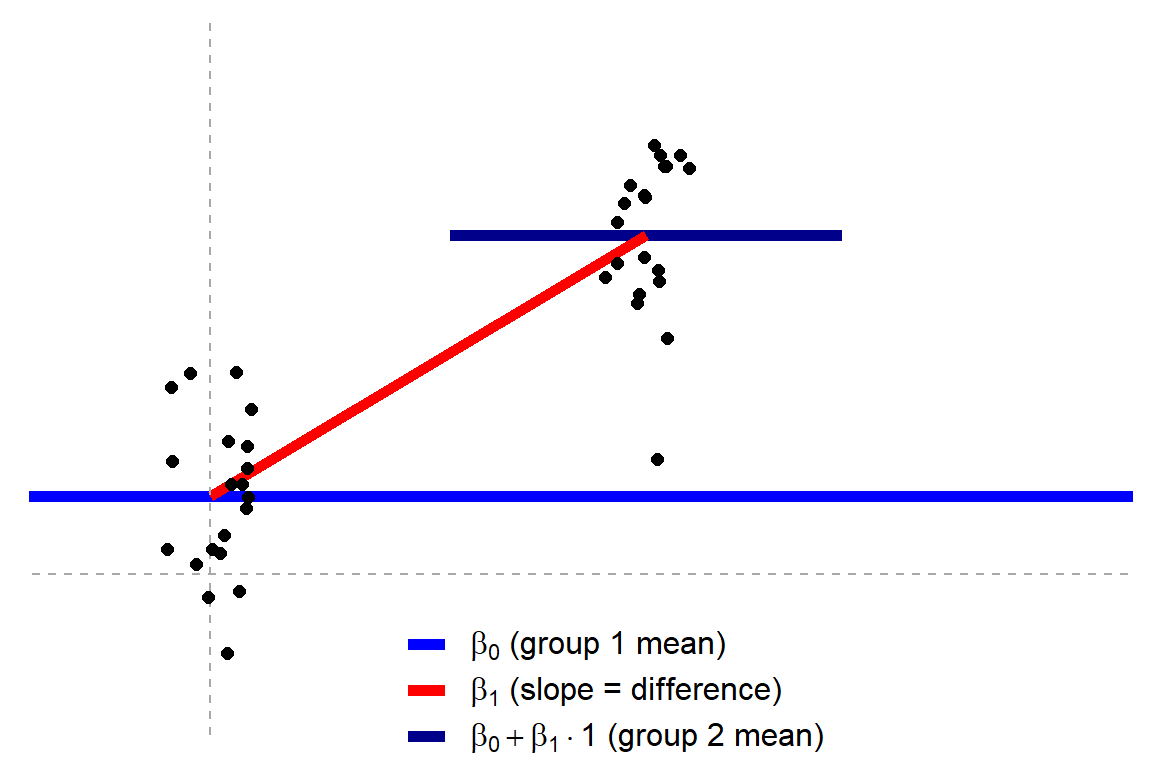
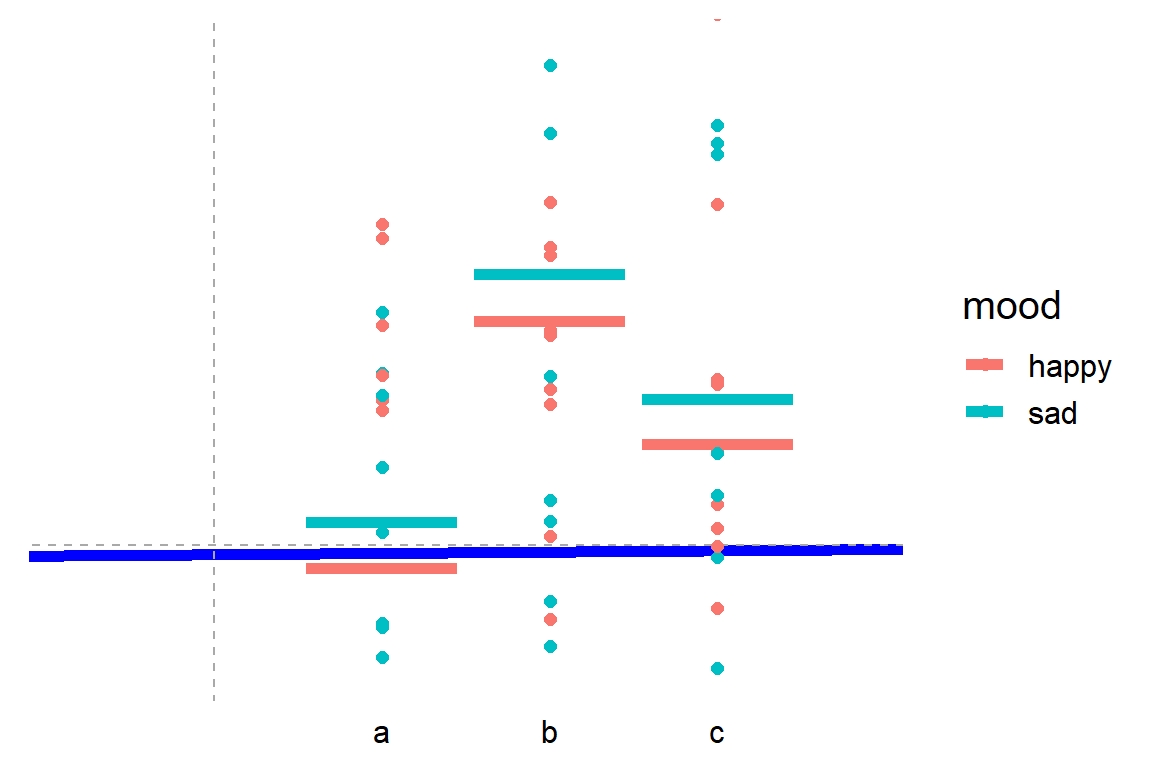
Jonas’ original blog uses R programming to visually show how the tests work, what the linear models look like, and how different approaches result in the same statistics.
Recently, I came across a social science paper that had used linear probability regression. I had never heard of linear probability models (LPM), but it seems just an application of ordinary least squares regression but to a binomial dependent variable.
According to some, LPM is a commonly used alternative for logistic regression, which is what I was learned to use when the outcome is binary.
Potentially because of my own social science background (HRM), using linear regression without a link transformation on binary data just seems very unintuitive and error-prone to me. Hence, I sought for more information.
I particularly liked this article by Jake Westfall, which he dubbed “Logistic regression is not fucked”, following a series of blogs in which he talks about methods that are fucked and not useful.
Jake explains the classification problem and both methods inner workings in a very straightforward way, using great visual aids. He shows how LMP would differ from logistic models, and why its proposed benefits are actually not so beneficial. Maybe I’m in my bubble, but Jake’s arguments resonated.
Here’s the summary: Arguments against the use of logistic regression due to problems with “unobserved heterogeneity” proceed from two distinct sets of premises. The first argument points out that if the binary outcome arises from a latent continuous outcome and a threshold, then observed effects also reflect latent heteroskedasticity. This is true, but only relevant in cases where we actually care about an underlying continuous variable, which is not usually the case. The second argument points out that logistic regression coefficients are not collapsible over uncorrelated covariates, and claims that this precludes any substantive interpretation. On the contrary, we can interpret logistic regression coefficients perfectly well in the face of non-collapsibility by thinking clearly about the conditional probabilities they refer to.
ungeviz is a new R package by Claus Wilke, whom you may know from his amazing work and books on Data Visualization. The package name comes from the German word “Ungewissheit”, which means uncertainty. You can install the developmental version via:
devtools::install_github("clauswilke/ungeviz")
The package includes some bootstrapping functionality that, when combined with ggplot2 and gganimate, can produce some seriousy powerful visualizations. For instance, take the below piece of code:
data(BlueJays, package="Stat2Data")
# set up bootstrapping object that generates 20 bootstraps# and groups by variable `KnownSex`bs<-ungeviz::bootstrapper(20, KnownSex)
ggplot(BlueJays, aes(BillLength, Head, color=KnownSex)) +
geom_smooth(method="lm", color=NA) +
geom_point(alpha=0.3) +# `.row` is a generated column providing a unique row number# to all rows in the bootstrapped data frame
geom_point(data=bs, aes(group= .row)) +
geom_smooth(data=bs, method="lm", fullrange=TRUE, se=FALSE) +
facet_wrap(~KnownSex, scales="free_x") +
scale_color_manual(values= c(F="#D55E00", M="#0072B2"), guide="none") +
theme_bw() +
transition_states(.draw, 1, 1) +
enter_fade() +
exit_fade()
Here’s what’s happening:
Claus loads in the BlueJays dataset, which contains some data on birds.
He then runs the ungezviz::bootstrapper function to generate a new dataset of bootstrapped samples.
Next, Claus uses ggplot2::geom_smooth(method = "lm") to run a linear model on the orginal BlueJays dataset, but does not color in the regression line (color = NA), thus showing only the confidence interval of the model.
Moreover, Claus uses ggplot2::geom_point(alpha = 0.3) to visualize the orginal data points, but slightly faded.
Subsequent, for each of the bootstrapped samples (group = .row), Claus again draws the data points (unfaded), and runs linear models while drawing only the regression line (se = FALSE).
Using ggplot2::facet_wrap, Claus seperates the data for BlueJays$KnownSex.
Using gganimate::transition_states(.draw, 1, 1), Claus prints each linear regression line to a row of the bootstrapped dataset only one second, before printing the next.
The result an astonishing GIF of the regression lines that could be fit to bootstrapped subsamples of the BlueJays data, along with their confidence interval:
One example of the practical use of ungeviz, original on its GitHub page
Another valuable use of the new package is the visualization of uncertainty from fitted models, for example as confidence strips. The below code shows the powerful combination of broom::tidy with ungeviz::stat_conf_strip to visualize effect size estimates of a linear model along with their confidence intervals.
library(broom)
#> #> Attaching package: 'broom'#> The following object is masked from 'package:ungeviz':#> #> bootstrapdf_model<- lm(mpg~disp+hp+qsec, data=mtcars) %>%
tidy() %>%
filter(term!="(Intercept)")
ggplot(df_model, aes(estimate=estimate, moe=std.error, y=term)) +
stat_conf_strip(fill="lightblue", height=0.8) +
geom_point(aes(x=estimate), size=3) +
geom_errorbarh(aes(xmin=estimate-std.error, xmax=estimate+std.error), height=0.5) +
scale_alpha_identity() +
xlim(-2, 1)
Visualizing effect size estimates with ungeviz, via its GitHub page
Very curious to see where this package develops into. What use cases can you think of?
PyData provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other. The communities approach data science using many languages, including (but not limited to) Python, Julia, and R.
April 2018, a PyData conference was held in London, with three days of super interesting sessions and hackathons. While I couldn’t attend in person, I very much enjoy reviewing the sessions at home as all are shared open access on YouTube channel PyDataTV!
In the following section, I will outline some of my favorites as I progress through the channel:
Winning with simple, even linear, models:
One talk that really resonated with me is Vincent Warmerdam‘s talk on “Winning with Simple, even Linear, Models“. Working at GoDataDriven, a data science consultancy firm in the Netherlands, Vincent is quite familiar with deploying deep learning models, but is also midly annoyed by all the hype surrounding deep learning and neural networks. Particularly when less complex models perform equally well or only slightly less. One of his quote’s nicely sums it up:
“Tensorflow is a cool tool, but it’s even cooler when you don’t need it!”
— Vincent Warmerdam, PyData 2018
In only 40 minutes, Vincent goes to show the finesse of much simpler (linear) models in all different kinds of production settings. Among others, Vincent shows:
how to solve the XOR problem with linear models
how to win at timeseries with radial basis features
how to use weighted regression to deal with historical overfitting
how deep learning models introduce a new theme of horror in production
how to create streaming models using passive aggressive updating
how to build a real-time video game ranking system using mere histograms
how to create a well performing recommender with two SQL tables
how to rock at data science and machine learning using Python, R, and even Stan