Data visualizations that make smart use of icons have a way of conveying information that sticks. Dataviz professionals like Moritz Stefaner know this and use the practice in their daily work.
A recent #tidytuesday entry by Georgios Karamanis demonstrates how easy it is to integrate visual icons in your data figures when you write code in R. You can simply store the URL location of an icon as a data column, and map it to an aesthetic using the ggplot2::geom_image function.
Do have a closer look at Georgios’ github repository for week 21 of tidytuesday. You will probably have to alter the code a bit to get it to work. though!
For those who haven’t moved away from base R plotting functions yet, here’s a good StackOverflow item showing how to use icons in both base R and tidyverse.
Hugo Toscano wrote a great blog providing an overview of all the helpful functionalities of the R forcats package. The package includes functions that help handling categorical data, by setting a random or fixed order, and by recategorizing or anonymizing. These functions are specifically helpful when visualizing data with R’s ggplot2.
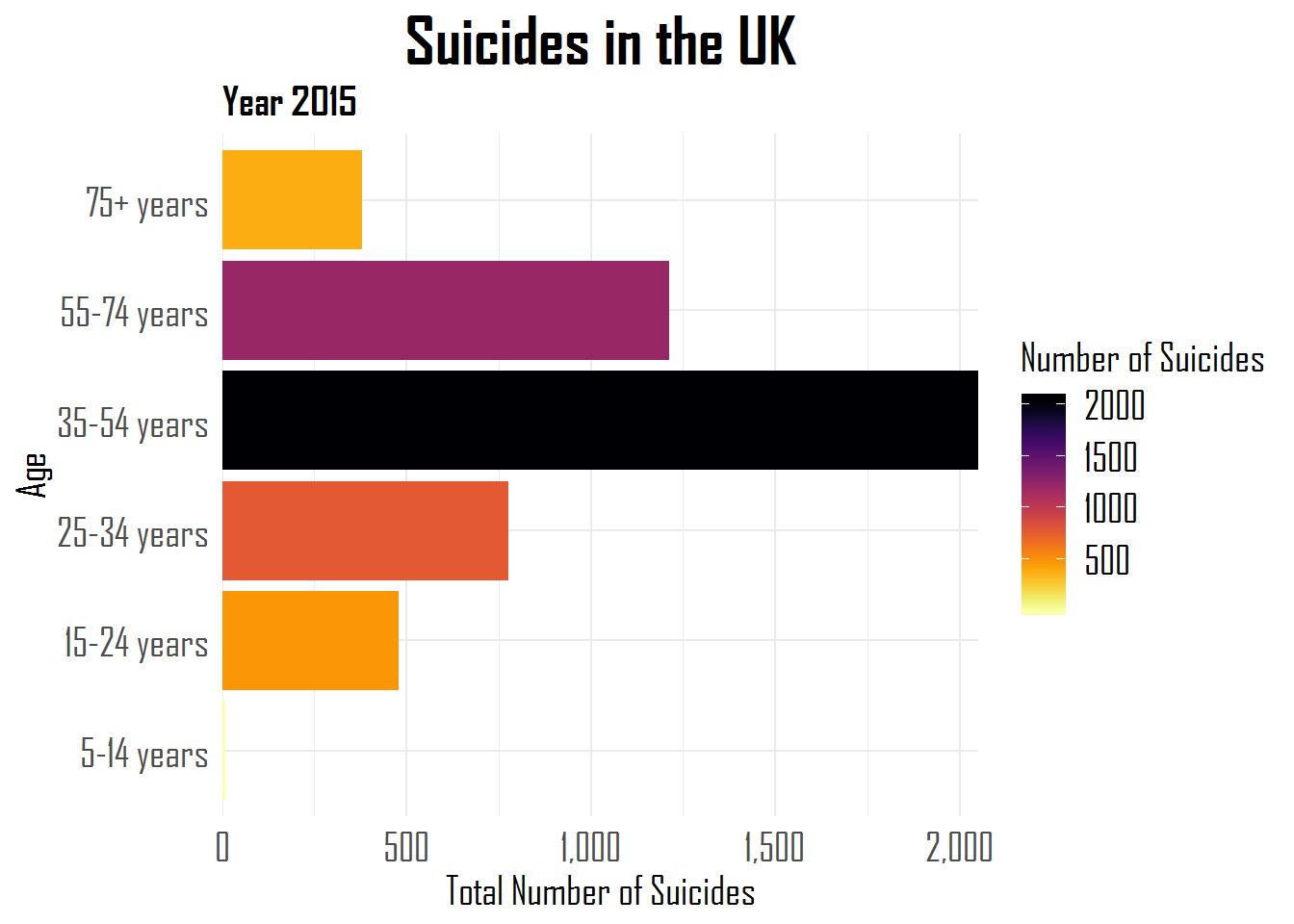
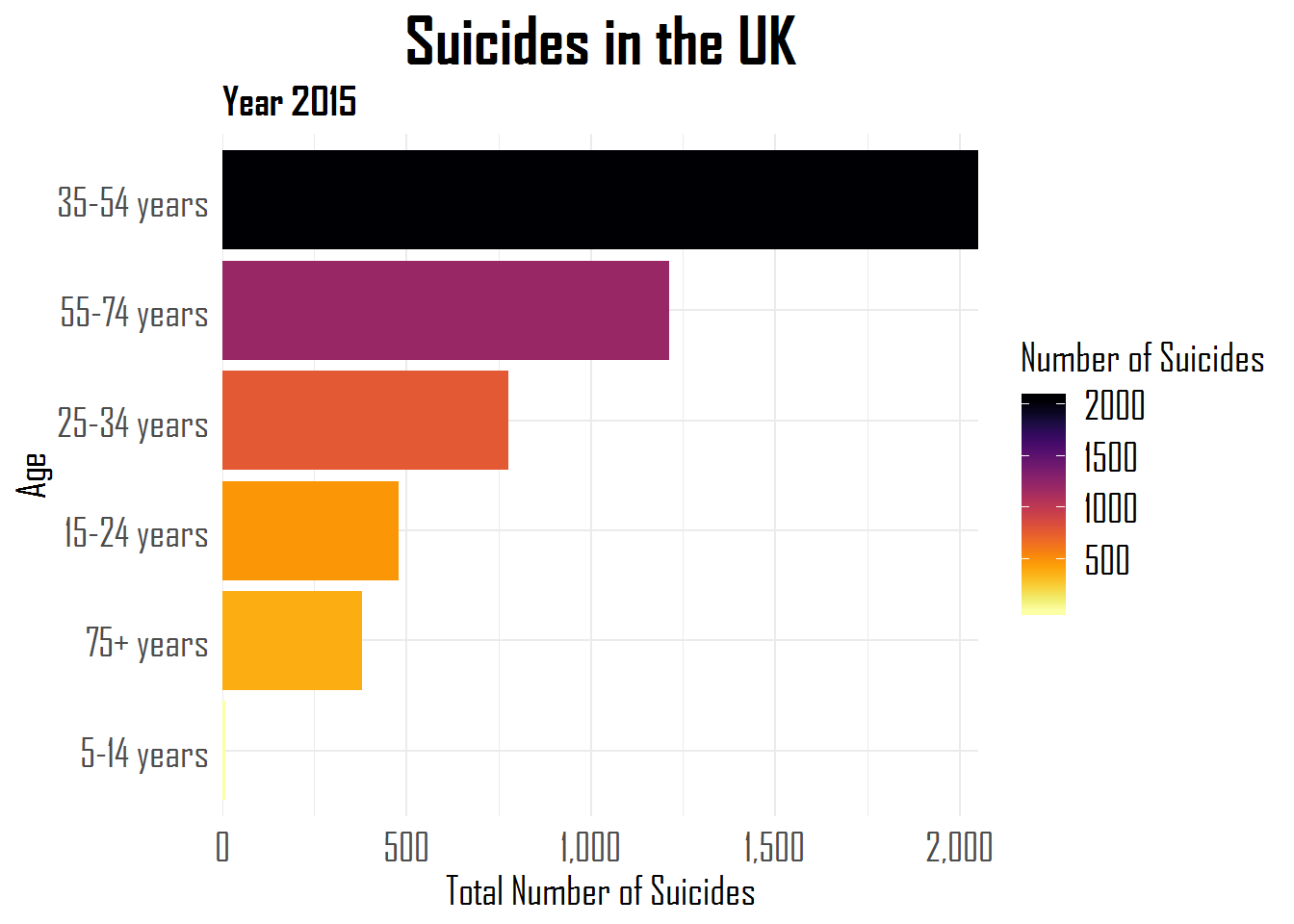
A comprehensive overview is provided in the form of the RStudio forcats cheat sheet, but, on his blog, Hugo demonstrates some of its functionalities using a dataset on suicides and people’s ages:
Other functions can be used to automatically surpress infrequent categories, to reverse the order of categories, to shuffle or shift categories, to quickly relabel or anonimize categories, and many more…
Propensity score matching (wiki) is a statistical matching technique that attempts to estimate the effect of a treatment (e.g., intervention) by accounting for the factors that predict whether an individual would be eligble for receiving the treatment. The wikipedia page provides a good example setting:
Say we are interested in the effects of smoking on health. Here, smoking would be considered the treatment, and the ‘treated’ are simply those who smoke. In order to find a cause-effect relationship, we would need to run an experiment and randomly assign people to smoking and non-smoking conditions. Of course such experiments would be unfeasible and/or unethical, as we can’t ask/force people to smoke when we suspect it may do harm. We will need to work with observational data instead. Here, we estimate the treatment effect by simply comparing health outcomes (e.g., rate of cancer) between those who smoked and did not smoke. However, this estimation would be biased by any factors that predict smoking (e.g., social economic status). Propensity score matching attempts to control for these differences (i.e., biases) by making the comparison groups (i.e., smoking and non-smoking) more comparable.
Lucy D’Agostino McGowan is a post-doc at Johns Hopkins Bloomberg School of Public Health and co-founder of R-Ladies Nashville. She wrote a very nice blog explaining what propensity score matching is and showing how to apply it to your dataset in R. Lucy demonstrates how you can use propensity scores to weight your observations in such a way that accounts for the factors that correlate with receiving a treatment. Moreover, her explainations are strenghtened by nice visuals that intuitively demonstrate what the weighting does to the “pseudo-populations” used to estimate the treatment effect.
Last year witnessed the creation of many novel types of data visualization. Some lesser known ones, jokingly referred to as xenographics, I already discussed.
Two new visualization formats seem to stick around though. And as always, it was not long before someone created special R packages for them. Get ready to meet waffleplots and swarmplots!
Waffleplot
Waffleplots — also called square pie charts — are very useful in communicating parts of a whole for categorical quantities. Bob Rudis (twitter) — scholar and R developer among many other things — did us all a favor and created the R waffle package.
First, we need to install and load the waffle package.
install.packages("waffle") # install waffle package
library(waffle) # load in package
I will use the famous iris data to demonstrate both plots.
Since waffleplots work with frequencies, I will specifically use the iris$Species data stored as a frequency table.
Here, we see every single flower in the iris dataset represented by a tile. This provides an immediate visual representation of the group sizes in the dataset. Looks pretty huh!
But we can play around with the display settings, for instance, let’s change the number of rows and the placement of the legend. Building on ggplot2, the waffle package works very intuitive:
waffle(spec, rows = 3, legend_pos = "bottom")
Or, in case we want to highlight a specific value, we could play around with the colors a bit.
The plot is a bit crowded though with each flower as a seperate tile. We can simply reduce the number of tiles by dividing the values in our frequency table, like so:
# do not forget to annotate what each square represents!
w1 <- waffle(spec / 10, rows = 5, xlab = "1 square = 10 flowers")
w1
Finally, you might want to combine multiple waffles into a single visual. This you can do with the accompanied well-named waffle::iron function. Like so:
I am definately going to use this package in my daily work. I just love the visual simplicity.
As a final remark, the waffle Github page argues that the argument use_glyph can be used to replace the tiles by pictures from the extrafont package, however, I could not get the code to work.
The visual resulting from the use_glyph waffle example via github.
The ggplot2 waffle extension geom_waffle is being developed as we speak, but is not yet hosted on CRAN yet.
Some examples hosted on the Github page also use the iris dataset, so you can have a look at those. However, I made novel visuals because I prefer theme_light. Hence, I first install the ggbeeswarm package along with ggplot2, and then set the default theme to theme_light.
As this is an “official” ggplot2 extension, most functionality works the same as in any other geom_*. Thus, adding colors or increasing point size is easy:
ggplot(iris, aes(Species, Sepal.Length, col = Species)) + geom_beeswarm(size = 2)
For larger sizes, you might want to adjust the spacing between the points using the cex argument.
Points in a beeswarmplot are automatically plotted side-by-side grouped on the X variable, but you can turn that off with the groupOnX command.
ggplot(iris, aes(Species, Sepal.Length, col = Species)) + geom_beeswarm(groupOnX = FALSE)
Finally, if you have another grouping variable besides those on the axis (e.g., a large Sepal.Length below), you might want to consider using the dodge.width argument to seperate the groups.
The second function in the ggbeeswarm package is geom_quasirandom, an alternative to the original geom_jitter. Basically, it’s a convenient tool to offset points within categories to reduce overplotting.
ggplot(iris, aes(Species, Sepal.Length, col = Species)) + geom_quasirandom()
Instead of the quasirandom offset, the geom allows for many other methods, including a smiley face pattern : )
There is also a earlier package on CRAN, called beeswarm, but it doesn’t seem to be maintained anymore. Moreover, its syntax more or less resembles R’s base::plot, whereas I have a strong preference for ggplot2 personally.
Katie Jolly wanted to surprise a friend with a nice geeky gift: a custom-made map cutout. Using R and some visual finetuning in Inkscape, she was able to made the below.
A detailed write-up of how Katie got to this product is posted here.
Basically, the R’s tigris package included all data on roads, and the ArcGIS Open Data Hub provided the neighborhood boundaries. Fortunately, the sf package is great for transforming and manipulating geospatial data, and includes some functions to retrieve a subset of roads based on their distance to a centroid. With this subset, Katie could then build these wonderful plots in no time with ggplot2.
Yesterday was the second anniversary of my website. I also reflected on this moment last year, and I thought to continue the tradition in 2019.
Let me start with a great, big THANK YOU to all my readers for continuing to visit my website!
You are the reason I continue to write down what I read. And maybe even the reason I continued reading and learning last year, despite all other distractions [my “real” job and my PhD : )].
Also a big thank you to all my followers on Twitter and LinkedIn, and those who have taken the time to comment or like my blogs. All of you make that I gain energy from writing this blog!
With that said, let’s start the review of the past year on my blog.
Most popular blog posts of 2018
Most importantly, let’s examine what you guys liked. Which blogs attracted the most visitors? What did you guys read?
Unfortunately, WordPress does not allow you to scrape their statistics pages. However, I was able to download monthly data manually, which I could then visualize to show you some trends.
The visual below shows the cumulative amount of visitors attracted by each blog I’ve written in 2018. Here follow links to the top 8 blogs in terms of visitor numbers this year:
rstudio::conf 2018 summary received 1514 views. It provides links to the most salient talks and presentations of the yearly R gathering.
R tips & tricks is relatively new and has only yet received 1212 views. Seperate from the R resources guide, this new list contains all the quick tricks that help you program more effectively in R.
Super Resolution: A Photo Enhancer AI received 891 views and elaborates on the development of new tools that can upgrade photo and video data quality.
Where there’s success, there’s failure. Some of my posts did not get a lot of attention by my readership. That’s unfortunate, as I really only take the time to blog about the stuff that I deem interesting enough. Were these failed blog posts just unlucky, or am I biased and were they simply really bad and uninteresting?
You be the judge! Here are some of the least read posts of 2018:
Now, let’s move to some general statistics: in 2018, paulvanderlaken.com received 85.614 views, by 57.594 unique visitors. I posted 61 new blogs, consisting of a total of 31.598 words. Fifty-one visitors liked one of my posts, and 24 visitors took the time to post a comment of their own (my replies included, probably).
Compared to last year, my website did pretty well!
2017
2018
Δ
Views
38490
85614
122%
Unique visitors
26949
57594
114%
Posts
100
61
-39%
Words / post
625
518
-17%
Likes
35
51
46%
Comments
99
24
-76%
However, the above statistics do not properly reflect the development of my website. For instance, I only really started generating traffic after my first viral post (i.e., Harry Plotter). The below graph takes that into account and better reflects the development of the traffic to my website.
The upward trend in traffic looks promising!
All time favorites
Looking back to the start of paulvanderlaken.com, let’s also examine which blogs have been performing well ever since their conception.
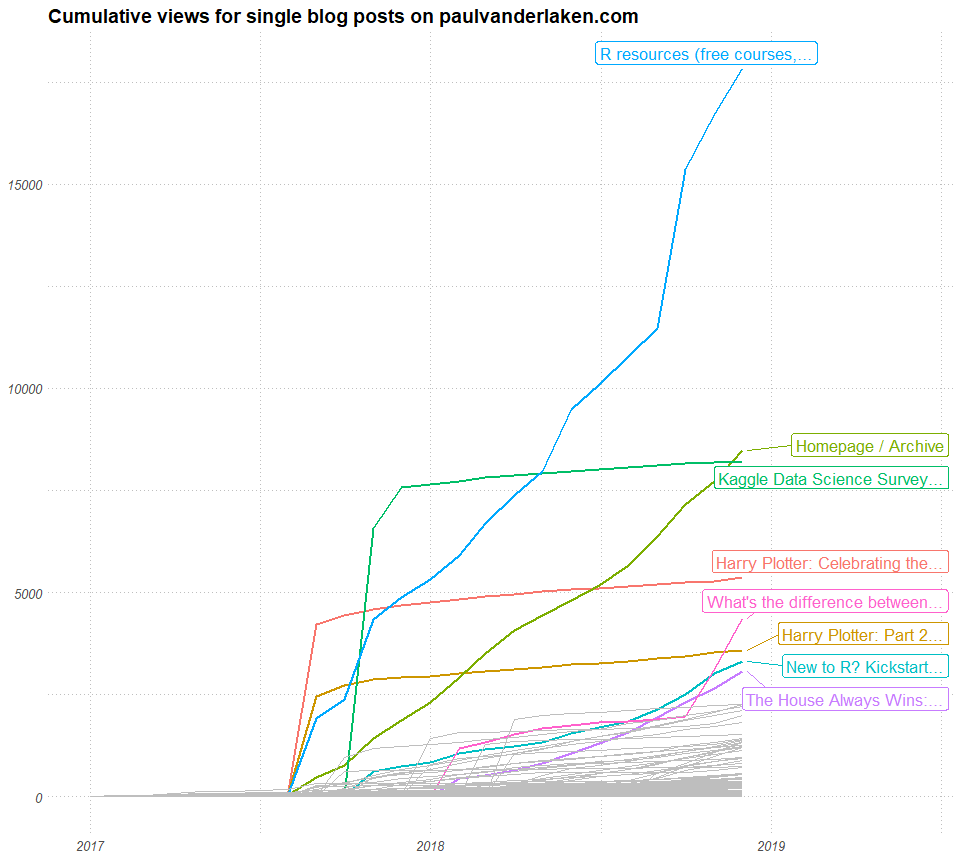
Clearly, most people have been coming for the R resources overview, as demonstrated by the visual below. Moreover, the majority of blog posts has not been visited much — only a handful ever cross the 1000 views mark.
Finally , let’s have a closer look as to what brought people to my website.The below visualizes the main domains that redirected visitors.
Search engines provided the majority of traffic in both 2017 and 2018 – mainly Google; to a lesser extent, DuckDuckGo and Bing (who in his right mind uses Norton Safe Search?!). My Twitter visitors increased in 2018 as compared to 2017, as did my traffic from this specific Quora page.
And that concludes my two year anniversary of paulvanderlaken.com review. I hope you enjoyed it, and that you will return to my website for the many more years to come : )
I end with a big shout out to my most loyal readers! 104 people have subscribed to my website (as of 2019-01-22) and receive an update wherener I post a new blog.
Thank you for your continued support!
Want to join this group of elite followers? Press the Follow button in the right toolbar, or at the bottom of this blog post.