I just love psychological experiments around our human biases.
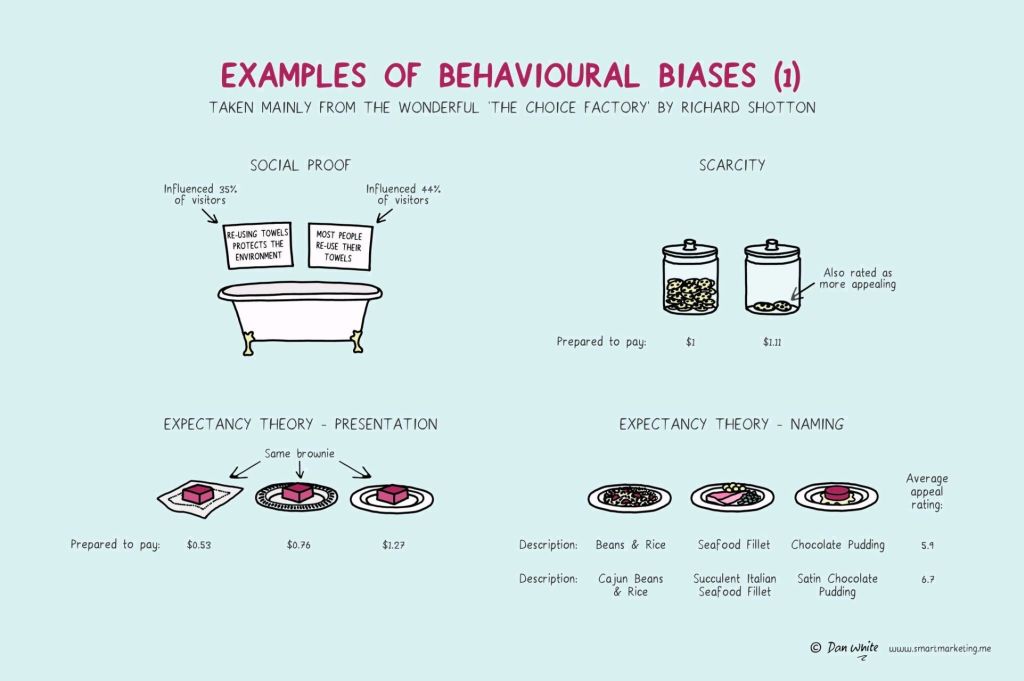
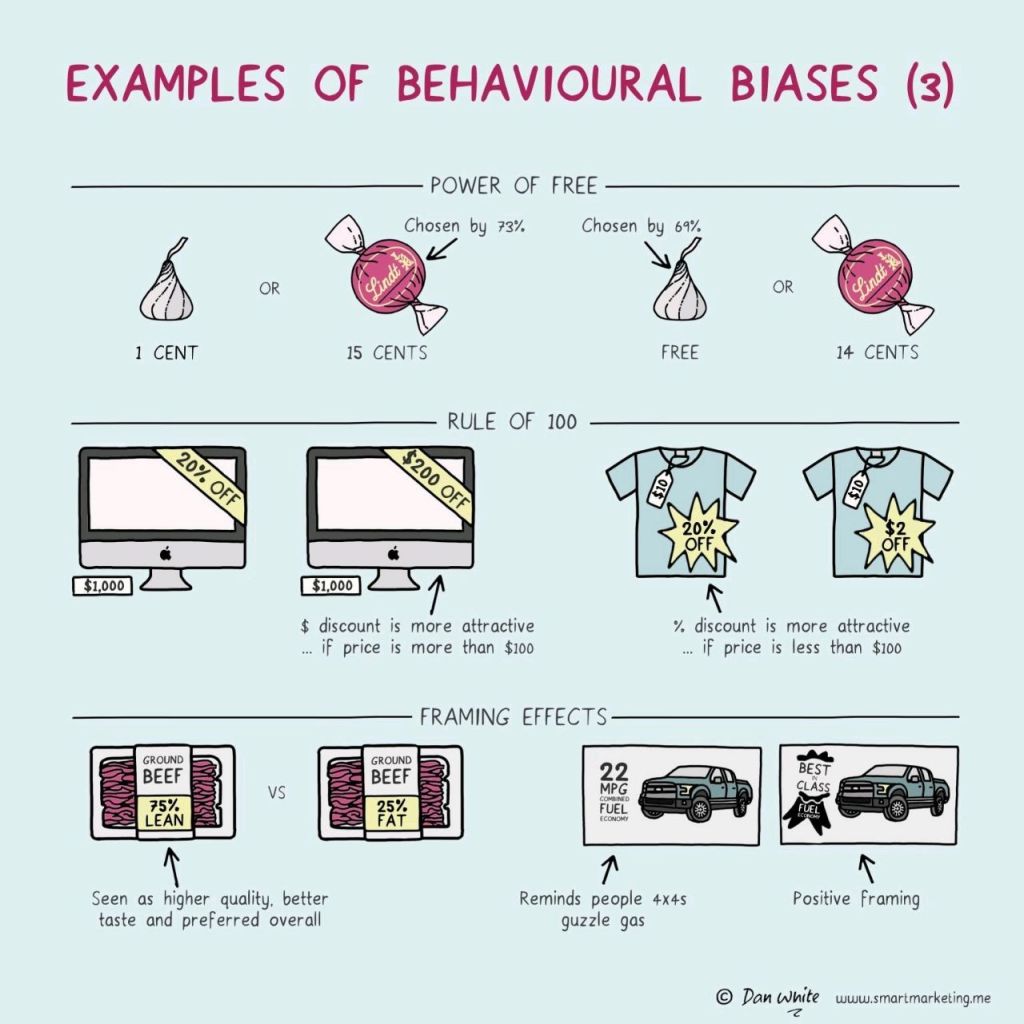
In this case, Dan White visualized some of the psychological biases mentioned in Richard Shotton‘s book “The Choice Factory“.
These biases make for irrational human behavior in the way we make daily decisions.
For example, you will be prepared to pay more for a cookie, when there are less of them in the jar. The generic principle here is that we assign higher valuations to objects under conditions of scarcity.
Once you are aware of such psychological biases, you will start to notice how they are (mis)used nearly everywhere these days. Particularly in sales and marketing. In restaurants, shops, online, and in virtually any case where we act as a consumer, we are subconciously influenced to make certain purchasing decision.
Nudging, is what they call these attempts to manipulate your behavior.
Maybe not so ethical, but still these infographics look amazing and these biases are good to be aware of!
Disclaimer: This page contains one or more links to Amazon. Any purchases made through those links provide us with a small commission that helps to host this blog.
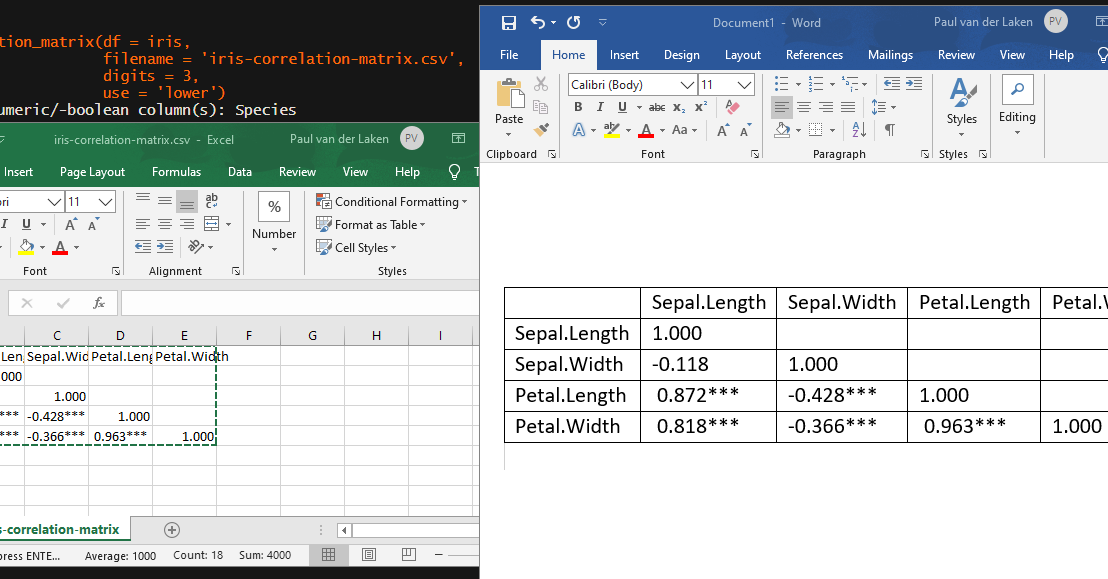
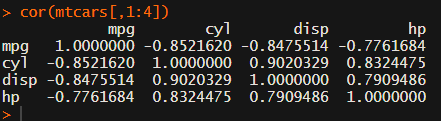
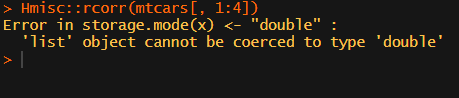
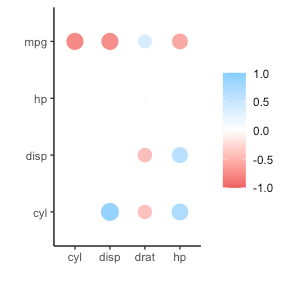
In most (observational) research papers you read, you will probably run into a correlation matrix. Often it looks something like this:
In Social Sciences, like Psychology, researchers like to denote the statistical significance levels of the correlation coefficients, often using asterisks (i.e., *). Then the table will look more like this:
Regardless of my personal preferences and opinions, I had to make many of these tables for the scientific (non-)publications of my Ph.D..
I remember that, when I first started using R, I found it quite difficult to generate these correlation matrices automatically.
Yes, there is the cor function, but it does not include significance levels.
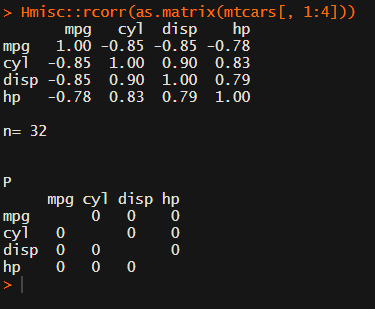
Then there the (in)famous Hmisc package, with its rcorr function. But this tool provides a whole new range of issues.
What’s this storage.mode, and what are we trying to coerce again?
Soon you figure out that Hmisc::rcorr only takes in matrices (thus with only numeric values). Hurray, now you can run a correlation analysis on your dataframe, you think…
Yet, the output is all but publication-ready!
You wanted one correlation matrix, but now you have two… Double the trouble?
[UPDATED] To spare future scholars the struggle of the early day R programming, Laura Lambert and I created an R package corrtable, which includes the helpful function correlation_matrix.
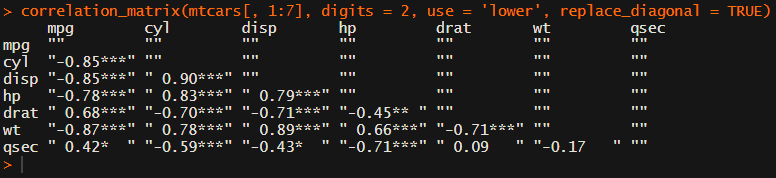
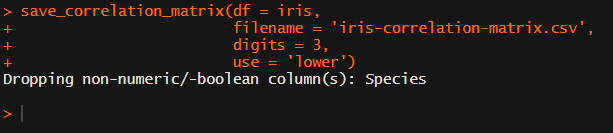
This correlation_matrix takes in a dataframe, selects only the numeric (and boolean/logical) columns, calculates the correlation coefficients and p-values, and outputs a fully formatted publication-ready correlation matrix!
For instance, you can use only 2 decimals. You can focus on the lower triangle (as the lower and upper triangle values are identical). And you can drop the diagonal values:
Or maybe you are interested in a different type of correlation coefficients, and not so much in significance levels:
YouTube recommended I’d watch this recorded presentation by Raymond Hettinger at PyBay2019 last October. Quite a long presentation for what I’d normally watch, but what an eye-openers it contains!
Raymond Hettinger is a Python core developer and in this video he presents 10 programming strategies in these 60 minutes, all using live examples. Some are quite obvious, but the presentation and examples make them very clear. Raymond presents some serious programming truths, and I think they’ll stick.
First, Raymond discusses chunking and aliasing. He brings up the theory that the human mind can only handle/remember 7 pieces of information at a time, give or take 2. Anything above proves to much cognitive load, and causes discomfort as well as errors. Hence, in a programming context, we need to make sure programmers can use all 7 to improve the code, rather than having to decypher what’s in front of them. In a programming context, we do so by modularizing and standardizing through functions, modules, and packages. Raymond uses the Python random module to hightlight the importance of chunking and modular code. This part was quite long, but still interesting.
For the next two strategies, Raymond quotes the Feinmann method of solving problems: “(1) write down a clear problem specification; (2) think very, very hard; (3) write down a solution”. Using the example of a tree walker, Raymond shows how the strategies of incremental development and solving simpler programs can help you build programs that solve complex problems. This part only lasts a couple of minutes but really underlines the immense value of these strategies.
Next, Raymond touches on the DRY principle: Don’t Repeat Yourself. But in a context I haven’t seen it in yet, object oriented programming [OOP], classes, and inherintance.
Raymond continues to build his arsenal of programming strategies in the next 10 minutes, where he argues that programmers should repeat tasks manually until patterns emerge, before they starting moving code into functions. Even though I might not fully agree with him here, he does have some fun examples of file conversion that speak in his case.
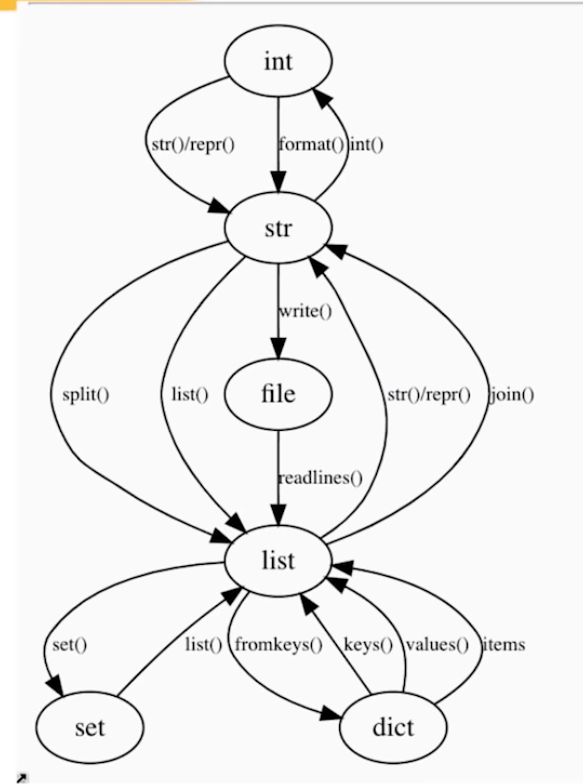
Lastly, Raymond uses the graph below to make the case that OOP is a graph traversal problem. According to Raymond, the Python ecosystem is so rich that there’s often no need to make new classes. You can simply look at the graph below. Look for the island you are currently on, check which island you need to get to, and just use the methods that are available, or write some new ones.
While there were several more strategies that Raymond wanted to discuss, he doesn’t make it to the end of his list of strategies as he spend to much time on the first, chunking bit. Super curious as to the rest? Contact Raymond on Twitter.
Voor Privacyweb schreef ik onlangs over people analytics en het mogelijk resulterende nudgen van medewerkers: kleine aanpassingen of duwtjes die mensen in de goede richting zouden moeten sturen. Medewerkers verleiden tot goed gedrag, als het ware. Maar wie bepaalt dan wat goed is, en wanneer zouden werkgevers wel of niet mogen of zelfs moeten nudgen?
With great pleasure I’ve studied and worked in the field of people analytics, where we seek to leverage employee, management-, and business information to better organize and manage our personnel. Here, data has proven valuable itself indispensible for the organization of the future.
Data and analytics have not traditionally been high on the list of HR professionals. Fortunately, there is an increased awareness that the 21st century (HR) manager has to be data-savvy. But where to start learning? The plentiful available resources can be daunting…
Have a look at these 100+ amazing books for (starting) people analytics specialists. My personal recommendations are included as pictures, but feel free to ask for more detailed suggestions!
Categories (clickable)
Behavioural Psychology: focus on behavioural psychology and economics, including decision-making and the biases therein.
Technology: focus on the implications of new technology….
Ethics: … on society and humanity, and what can go wrong.
Digital & Data-driven HR: … for the future of work, workforce, and organization. Includes people analytics case studies.
Management: focus on industrial and organizational psychology, HR, leadership, and business strategy.
Statistics: focus on the technical books explaining statistical concepts and applied data analysis.
People analytics: …. more technical books on how to conduct people analytics studies step-by-step in (statistical) software.
Programming: … technical books specifically aimed at (statistical) programming and data analysis.
Communication: focus on information exchange, presentation, and data visualization.
Disclaimer: This page contains one or more links to Amazon. Any purchases made through those links provide us with a small commission that helps to host this blog.
I want to thank the active people analytics community, publishing in management journals, but also on social media. I knew Littral Shemer Haim already hosted a people analytics reading list, and so did Analytics in HR (Erik van Vulpen) and Workplaceif (Manoj Kumar). After Jared Valdron called for book recommendation on people analytics on LinkedIn, and nearly 60 people replied, I thought let’s merge these overviews.
Hence, a big thank you and acknowledgement to all those who’ve contributed directly or indirectly. I hope this comprehensive merged overview is helpful.