Tensorflow is a open-source machine learning (ML) framework. It’s primarily used to build neural networks, and thus very often used to conduct so-called deep learning through multi-layered neural nets.
Although there are other ML frameworks — such as Caffe or Torch — Tensorflow is particularly famous because it was developed by researchers of Google’s Brain Lab. There are widespread debates on which framework is best, nonetheless, Tensorflow does a pretty good job on marketing itself.
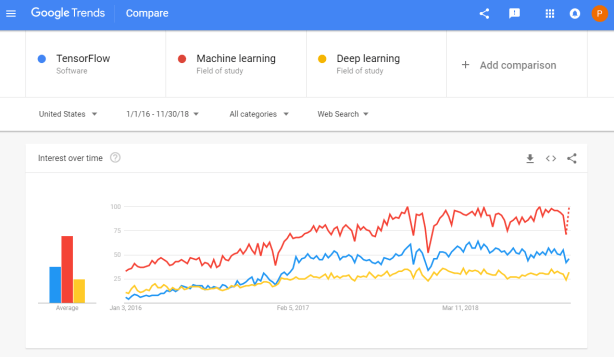
Google search engine searches on Tensorflow in comparison to searches on Machine learing and Deep learning
The field of computer vision tries to replicate our human visual capabilities, allowing computers to perceive their environment in a same way as you and I do. The recent breakthroughs in this field are super exciting and I couldn’t but share them with you.
In the TED talk below by Joseph Redmon (PhD at the University of Washington) showcases the latest progressions in computer vision resulting, among others, from his open-source research on Darknet – neural network applications in C. Most impressive is the insane speed with which contemporary algorithms are able to classify objects. Joseph demonstrates this by detecting all kinds of random stuff practically in real-time on his phone! Moreover, you’ve got to love how well the system works: even the ties worn in the audience are classified correctly!
The second talk, below, is more scientific and maybe even a bit dry at the start. Blaise Aguera y Arcas (engineer at Google) starts with a historic overview brain research but, fortunately, this serves a cause, as ~6 minutes in Blaise provides one of the best explanations I have yet heard of how a neural network processes images and learns to perceive and classify the underlying patterns. Blaise continues with a similarly great explanation of how this process can be reversed to generate weird, Asher-like images, one could consider creative art:
An example of a reversed neural network thus “estimating” an image of a bird [via Youtube]Blaise’s colleagues at Google took this a step further and used t-SNE to visualize the continuous space of animal concepts as perceived by their neural network, here a zoomed in part on the Armadillo part of the map, apparently closely located to fish, salamanders, and monkeys?
A zoomed view of part of a t-SNE map of latent animal concepts generated by reversing a neural network [via Youtube]We’ve seen these latent spaces/continua before. This example Andrej Karpathy shared immediately comes to mind:
If you want to learn more about this process of image synthesis through deep learning, I can recommend the scientific papers discussed by one of my favorite Youtube-channels, Two-Minute Papers. Karoly’s videos, such as the ones below, discuss many of the latest developments:
Let me know if you have any other video’s, papers, or materials you think are worthwhile!
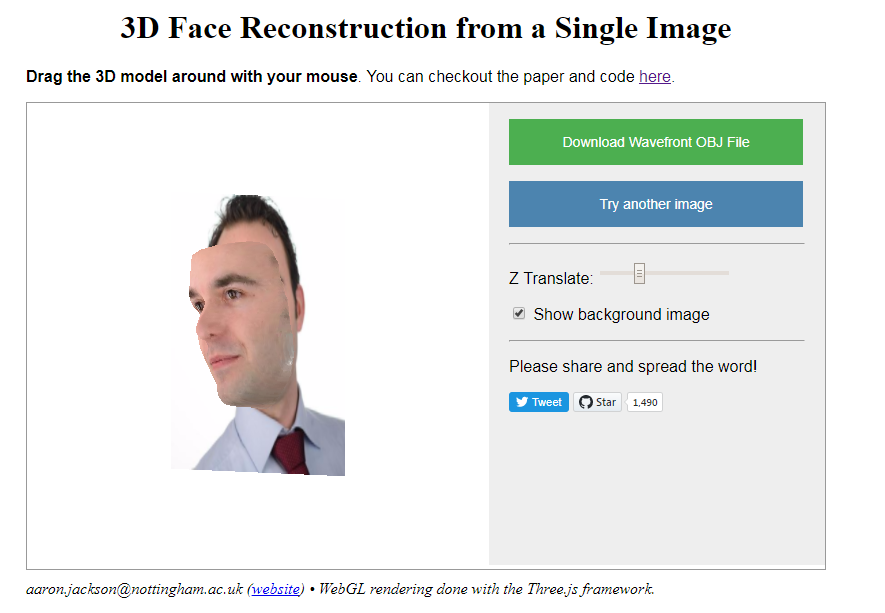
Aaron Jackson, Adrian Bulat, Vasileios Argyriou and Georgios Tzimiropoulos
of the Computer Vision Laboratory of the University of Nottingham built a neural network that generates a full 3D image of a single portrait photograph. They turn a photograph like this…
… into an accurately creepy 3D image like this.
You can try it with your own or other photographs here. I found that images with white background get the best results. On their project website you can read more about the underlying convolutional neural network.
Update 21-10-2017: One of my favorite YouTube channels explains how the models were trained and the data used: