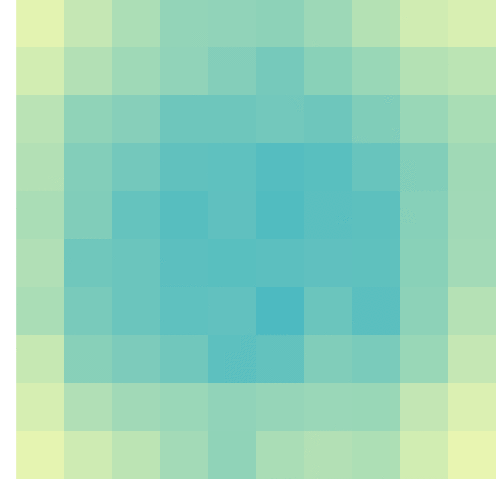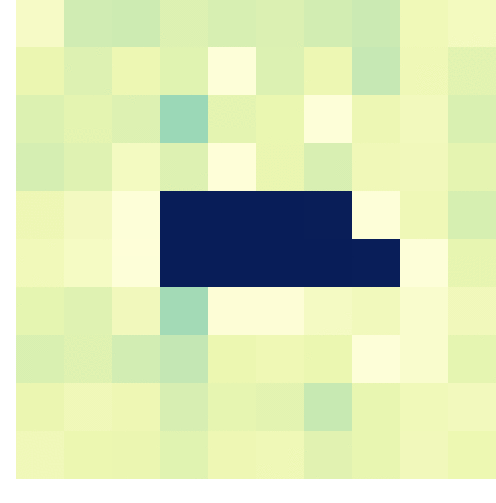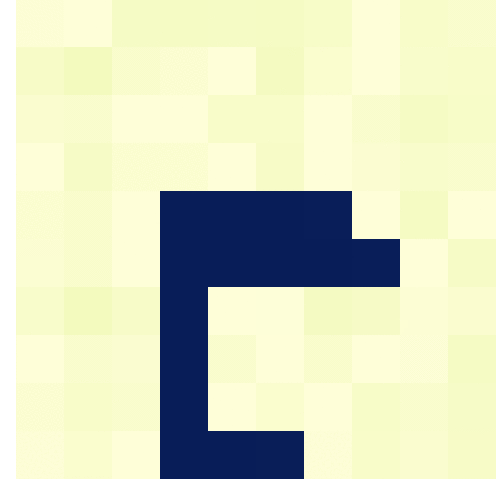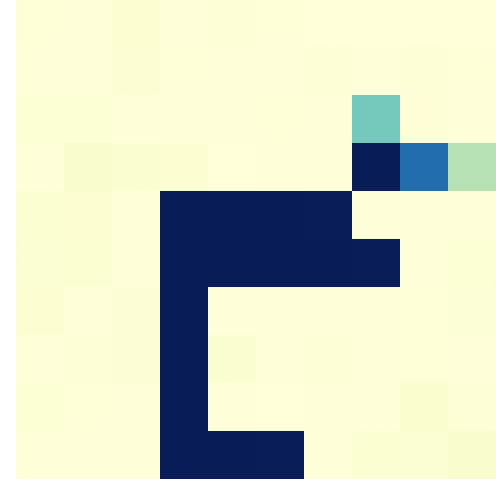I really like generative art, or so-called algorithmic art. Basically, it means you take a pattern or a complex system of rules, and apply it to create something new following those patterns/rules.
When I finished my PhD, I got a beautiful poster of where the k-nearest neighbors algorithms was used to generate a set of connected points.
As we recently moved into our new house, I decided I wanted to have a brother for the knn-poster. So I did some research in algorithms I wanted to use to generate a painting. I found some very cool ones, of which I unforunately can’t recollect the artists anymore:
Note: these are NOT mine
However, I preferred to make one myself. So we again turned to the work of the author that made the knn-poster: Marcus Volz.
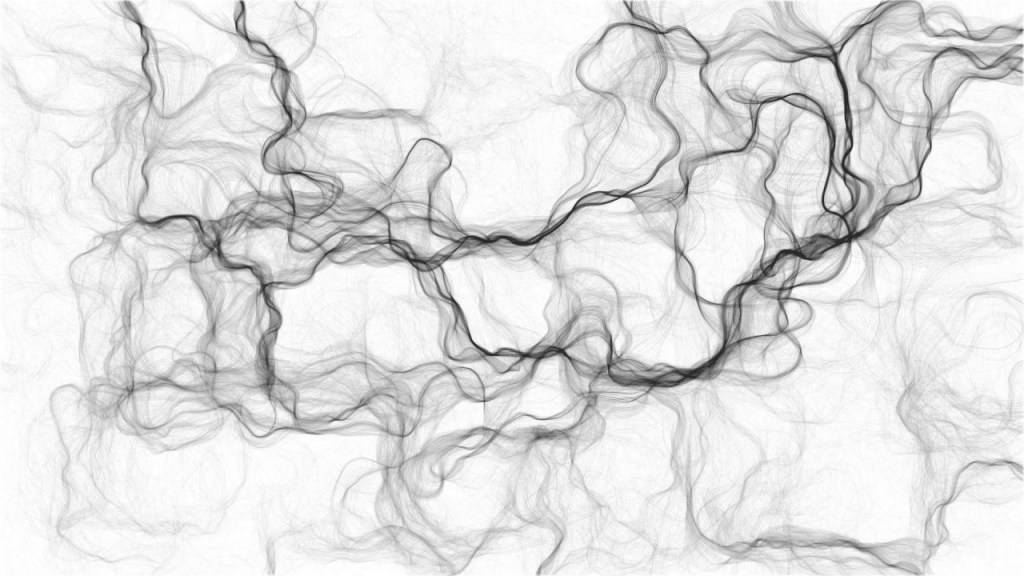
He has written (in R) many other algorithms. And we found that one specifically nicely matched the knn-poster. His metropolis – or generative city:
However, I wanted to make one myself, so I download Marcus code, and tweaked it a bit. Most importantly, I made it start in the center, made it fill up the whole space, and I made it run more efficient so I could generate a couple dozen large cities quickly, and pick the one I liked most. Here’s the end result:
YouTube recommended I’d watch this recorded presentation by Raymond Hettinger at PyBay2019 last October. Quite a long presentation for what I’d normally watch, but what an eye-openers it contains!
Raymond Hettinger is a Python core developer and in this video he presents 10 programming strategies in these 60 minutes, all using live examples. Some are quite obvious, but the presentation and examples make them very clear. Raymond presents some serious programming truths, and I think they’ll stick.
First, Raymond discusses chunking and aliasing. He brings up the theory that the human mind can only handle/remember 7 pieces of information at a time, give or take 2. Anything above proves to much cognitive load, and causes discomfort as well as errors. Hence, in a programming context, we need to make sure programmers can use all 7 to improve the code, rather than having to decypher what’s in front of them. In a programming context, we do so by modularizing and standardizing through functions, modules, and packages. Raymond uses the Python random module to hightlight the importance of chunking and modular code. This part was quite long, but still interesting.
For the next two strategies, Raymond quotes the Feinmann method of solving problems: “(1) write down a clear problem specification; (2) think very, very hard; (3) write down a solution”. Using the example of a tree walker, Raymond shows how the strategies of incremental development and solving simpler programs can help you build programs that solve complex problems. This part only lasts a couple of minutes but really underlines the immense value of these strategies.
Next, Raymond touches on the DRY principle: Don’t Repeat Yourself. But in a context I haven’t seen it in yet, object oriented programming [OOP], classes, and inherintance.
Raymond continues to build his arsenal of programming strategies in the next 10 minutes, where he argues that programmers should repeat tasks manually until patterns emerge, before they starting moving code into functions. Even though I might not fully agree with him here, he does have some fun examples of file conversion that speak in his case.
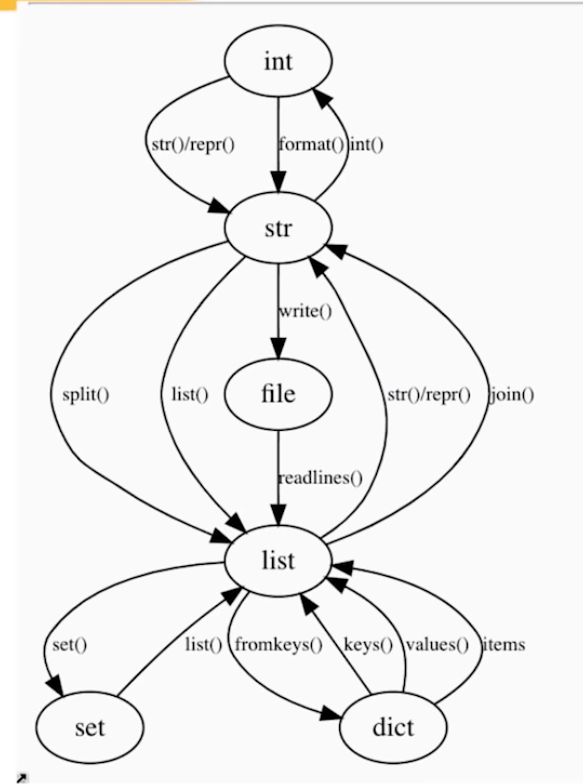
Lastly, Raymond uses the graph below to make the case that OOP is a graph traversal problem. According to Raymond, the Python ecosystem is so rich that there’s often no need to make new classes. You can simply look at the graph below. Look for the island you are currently on, check which island you need to get to, and just use the methods that are available, or write some new ones.
While there were several more strategies that Raymond wanted to discuss, he doesn’t make it to the end of his list of strategies as he spend to much time on the first, chunking bit. Super curious as to the rest? Contact Raymond on Twitter.
Ever wondered what it is like to program computer games?
Or even better, what it is like to program programs that program your computer games for you? Then welcome to the wonderful world of procedural game design, such as Spore, Borderlands, and No Man’s Sky.
Recently, I have been watching and greatly enjoying this Youtube playlist of the South-African Sebastian Lague. In a series of nine videos, Sebastian programs a procedural cave generator from scratch. The program generates a pseudo-random cave, following some sensible constraints, everytime its triggered.
The following is Sebastian’s first video in the series labeled: Learn how to create procedurally generated caverns/dungeons for your games using cellular automata and marching squares.
More in line with my blog’s main topics, Sebastian also hosts a series on neural networks, which I will most probably watch and report on over the course of the coming weeks:
Past days, I discovered this series of blogs on how to win the classic game of Battleships (gameplay explanation) using different algorithmic approaches. I thought they might amuse you as well : )
The story starts with this 2012 Datagenetics blog where Nick Berry constrasts four algorithms’ performance in the game of Battleships. The resulting levels of artificial intelligence (AI) seem to compare respectively to a distracted baby, two sensible adults, and a mathematical progidy.
The first, stupidest approach is to just take Random shots. The AI resulting from such an algorithm would just pick a random tile to shoot at each turn. Nick simulated 100 million games with this random apporach and computed that the algorithm would require 96 turns to win 50% of games, given that it would not be defeated before that time. At best, the expertise level of this AI would be comparable to that of a distracted baby. Basically, it would lose from the average toddler, given that the toddler would survive the boredom of playing such a stupid AI.
A first major improvement results in what is dubbed the Hunt algorithm. This improved algorithm includes an instruction to explore nearby spaces whenever a prior shot hit. Every human who has every played Battleships will do this intuitively. A great improvement indeed as Nick’s simulations demonstrated that this Hunt algorithm completes 50% of games within ~65 turns, as long as it is not defeated beforehand. Your little toddler nephew will certainly lose, and you might experience some difficulty as well from time to time.
A visual representation of the “Hunting” of the algorithm on a hit [via]
Another minor improvement comes from adding the so-called Parity principle to this Hunt algorithm (i.e., Nick’s Hunt + Parity algorithm). This principle instructs the algorithm to take into account that ships will always cover odd as well as even numbered tiles on the board. This information can be taken into account to provide for some more sensible shooting options. For instance, in the below visual, you should avoid shooting the upper left white tile when you have already shot its blue neighbors. You might have intuitively applied this tactic yourself in the past, shooting tiles in a “checkboard” formation. With the parity principle incorporated, the median completion rate of our algorithm improves to ~62 turns, Nick’s simulations showed.
Now, Nick’s final proposed algorithm is much more computationally intensive. It makes use of Probability Density Functions. At the start of every turn, it works out all possible locations that every remaining ship could fit in. As you can imagine, many different combinations are possible with five ships. These different combinations are all added up, and every tile on the board is thus assigned a probability that it includes a ship part, based on the tiles that are already uncovered.
Computing the probability that a tile contains a ship based on all possible board layouts [via]
At the start of the game, no tiles are uncovered, so all spaces will have about the same likelihood to contain a ship. However, as more and more shots are fired, some locations become less likely, some become impossible, and some become near certain to contain a ship. For instance, the below visual reflects seven misses by the X’s and the darker tiles which thus have a relatively high probability of containing a ship part.
An example distribution with seven misses on the grid. [via]
Nick simulated 100 million games of Battleship for this probabilistic apporach as well as the prior algorithms. The below graph summarizes the results, and highlight that this new probabilistic algorithm greatly outperforms the simpler approaches. It completes 50% of games within ~42 turns! This algorithm will have you crying at the boardgame table.
Relative performance of the algorithms in the Datagenetics blog, where “New Algorithm” refers to the probabilistic approach and “No Parity” refers to the original “Hunt” approach.
Reddit user /u/DataSnaek reworked this probablistic algorithm in Python and turned its inner calculations into a neat GIF. Below, on the left, you see the probability of each square containing a ship part. The brighter the color (white <- yellow <- red <- black), the more likely a ship resides at that location. It takes into account that ships occupy multiple consecutive spots. On the right, every turn the algorithm shoots the space with the highest probability. Blue is unknown, misses are in red, sunk ships in brownish, hit “unsunk” ships in light blue (sorry, I am terribly color blind).
The probability matrix as a heatmap for every square after each move in the game. [via]
This latter attempt by DataSnaek was inspired by Jonathan Landy‘s attempt to train a reinforcement learning (RL) algorithm to win at Battleships. Although the associated GitHub repository doesn’t go into much detail, the approach is elaborately explained in this blog. However, it seems that this specific code concerns the training of a neural network to perform well on a very small Battleships board, seemingly containing only a single ship of size 3 on a board with only a single row of 10 tiles.
Fortunately, Sue He wrote about her reinforcement learning approach to Battleships in 2017. Building on the open source phoenix-battleship project, she created a Battleship app on Heroku, and asked co-workers to play. This produced data on 83 real, two-person games, showing, for instance, that Sue’s coworkers often tried to hide their size 2 ships in the corners of the Battleships board.
Probability heatmaps of ship placement in Sue He’s reinforcement learning Battleships project [via]
Next, Sue scripted a reinforcement learning agent in PyTorch to train and learn where to shoot effectively on the 10 by 10 board. It became effective quite quickly, requiring only 52 turns (on average over the past 25 games) to win, after training for only a couple hundreds games.
The performance of the RL agent at Battleships during the training process [via]
However, as Sue herself notes in her blog, disappointly, this RL agent still does not outperform the probabilistic approach presented earlier in this current blog.
Reddit user /u/christawful faced similar issues. Christ (I presume he is called) trained a convolutional neural network (CNN) with the below architecture on a dataset of Battleships boards. Based on the current board state (10 tiles * 10 tiles * 3 options [miss/hit/unknown]) as input data, the intermediate convolutional layers result in a final output layer containing 100 values (10 * 10) depicting the probabilities for each tile to result in a hit. Again, the algorithm can simply shoot the tile with the highest probability.
Christ’s convolutional neural network architecture for Battleships [via]
Christ was nice enough to include GIFs of the process as well [via]. The first GIF shows the current state of the board as it is input in the CNN — purple represents unknown tiles, black a hit, and white a miss (i.e., sea). The next GIF represent the calculated probabilities for each tile to contain a ship part — the darker the color the more likely it contains a ship. Finally, the third picture reflects the actual board, with ship pieces in black and sea (i.e., miss) as white.
As cool as this novel approach was, Chris ran into the same issue as Sue, his approach did not perform better than the purely probablistic one. The below graph demonstrates that while Christ’s CNN (“My Algorithm”) performed quite well — finishing a simulated 9000 games in a median of 52 turns — it did not outperform the original probabilistic approach of Nick Berry — which came in at 42 turns. Nevertheless, Chris claims to have programmed this CNN in a couple of hours, so very well done still.
The performance of Christ’s Battleship CNN compared to Nick Berry’s original algorithms [via]
Interested by all the above, I searched the web quite a while for any potential improvement or other algorithmic approaches. Unfortunately, in vain, as I did not find a better attempt than that early 2012 Datagenics probability algorithm by Nick.
Surely, with today’s mass cloud computing power, someone must be able to train a deep reinforcement learner to become the Battleship master? It’s not all probability right, there must be some patterns in generic playing styles, like Sue found among her colleagues. Or maybe even the ability of an algorithm to adapt to the opponent’s playin style, as we see in Libratus, the poker AI. Maybe the guys at AlphaGo could give it a shot?
For starters, Christ’s provided some interesting improvements on his CNN approach. Moreover, while the probabilistic approach seems the best performing, it might not the most computationally efficient. All in all, I am curious to see whether this story will continue.
Last year, inspired by a tweet from Ilya Kashnitsky, I wrote a snow animation which you can read all about here.
Now, this year, the old code no longer worked due to an update to the gganimate API. Hence, I was about to only refactor the code, but decided to give the whole thing a minor update. Below, you find the 2.0 version of my R snow animation.
# CUSTOM FUNCTIONS #### map_to_range <- function(x, from, to) { # Shifting the vector so that min(x) == 0 x <- x - min(x) # Scaling to the range of [0, 1] x <- x / max(x) # Scaling to the needed amplitude x <- x * (to - from) # Shifting to the needed level x + from }
# CONSTANTS #### N <- 500 # number of flakes TIMES <- 100 # number of loops XPOS_DELTA <- 0.01 YSPEED_MIN = 0.005 YSPEED_MAX = 0.03 FLAKE_SIZE_COINFLIP = 5 FLAKE_SIZE_COINFLIP_PROB = 0.1 FLAKE_SIZE_MIN = 4 FLAKE_SIZE_MAX = 20
JS13K Games is a competition where developers are challenged to create an entire game using less than 13 kilobytes of memory. Creative developer Matt Deslaudiers participated and created Bellwoods: an art game for mobile and desktop that you can play in your browser.
The concept of the game is simple: fly your kite through endless fields of colour and sound, trying to discover new worlds. To remain under 13kb, all of the graphics and audio in Bellwoods are procedurally generated. The game was mostly programmed in JavaScript with minimal custom HTML/CSS. Matt’s motivation and the actual development you can read about in his original blog. The source code the game, Matt also shared on GitHub.
Mélissa Hernandez, a French UX and Interaction Designer, helped Matt design this beautiful game. Together, they even versed a haiku that not only evokes the mood of the game, but also provides some subtle gameplay instructions:
over the tall grass following birds, chasing wind in search of color