In this original blog, with equally original title, Delip Rao poses twelve (+1) harsh truths about the real world practice of machine learning. I found it quite enlightning to read a non-hyped article about ML for once. Particularly because Delip’s experiences seem to overlap quite nicely with the principles of software design and Agile working.
Delip’s 12 truths I’ve copied in headers below. If they spark your interest, read more here:
It has to work
No matter how hard you push and no matter what the priority, you can’t increase the speed of light
With sufficient thrust, pigs fly just fine. However, this is not necessarily a good idea
Some things in life can never be fully appreciated nor understood unless experienced firsthand
It is always possible to agglutinate multiple separate problems into a single complex interdependent solution. In most cases, this is a bad idea
It is easier to ignore or move a problem around than it is to solve it
You always have to tradeoff something
Everything is more complicated than you think
You will always under-provision resources
One size never fits all. Your model will make embarrassing errors all the time despite your best intentions
Every old idea will be proposed again with a different name and a different presentation, regardless of whether it works
Perfection has been reached not when there is nothing left to add, but when there is nothing left to take away
Delip added in a +1, with his zero-indexed truth: You are Not a Scientist.
Yes, that’s all of you building stuff with machine learning with a “scientist” in the title, including all of you with PhDs, has-been-academics, and academics with one foot in the industry. Machine learning (and other AI application areas, like NLP, Vision, Speech, …) is an engineering research discipline (as opposed to science research).
Delip [bio] is the VP of Research at AI Foundation where he leads speech, language, and vision research efforts for generating and detecting artificial content. You can find his personal webblog here.
I’ve had this WordPress domain for several years now, and in the beginning it was very convenient.
WordPress enabled me to set up a fully functional blog in a matter of hours. Everything from HTML markup, external content embedding, databases, and simple analytics was already conveniently set up.
However, after a while, I wanted to do some more advanced stuff. Here, the disadvantages of WordPress hosting became evident fast. Anything beyond the most simple capabilities is locked firmly behind paywalls. Arguably rightfully so. If you want to use WordPress’ add-ins, I feel you should pay for them. That’s their business model after all.
However, what greatly annoys me is that WordPress actively hinders you from arranging matters yourself. Want to incorporate some JavaScript in your page? Upgrade to a paid account. Want to use Google Analytics? Upgrade and buy an add-in. Want to customize your HTML / CSS code? Upgrade or be damned. Even the simplest of tasks — just downloading visitor counts — WordPress made harder than it should be.
You can download visitor statistics manually — day by day, week by week, or year by year. However, there is no way to download your visitor history in batches. If you want to have your daily visiting history, you will manually have to download and store every day’s statistics.
For me, getting historic daily data would entail 1100 times entering a date, scrolling down, clicking a button, specifying a filename, and clicking to save. I did this once, for 36 monthly data snapshots, and the insights were barely worth the hassle, I assure you.
Fortunately, today, after nearly three years of hosting on WordPress, I finally managed to circumvent past this annoyance! Using the Python script detailed below, my computer now automonously logs in to WordPress and downloads the historic daily visitor statistics for all my blogs and pages!
Let me walk you through the program and code.
Modules & Setup
Before we jump into Python, you need to install Chromedriver. Just download the zip and unpack the execution file somewhere you can find it, and make sure to copy the path into Python. You will need it later. Chromedriver allows Python’s selenium webdriver to open up and steer a chrome browser.
We need another module for browsing: webdriver_manager. The other modules and their functions are for more common purposes: os for directory management, re for regular expression, datetime for working with dates, and time for letting the computer sleep in between operations.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from time import sleep
from datetime import datetime, timedelta
import os
import re
Helper Functions
I try to write my code in functions, so let’s dive into the functions that allow us to download visitor statistics.
To begin, we need to set up a driver (i.e., automated browser) and this is what get_driver does. Two things are important here. Firstly, the function takes an argument dir_download. You need to give it a path so it knows where to put any downloaded files. This path is stored under preferences in the driver options. Secondly, you need to specify the path_chromedriver argument. This needs to be the exact location you unpacked the chromedriver.exe. All these paths you can change later in the main program, so don’t worry about them for now. The get_driver function returns a ready-to-go driver object.
Next, our driver will need to know where to browse to. So the function below, compile_traffic_url, uses an f-string to generate the url for the visitor statistics overview of a specific domain and date. Important here is that you will need to change the domain default from paulvanderlaken.com to your own WordPress adress. Take a look at the statistics overview in your regular browser to see how you may tailor your urls.
Now, in the rest of the program, I work dates formatted and stored as datetime.datetime.date(). By default, the compile_traffic_url function also uses a datetime date argument for today’s date. However, WordPress expects simple string dates in the urls. Hence, I need a way to convert these complex datetime dates into simpler strings. That’s what the strftimefunction below does. It formats a datetime date to a date_string, in the format YYYY-MM-DD.
So we know how to generate the urls for the pages we want to scrape. We compile them using this handy function.
If we would let the driver browse directly to one of these compiled traffic urls, you will find yourself redirected to the WordPress login page, like below. That’s a bummer!
Hence, whenever we start our program, we will first need to log in once using our password. That’s what the signing_in function below is for. This function takes in a driver, a username, and a password. It uses the compile_traffic_url function to generate a traffic url (by default of today’s traffic [see above]). Then the driver loads the website using its get method. This will redirect us to the WordPress login page. In order for the webpages to load before our driver starts clicking away, we let our computer sleep a bit, using time.sleep.
Now, our automated driver is looking at the WordPress login page. We need to help it find where to input the username and password. If you press CTRL+SHIFT+C while on any webpage, the HTML behind it will show. Now you can just browse over the webpage elements, like the login input fields, and see what their CSS selectors, names, and classes are.
If you press CTRL+SHIFT+C on a webpage, the html behind it will show.
So, next, I order the driver to find the HTML element of the username-input field and input my username keys into it. We ask the driver to find the Continue-button and click it. Time for the driver to sleep again, while the page loads the password input field. Afterwards, we ask the driver to find the password input field, input our password, and click the Continue-button a second time. While our automatic login completes, we let the computer sleep some more.
Once we have logged in once, we will remain logged in until the Python program ends, which closes the driver.
Okay, so now that we have a function that logs us in, let’s start downloading our visitor statistics!
The download_traffic function takes in a driver, a date, and a list of dates_downloaded (an empty list by default). First, it checks whether the date to download occurs in dates_downloaded. If so, we do not want to waste time downloading statistics we already have. Otherwise, it puts the driver to work downloading the traffic for the specified date following these steps:
Compile url for the specified date
Driver browses to the webpage of that url
Computer sleeps while the webpage loads
Driver executes script, letting it scroll down to the bottom of the webpage
Driver is asked to find the button to download the visitor statistics in csv
Driver clicks said button
Computer sleeps while the csv is downloaded
If anything goes wrong during these steps, an error message is printed and no document is downloaded. With no document downloaded, our program can try again for that link the next time.
def download_traffic(driver, date, dates_downloaded=[]):
if date in dates_downloaded:
print(f'Already downloaded {date} traffic')
else:
try:
print(f'Downloading {date} traffic')
url = compile_traffic_url(date=date)
driver.get(url)
sleep(1)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
button = driver.find_element_by_class_name('stats-download-csv')
button.click()
sleep(1)
except:
print(f'Error during downloading of {date}')
We need one more function to generate the dates_downloaded list of download_traffic. The date_from_filename function below takes in a filename (e.g., paulvanderlaken.com_posts_day_12_28_2019_12_28_2019) and searches for a regular expression date format. The found match is turned into a datetime date using strptime and returned. This allows us to walk through a directory on our computer and see for which dates we have already downloaded visitor statistics. You will see how this works in the main program below.
def date_from_filename(filename):
match = re.search(r'\d{2}_\d{2}_\d{4}', filename)
date = datetime.strptime(match.group(), '%m_%d_%Y').date()
return date
Main program
In the end, we combine all these above functions in our main program. Here you will need to change five things to make it work on your computer:
path_data – enter a folder path where you want to store the retrieved visitor statistics csv’s
path_chromedriver – enter the path to the chromedriver.exe you unpacked
first_date – enter the date from which you want to start scraping (by default up to today)
username – enter your WordPress username or email address
password – enter your WordPress password
if __name__ == '__main__':
path_data = 'C:\\Users\\paulv\\stack\\projects\\2019_paulvanderlaken.com-anniversary\\traffic-day\\'
path_chromedriver = 'C:\\Users\\paulv\\chromedriver.exe'
first_date = datetime(2017, 1, 18).date()
last_date = datetime.today().date()
username = "insert_username"
password = "insert_password"
driver = get_driver(dir_download=path_data, path_chromedriver=path_chromedriver)
days_delta = last_date - first_date
days = [first_date + timedelta(days) for days in range(days_delta.days + 1)]
dates_downloaded = [date_from_filename(file) for _, _, f in os.walk(path_data) for file in f]
signing_in(driver, username=username, password=password)
for d in days:
download_traffic(driver, d, dates_downloaded)
driver.close()
If you have downloaded Chromedriver, have copied all the code blocks from this blog into a Python script, and have added in your personal paths, usernames, and passwords, this Python program should work like a charm on your computer as well. By default, the program will scrape statistics from all days from the first_date up to the day you run the program, but this you can change obviously.
Results
For me, the program took about 10 seconds to download one csv consisting of statistics for one day. So three years of WordPress blogging, or 1095 daily datasets of statistics, were extracted in about 3 hours. I did some nice cooking and wrote this blog in the meantime : )
The result after 3 hours of scraping
Compare that to the horror of having to surf, scroll, and click that godforsaken Download data as CSV button ~1100 times!!
The horror button (in Dutch)
Final notes
The main goal of this blog was to share the basic inner workings of this scraper with you, and to give you the same tool to scrape your own visitor statistics.
Now, this project can still be improved tremendously and in many ways. For instance, with very little effort you could add some command line arguments (with argparse) so you can run this program directly or schedule it daily. My next step is to set it up to run daily on my Raspberry Pi.
An additional potential improvement: when the current script encounters no statistics do download for a specific day, no csv is saved. This makes the program try again a next time it is run, as the dates_downloaded list will not include that date. Probably this some minor smart tweaks will solve this issue.
Moreover, there are many more statistics you could scrape of your WordPress account, like external clicks, the visitors home countries, search terms, et cetera.
The above are improvement points you can further develop yourself, and if you do please share them with the greater public so we can all benefit!
For now, I am happy with these data, and will start on building some basic dashboards and visualizations to derive some insights from my visitor patterns. If you have any ideas or experiences please let me know!
I hope this walkthrough and code may have help you in getting in control of your WordPress website as well. Or that you learned a thing or two about basic web scraping with Python. I am still in the midst of starting with Python myself, so if you have any tips, tricks, feedback, or general remarks, please do let me know! I am always happy to talk code and love to start pet projects to improve my programming skills, so do reach out if you have any ideas!
Over the course of last week, I built a Python program that scrapes quotes from Goodreads.com in a tidy format. For instance, these are the first three results my program returns when scraping for the tag robot:
Quote
author
source
likes
tags
Goodbye, Hari, my love. Remember always–all you did for me.
Isaac Asimov
Forward the Foundation
33
[‘asimov’, ‘foundation’, ‘human’, ‘robot’]
Unfortunately this Electric Monk had developed a fault, and had started to believe all kinds of things, more or less at random. It was even beginning to believe things they’d have difficulty believing in Salt Lake City.
As it’s bio reads, ArtificialStupidity is a highly sentient AI intelligently matching quotes and comics through state-of-the-art robotics, sophisticated machine learning, and blockchain technology.
Basically, every 15 minutes, a Python script is triggered on my computer (soon on my Raspberry Pi 4). Each time it triggers, this script generates a random number to determine whether it should post something. If so, the script subsequently generates another random number to determine what is should post: a quote, a comic, or both. Behind the scenes, some other functions add hastags and — voila — a tweet is born!
(An upcoming post will elaborate on the inner workings of my ArtificialStupidity Python script)
More often than not, ArtificialStupidity produces some random, boring tweet:
Now, in order to compile these tweets, my computer hosts two databases. One containing data- and tech- related comics; the other a variety of inspirational quotes. Each time the ArtificialStupidity bot posts a tweet, it draws from one or both of these datasets randomly. With, on average, one post every couple hours, I thus need several hundreds of items in these databases in order to prevent repetition — which is definitely not entertaining.
Up until last week, I manually expanded these databases every week or so. Adding new comics and quotes as I encountered them online. However, this proved a tedious task. Particularly for the quotes, as I set up the database in a specific format (“quote” – author). In contrast, websites like Goodreads.com display their quotes in a different format (e.g., “quote” ― author, source \n tags \n likes). Apart from the different format, the apostrophes and long slash also cause UTF-8 issues in my Python script. Hence, weekly reformatting of quotes proved an annoying task.
Up until this week!
While reformatting some bias-related quotes, I decided I’d rather invest 10 times more time developing my Python skills, than mindlessly reformatting quotes for a minute longer. So I started coding.
I am proud to say that, some six hours later, I have compiled the script below.
I’ll walk you through it’s functions.
So first, I import the modules/packages I need. Note that you will probably first have to pip install package-name on your own computer!
argparse for the command-line interface arguments
re for the regular expressions to clean quotes
bs4 for its BeautifulSoup for scraping website content
urllib.request for opening urls
csv to save csv files
os for directory pathing
import argparse
import re
from bs4 import BeautifulSoup
from urllib.request import urlopen, Request
import csv
import os
Next, I set up the argparse.ArgumentParser so that I can use my API using the command line. Now you can call the Python script using the command line (e.g., goodreads-scraper.py -t 'bias' -p 3 -q 80), and provide it with some arguments. No arguments are necessary. Most have sensible defaults. If you forget to provide a tag you will be prompted to provide one as the script runs (see later).
ap = argparse.ArgumentParser(description='Scrape quotes from Goodreads.com')
ap.add_argument("-t", "--tag",
required=False, type=str, default=None,
help="tag (topic/theme) of quotes to scrape")
ap.add_argument("-p", "--max_pages",
required=False, type=int, default=10,
help="maximum number of webpages to scrape")
ap.add_argument("-q", "--max_quotes",
required=False, type=int, default=100,
help="maximum number of quotes to scrape")
args = vars(ap.parse_args())
Now, the main function for this script is download_goodreads_quotes. This function contains many other functions within. You will see I set my functions up in a nested fashion, so that functions which are only used inside a certain scope, are instantiated there. In regular words, I create the functions where I use them.
First, download_goodreads_quotes creates download_quotes_from_page. In turn, download_quotes_from_page creates and calls compile_url — to create the url — get_soup — to download url contents — extract_quotes_elements_from_soup — to do just that — and extract_quote_dict. This latter function is the workhorse, as it takes each scraped quote element block of HTML and extracts the quote, author, source, and number of likes. It cleans each of these data points and returns them as a dictionary. In the end, download_quotes_from_page returns a list of dictionaries for every quote element block on a page.
Second, download_goodreads_quotes creates and calls download_all_pages which calls download_quotes_from_page for all pages up to max_pages, or up to the page that no longer returns quote data, or up to the number of max_quotes has been reached. All gathered quote dictionaries are added to a results list.
Additionally, I use two functions to actually store the scraped quotes: recreate_quote turns a quote dictionary into a quote (I actually do not use the source and likes, but maybe others want to do so); save_quotes calls this recreate quote for the list of quote dictionaires it’s given, and stores them in a csv file in the current directory.
Update 2020/04/05: added UTF-8 encoding based on infoguild‘s comment.
def recreate_quote(dict):
return f'"{dict.get("quote")}" - {dict.get("author")}'
def save_quotes(quote_data, tag):
save_path = os.path.join(os.getcwd(), 'scraped' + '-' + tag + '.txt')
print('saving file')
with open(save_path, 'w', encoding='utf-8') as f:
quotes = [recreate_quote(q) for q in quote_data]
for q in quotes:
f.write(q + '\n')
Finally, I need to call all these functions when the user runs this script via the command line. That’s what the following code does. If looks at the provided (default) arguments, and if no tag is provided, the user is prompted for one. Next Goodreads.com is scraped using the earlier specified download_goodreads_quotes function, and the results are saved to a csv file.
if __name__ == '__main__':
tag = args['tag'] if args['tag'] != None else input('Provide tag to search quotes for: ')
mp = args['max_pages']
mq = args['max_quotes']
result = download_goodreads_quotes(tag, max_pages=mp, max_quotes=mq)
save_quotes(result, tag)
Use
If you paste these script pieces sequentially in a Python script / text file, and save this file as goodreads-scraper.py. You can then run this script using your command line, like so goodreads-scraper.py -t 'bias' -p 3 -q 80 where the text after -t is the tag you are searching for, -p is the number of pages you want to scrape, and -q is the maximum number of quotes you want the program to scrape.
Let me know what your favorite quote is once you get it running!
To-do
So this is definitely still work in progress. Some potential improvements I want to integrate come directly to mind:
Avoid errors for quotes including newlines, or
Write code to extract only the text of the quote, instead of the whole text of the quote element.
Build in concurrency using futures (but take care that quotes are still added the results sequentially. Maybe we can already download the soups of all pages, as this takes the longest.
Write a function to return a random quote
Write a function to return a random quote within a tag
Implement a lower limit for the number of likes of quotes
Refactor the download_all_pages bit.
Add comments and docstrings.
Feedback or tips?
I have been programming in R for quite a while now, but Python and software development in general are still new to me. This will probably be visible in the way I program, my syntax, the functions I use, or other things. Please provide any feedback you may have as I’d love to get better!
YouTube recommended I’d watch this recorded presentation by Raymond Hettinger at PyBay2019 last October. Quite a long presentation for what I’d normally watch, but what an eye-openers it contains!
Raymond Hettinger is a Python core developer and in this video he presents 10 programming strategies in these 60 minutes, all using live examples. Some are quite obvious, but the presentation and examples make them very clear. Raymond presents some serious programming truths, and I think they’ll stick.
First, Raymond discusses chunking and aliasing. He brings up the theory that the human mind can only handle/remember 7 pieces of information at a time, give or take 2. Anything above proves to much cognitive load, and causes discomfort as well as errors. Hence, in a programming context, we need to make sure programmers can use all 7 to improve the code, rather than having to decypher what’s in front of them. In a programming context, we do so by modularizing and standardizing through functions, modules, and packages. Raymond uses the Python random module to hightlight the importance of chunking and modular code. This part was quite long, but still interesting.
For the next two strategies, Raymond quotes the Feinmann method of solving problems: “(1) write down a clear problem specification; (2) think very, very hard; (3) write down a solution”. Using the example of a tree walker, Raymond shows how the strategies of incremental development and solving simpler programs can help you build programs that solve complex problems. This part only lasts a couple of minutes but really underlines the immense value of these strategies.
Next, Raymond touches on the DRY principle: Don’t Repeat Yourself. But in a context I haven’t seen it in yet, object oriented programming [OOP], classes, and inherintance.
Raymond continues to build his arsenal of programming strategies in the next 10 minutes, where he argues that programmers should repeat tasks manually until patterns emerge, before they starting moving code into functions. Even though I might not fully agree with him here, he does have some fun examples of file conversion that speak in his case.
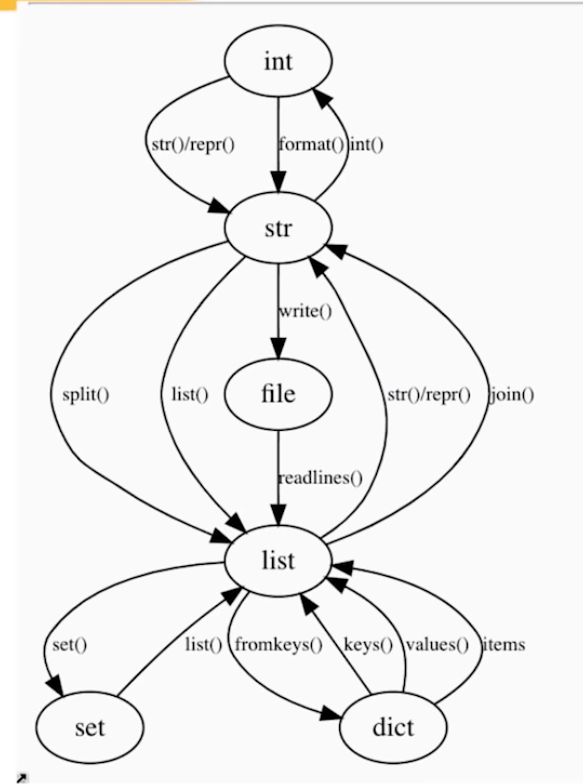
Lastly, Raymond uses the graph below to make the case that OOP is a graph traversal problem. According to Raymond, the Python ecosystem is so rich that there’s often no need to make new classes. You can simply look at the graph below. Look for the island you are currently on, check which island you need to get to, and just use the methods that are available, or write some new ones.
While there were several more strategies that Raymond wanted to discuss, he doesn’t make it to the end of his list of strategies as he spend to much time on the first, chunking bit. Super curious as to the rest? Contact Raymond on Twitter.
In this awesome 8-minute read, R-progidy Colin Fay explains in laymen’s terms what Docker images, Docker containers, and Volumes are; what Rocker is; and how to set up a Docker container with an R image and run code on it:
On your machine, you’re going to need two things: images, and containers. Images are the definition of the OS, while the containers are the actual running instances of the images. […] To compare with R, this is the same principle as installing vs loading a package: a package is to be downloaded once, while it has to be launched every time you need it. And a package can be launched in several R sessions at the same time easily.
Last week, this interesting reddit thread was filled with overviews for cool projects that may help you learn a programming language. The top entries are: